When I presented “Choosing Between Import Mode, Direct Lake, and Composite Models” at Fabric Conf 2025 in Las Vegas, the room overflowed, and the session was not recorded. I promised to publish the material once the new Direct Lake + Import composite model became available. This post follows the structure of that (now re‑recorded) session.
I prepared a recap for this blog post, but I suggest you watch the full video!
1 · Quick reference – storage mode cheat‑sheet
| Mode | Data lives where? | Refresh cost | Feature limits | Typical fit |
|---|---|---|---|---|
| Import | Vertipaq in the semantic model | Full (or incremental) data copy & compression | None | Small–medium models; highly flexible dimensions |
| Direct Lake | Parquet/Delta tables in Fabric Lakehouse/Warehouse | Metadata “re‑framing”; data transcoded on query | No Power Query; no calc columns/tables (yet); Excel hierarchies limited | Very large fact tables that rarely need schema tweaks |
| Direct Lake + Import | Both (table‑by‑table) | Import tables refresh; Direct Lake tables reframing | Import‑table features available; Direct Lake limits remain | Mixed workloads—big facts, tweakable dims |
Use this as a decoder ring for the sections that follow.
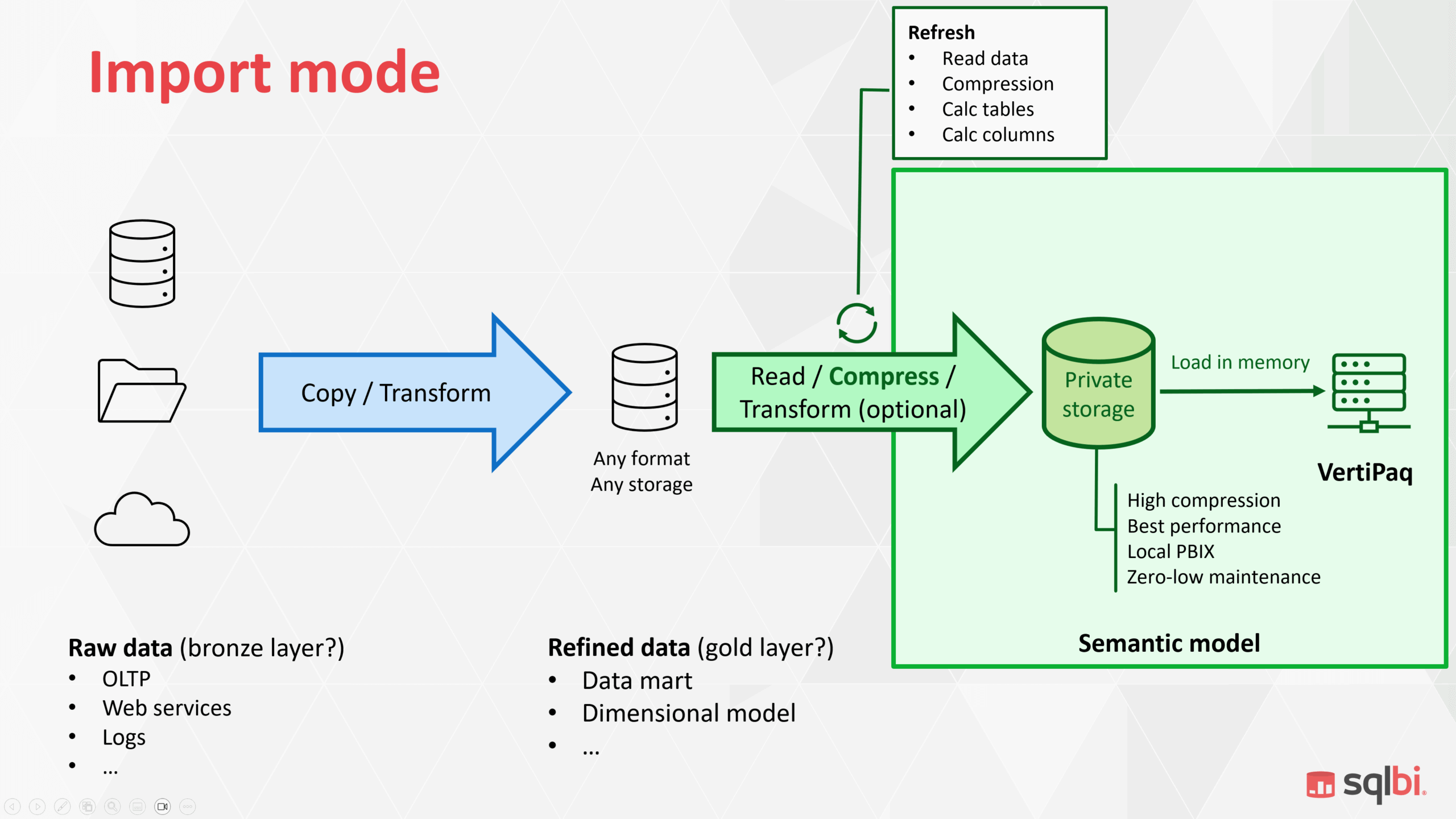
2 · Import mode (the baseline)
Architecture in 60 seconds
Data is copied from source → transformed → compressed into Vertipaq. Vertipaq’s columnar format gives the highest compression and query speed, with near‑zero maintenance when you can afford full refreshes.
Pros
- Best raw query performance (no transcoding at runtime).
- All modeling features available—Power Query, calculated columns/tables, user hierarchies, drill‑through, etc.
- Simple mental model: “it just works.”
Cons
- Refresh time scales with data volume; full refreshes on >100 M‑row facts are painful.
- Requires duplicate storage (source + Vertipaq copy).
- Developers can become addicted to calc columns where a proper data‑engineering fix might be cleaner.
Take‑away: Import remains the gold standard—until refresh windows or storage duplication bite.
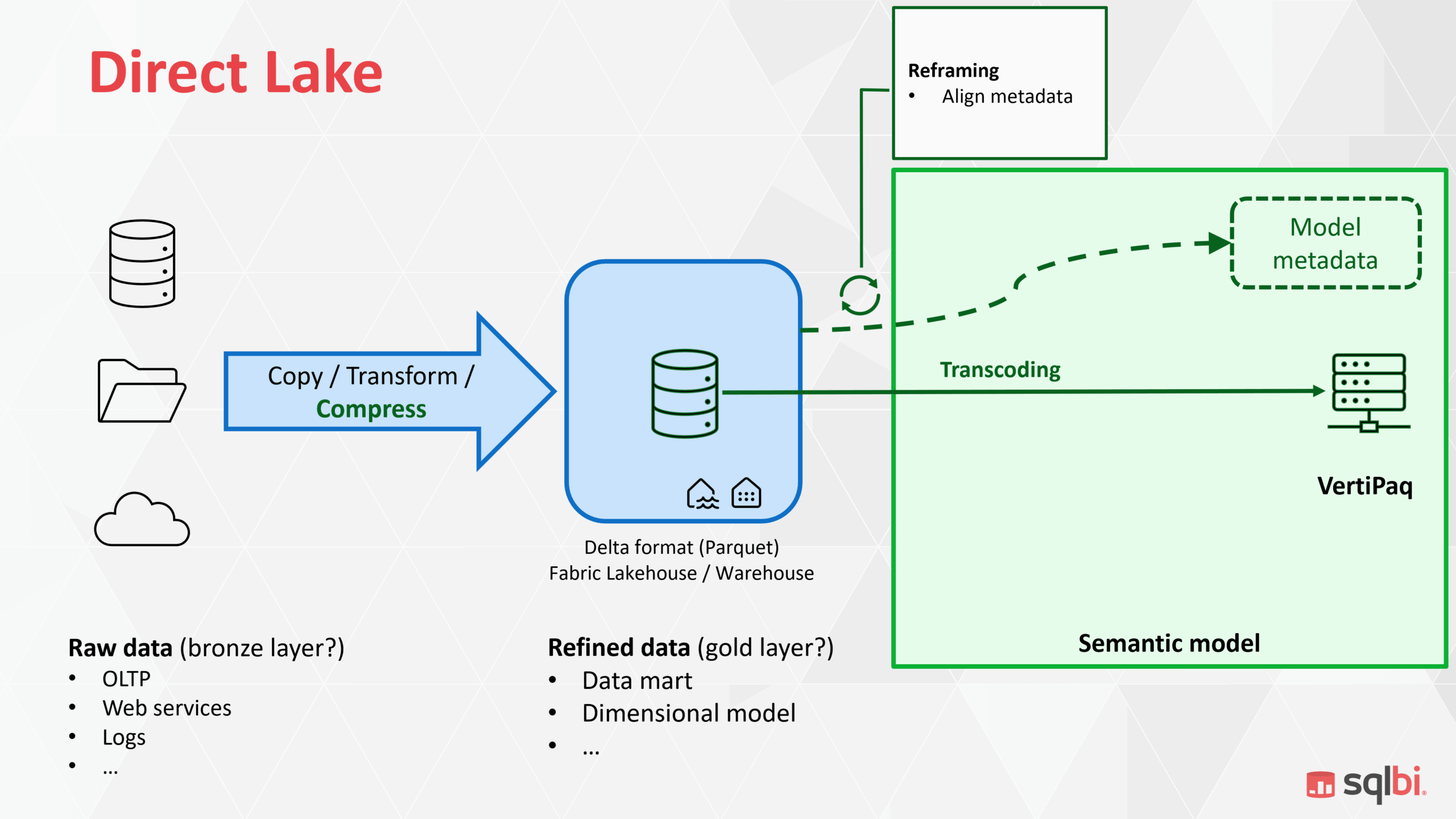
3 · Direct Lake – what really changes
Direct Lake skips the Vertipaq copy and leaves data compressed in Parquet/Delta. When a query hits, data is transcoded into Vertipaq on demand.
Costs move:
- Data‑engineering pipeline must produce well‑compressed Parquet (good clustering, no tiny files, etc.).
- Query latency includes transcoding the first time a column is touched.
Limitations worth noting (May 2025 preview)
- No Power Query transforms.
- No calc columns/tables (road‑map says calc tables arrive first).
- Excel: no user‑defined hierarchies; drill‑through disabled.
Take-away: For massive facts that refresh often, those trade‑offs can be worth it; for shapeshifting dimensions, not so much.
4 · Two flavours of Direct Lake
| Flavour | Connect option | Fallback if memory low | Security path | Status |
|---|---|---|---|---|
| Direct Lake on OneLake | Connect to OneLake | None (error) | OneLake security (future‑proof) | Becoming default |
| Direct Lake via SQL Endpoint | Connect via SQL endpoint | Falls back to Direct Query (SQL) | SQL security | Legacy; kept for edge cases |
Practical tip: use the OneLake flavour unless you have a hard requirement for SQL‑endpoint security or Direct Query fallback.
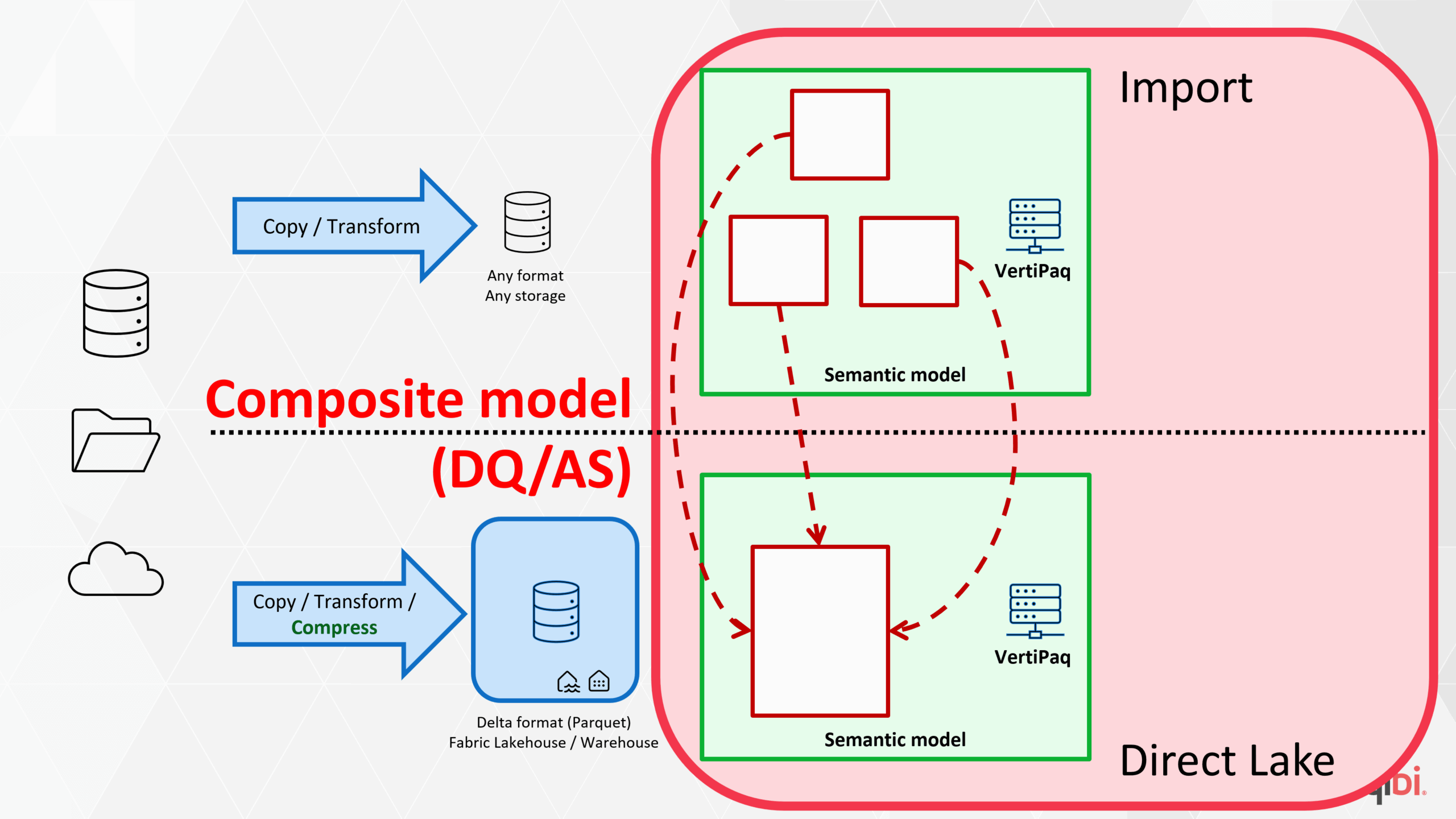
5 · Why classic composite models stumble
The older Import + Direct Lake composite pattern glued two separate semantic models together. Relationships that cross the model boundary:
- Carry extra filter lists in the query plan.
- Break “blank‐row propagation.”
- Slow down drastically when the crossing key has medium/high cardinality.
Short version: fine for demo‑sized dimensions, brittle for real ones.
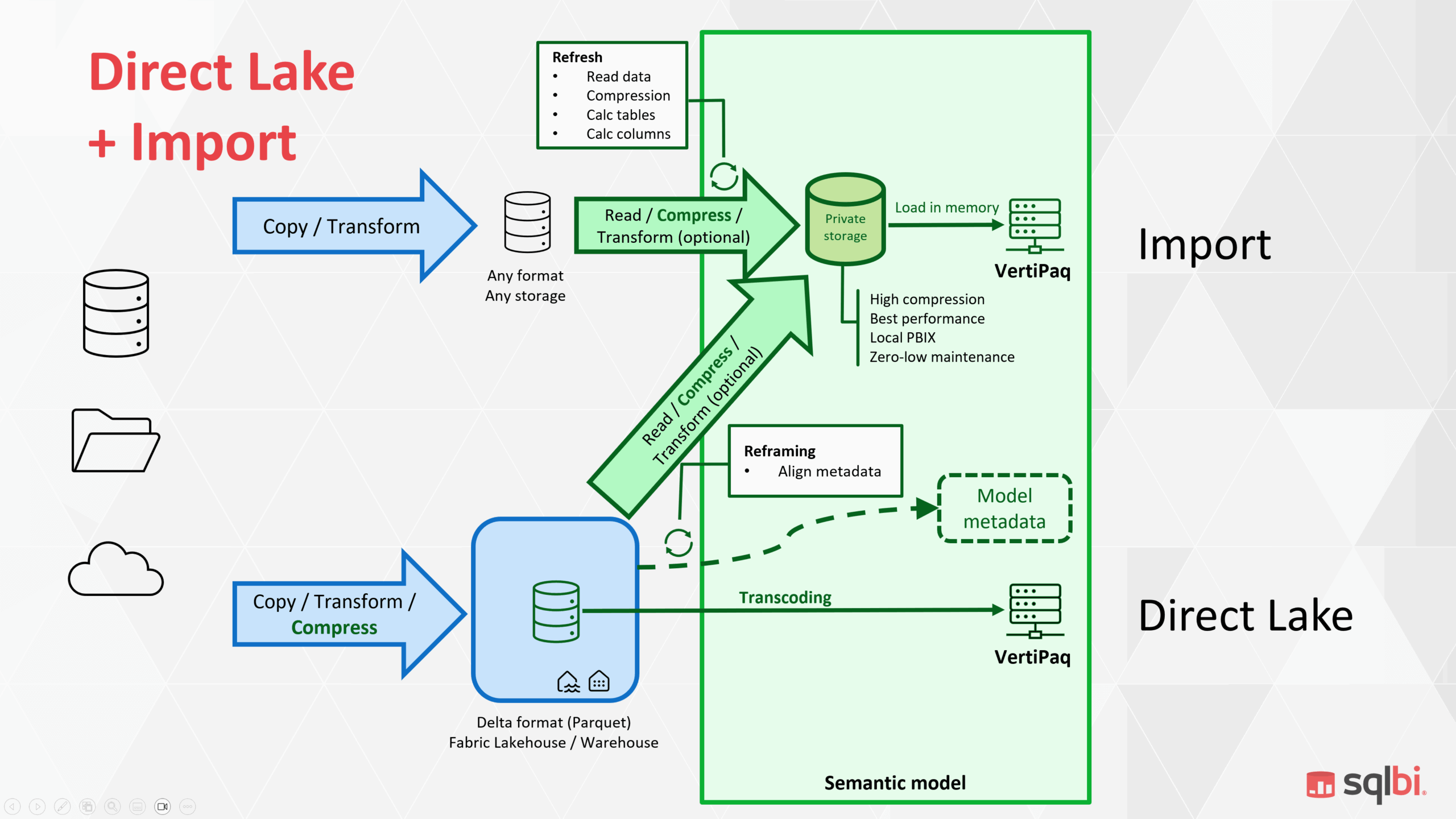
6 · Direct Lake + Import – how it works
The new composite model lets you flag each table as Import or Direct Lake inside one semantic model. Internally, Vertipaq treats everything as a single “continent,” so relationships are regular and fast.
Workflow snapshot
- Start a Direct Lake model (OneLake flavour).
- Paste or create Import tables (via Tabular Editor 2/3 or soon in‑product).
- Map credentials so the service can refresh Import tables.
- Build normal relationships; refresh once.
Result: big fact in Direct Lake, nimble dimensions in Import—no model‑boundary tax.
What is still preview‑grade?
- GUI support is patchy; Tabular Editor is the path of least resistance for now.
- First refresh sometimes stalls until data‑source credentials propagate—wait a minute, then retry.
7 · Step‑by‑step demo recap
Below is the high‑level flow I followed in the video. Adapt the data sources and naming to your environment.
- Direct Lake stub
- Connect to OneLake → pick Sales only → publish.
- Add core measures (they reference only Sales).
- Bring in Import dimensions
- Open Import‑only model built via SQL endpoint.
- Copy Product, Customer, Date, Store tables into the Direct Lake model with Tabular Editor.
- Save changes.
- Credential mapping
- In the service, create a connection (“Contoso–DL”) with OAuth credentials.
- Map the SQL endpoint to that connection.
- Wait until credentials propagate.
- First full refresh. Data is imported for dimensions, no waiting for the Sales table.
- Create regular relationships between Sales and dimension keys. Save + quick metadata refresh.
- Test query – a DAX matrix using
Product[Price Range](calc column) plusSales Amountaggregated from the fact.- Server timings show one Storage Engine query—no boundary crossing.
8 · When to choose which mode
| Scenario | Recommended mode(s) | Rationale |
|---|---|---|
| Dimension needs frequent ad‑hoc columns / Power Query shaping | Import | Flexibility trumps minimal storage gain. |
| Only large tables > 50 M rows / frequent changes (more than hourly) | Direct Lake | Avoid massive re‑imports; minor transcoding cost. |
| Mixed: large fact tables, reshaping dimensions | Direct Lake + Import | Best of both, single‑model performance. |
| BI team lacks Tabular Editor skills & can tolerate slower refresh | Import | Simpler until GUI improves. |
| Strict SQL‑level security & fallback required | Direct Lake via SQL endpoint | Edge case; accept extra complexity. |
9 · Open questions & preview caveats
- Calc tables/columns in Direct Lake – calc tables are on the near roadmap; calc columns later.
- Materialised views – promised to bridge small dimension tweaks without import; still early days.
- GUI support – expect OneLake‑first enhancements in Desktop and web editor.
- Compression quality – pay attention to file sizes and clustering in the Lakehouse; Vertipaq cannot save you at query time.
10 · Key take‑aways
- Import is not dead; it is still the reference point for performance and flexibility.
- Direct Lake removes refresh drag for huge facts but shifts the burden to data engineering.
- Classic composite models are fine for toy demos combining Direct Lake and Import mode—sluggish for anything with real cardinality.
- Direct Lake + Import (preview) finally lets us split the model sensibly: big facts stay in place, dimensions come in ready to morph.
- Today, setup needs Tabular Editor and patience; by GA the toolchain should be smoother.
DISCLAIMER: The content of this blog post is based on a heavily-reviewed, AI-generated recap of the 95-minute video content that I recorded. We strive to be transparent when leveraging AI as promised in this piece: Generative AI guidelines at SQLBI.