 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariIn a previous article, we introduced the horizontal fusion optimization, which reduces the number of storage engine requests when different measures compute the same aggregation with different filters. We suggest you start by reading that article to understand how horizontal fusion works.
This optimization technique is helpful as a first step in performance optimization that does not require any change to the existing code. However, we observed many models where a measure references other measures that reference other measures… And many of the calculations are similar aggregations over the same columns with different filters. When this happens, there is an additional level of optimization possible that reduces the materialization from the storage engine and can provide better query performance. However, this level of optimization requires changes to the DAX code that might also increase the maintenance cost of the solution over time. Thus, you should evaluate whether this additional optimization is truly needed in your model before modifying an existing solution.
Detecting multiple measure references sharing the same aggregation
Consider a common, generic measure like Sales Amount:
Sales Amount := SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
A model could have several, more specialized measures that apply specific filters to the existing Sales Amount measure:
Sales Contoso :=
CALCULATE (
[Sales Amount],
KEEPFILTERS ( 'Product'[Brand] = "Contoso" )
)
Sales Fabrikam :=
CALCULATE (
[Sales Amount],
KEEPFILTERS ( 'Product'[Brand] = "Fabrikam" )
)
Sales Litware :=
CALCULATE (
[Sales Amount],
KEEPFILTERS ( 'Product'[Brand] = "Litware" )
)
So far, so good. If you create a report that references one or more of the measures defined so far, the horizontal fusion optimizes the number of storage engine queries. However, consider a new Sales Fancy Brands measure that sums Sales Contoso, Sales Fabrikam, and Sales Litware:
Sales Fancy Brands := [Sales Contoso] + [Sales Fabrikam] + [Sales Litware]
A report that only consumes Sales Fancy Brands gets the fusion optimization of the three measures referenced internally. Still, this is not the best performance we can obtain for this calculation.
Analyzing the horizontal fusion optimization
When a similar expression is evaluated in a different filter context, the horizontal fusion optimization simplifies the execution by executing a single query. We can test the execution of a report that groups only the Sales Fancy Brands measure in a report grouped by Product[Color]:
DEFINE
MEASURE Sales[Sales Fancy Brands] =
[Sales Contoso] + [Sales Fabrikam] + [Sales Litware]
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Color],
"Sales Fancy Brands", [Sales Fancy Brands]
)
We execute the tests on a model with 225M rows in the Sales table – the sample file you can download below the article is a smaller version with just 13,915 rows in Sales. The query returns the result of Sales Fancy Brands for each value in Product[Color].
Each of the three measures referenced in Sales Fancy Brands requires scanning Sales with a different filter over the Product[Brand] column. We know that horizontal fusion kicks in and merges the different scans. Indeed, looking at the Server Timings pane, there is only one storage engine query.
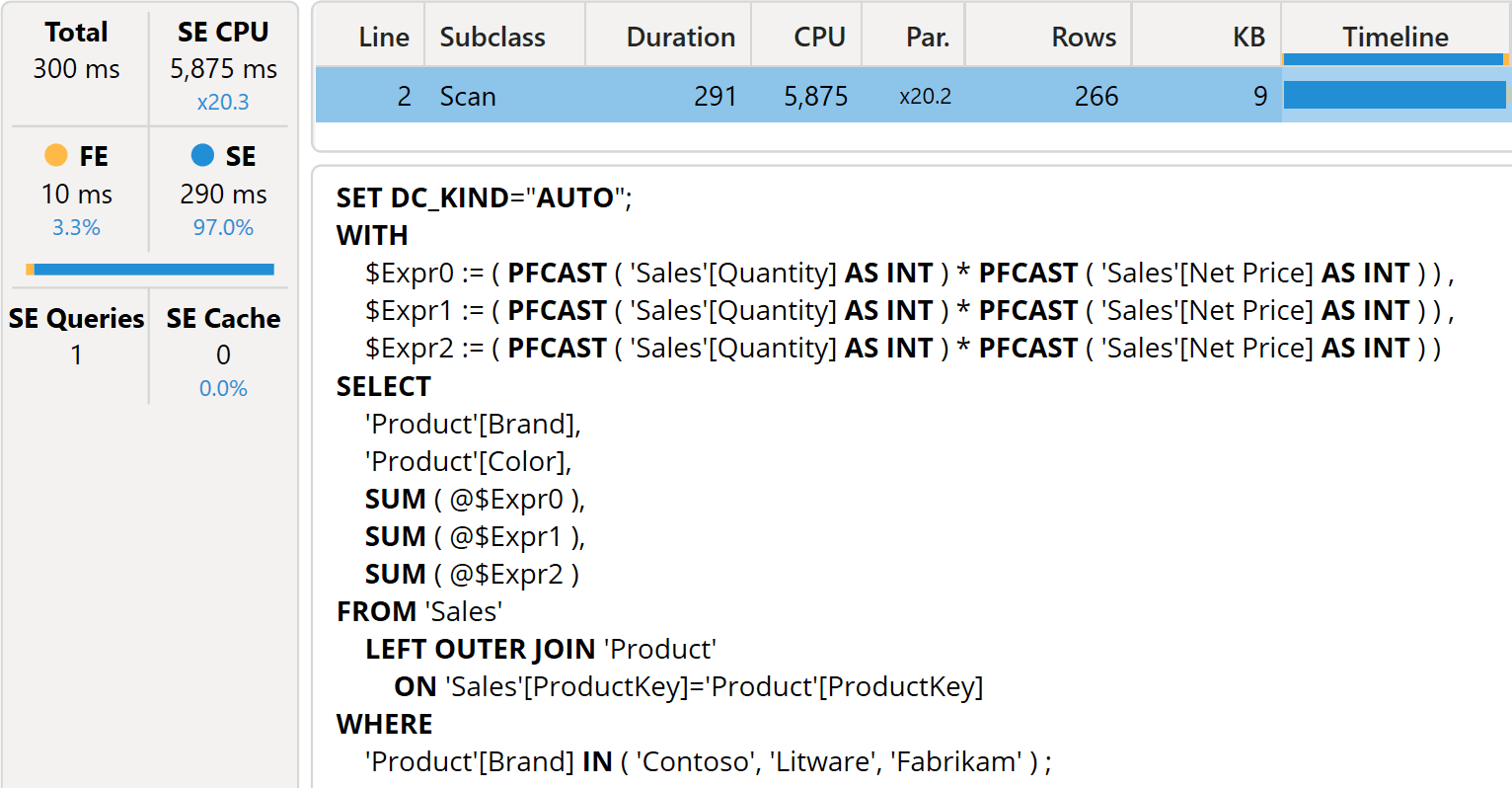
The datacache generated contains both the Product[Brand] and the Product[Color] columns as group-by columns. However, the storage engine query includes three columns that compute the same expression; this is inefficient because it multiplies by three both the calculation and the memory required to store the result.
The formula engine filters the datacache results and aggregates them by Product[Color] column. The time spent in the formula engine is tiny because the estimated number of rows in the datacache (266) is so small. The query plan shows that the same datacache produced by the horizontal fusion is used by five different DataPostFilter nodes.

Rewriting the measure to reduce materialization
The report we created shows only one measure, Sales Fancy Brands. Internally, the datacache materializes three different measures (Sales Contoso, Sales Fabrikam, and Sales Litware) that are summed by the formula engine. Each of these three measures computes Sales Amount internally, and after the horizontal fusion, the datacache includes three copies of the same value. This duplication of the data comes at a cost.
We can push the entire calculation to the storage engine by rewriting Sales Fancy Brands without relying on measures that must be merged by horizontal fusion in a single storage engine request. For example, we can express the same calculation with a single filter:
DEFINE
MEASURE Sales[Sales Fancy Brands Optimized] =
CALCULATE (
[Sales Amount],
KEEPFILTERS (
'Product'[Brand] IN { "Contoso", "Fabrikam", "Litware" }
)
)
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Color],
"Sales Fancy Brands Optimized", [Sales Fancy Brands Optimized]
)
The code in Sales Fancy Brands Optimized still relies on Sales Amount, but it no longer references the Sales Contoso, Sales Fabrikam, and Sales Litware specialized measures. Therefore, any change to the business logic in one of these three measures no longer propagates its effect to Sales Fancy Brands Optimized. In terms of code maintainability, this is a step backwards.
However, by writing the code with a single filter on Product[Brand], we no longer need the horizontal fusion optimization. In addition to that, VertiPaq no longer needs to group by Product[Brand], as the datacache is not read by multiple operators in the query plan. Moreover, there is a single evaluation of Sales Amount.
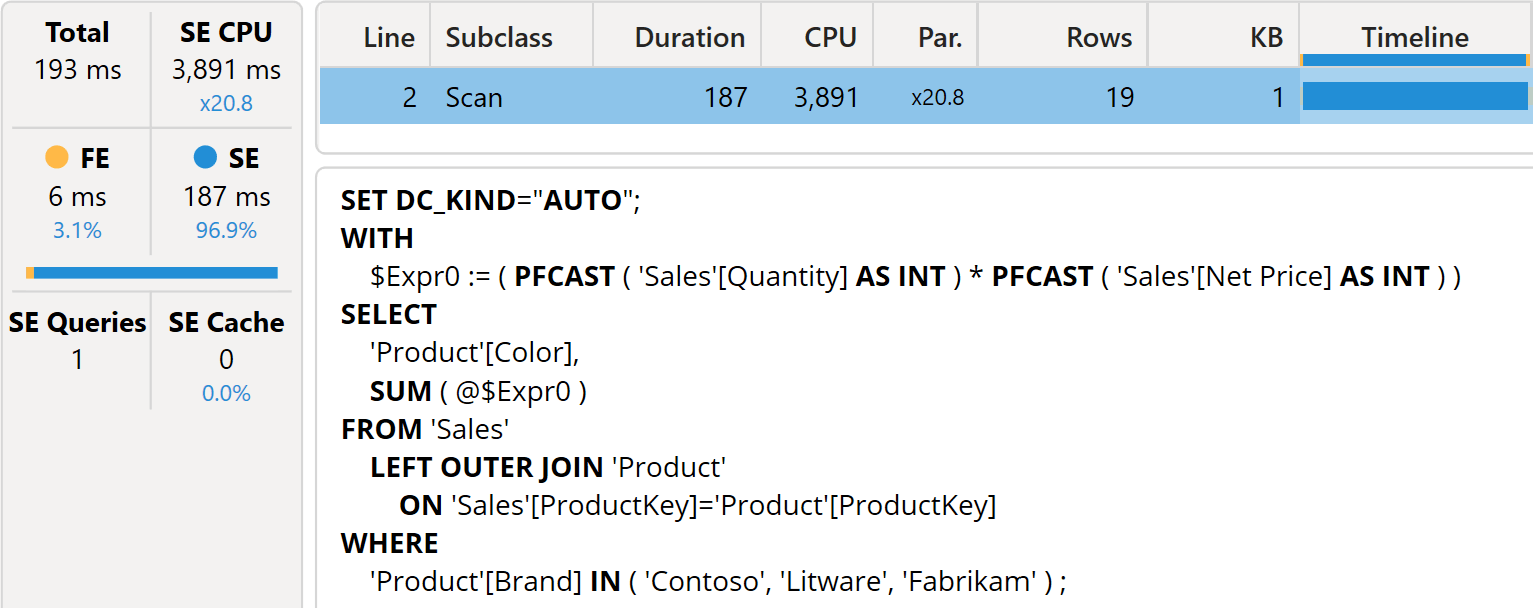
The xmSQL query runs much faster because there is a smaller materialization (19 rows and 2 columns instead of 266 rows and 5 columns), which also benefits the formula engine; indeed, the latter a more straightforward query plan and a reduced number of operations required.

Besides, the speed of this latter measure does not depend on the number of brands selected. The price to pay is always that of a single fact table scan. On the other hand, if we rely only on fusion, each additional calculation requires one more column to be computed and more operators in the formula engine.
Conclusion
Fusion is a beautiful optimization by the Tabular engine. However, when required, it is possible to apply more extreme optimization approaches that might produce code redundancy in different measures, with an impact on the maintainability of the solution.