Almost one month ago I made a post about a brand new Distinct component for SSIS made by Alberto Ferrari and freely available on SQLBI.
The most used way to get distinct rows in a Data Flow that I’ve seen is to use the Sort component, asking only for distinct rows (there is a check box for that in the standard edit dialog box). The Sort component is a fully blocking one, because it requires to stop the flow until all the rows are read from the source. The Distinct component is not blocking, because it does not stop the flow and internally use hash functions and other structures to maintain a list of the already emitted rows. A previous post from Jamie Thomson describes pretty well pro and cons of the Sort component and raise the need for a better solution.
A couple of weeks ago, I realized that there is another option available. Using the Aggregate component, you can select all the fields you want in output (even all the columns) and select “Group By” as operations on them. Simply that. Not so intuitive to get a Distinct in such a way, but if you want performance… this seems the way to go.
From tests we made, using Aggregate component is the faster way to get a Distinct and it also doesn’t consume as much memory as the Sort component. Unfortunately, also the Aggregate is a fully blocking component. The following picture shows the debug of a sample package with the three components: the Distinct is not a blocking one, while the Aggregate is blocking but, once it received all the rows, it produces output very fast, while the Distinct is still flushing the queue. The Sort start the sorting operation after he received all the rows and is still sorting at the moment of picture snapshot.
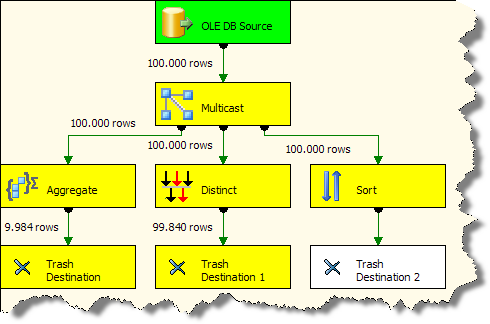
Now we have three options to get a Distinct:
- Aggregate component: it is standard, it is fast, it is fully blocking
- Distinct component: it needs a separate install, it is fast but sometimes not as fast as the Aggregate, it is partially blocking
- Sort component: it is standard, it is the slowest, it is fully blocking, it also sort the data
I think that in general we can use the Aggregate component, just because it does not require a separate deployment of the Distinct component. However, when the fully blocking behavior is not desirable, the Distinct component may worth the time to deploy/install another data flow component.