In DAX, optimizations and data types do not always play nice and can leave you dealing with surprises. In this short article, we see an example of how mixing blanks, Boolean logic, and comparison with TRUE might lead to unexpected results.
The DAX optimizer contains several patterns that are used in order to reduce the complexity of calculations. It is a masterpiece of engineering, whose goal is quite simple: making your DAX code run as fast as possible. Obviously, when the DAX optimizer simplifies your code to make if faster, it needs to make sure that the semantics of the formula are untouched. Otherwise, an optimization might end up changing the results of your code.
In this article, we show one example where an optimization triggers a strange behavior in a calculated column, when mixing blanks and Boolean conditions. Specifically, DAX optimizes the comparison of a Boolean expression with TRUE by removing the comparison operator and returning directly the result of the expression itself. Therefore, this expression:
IF ( <MyCode> = TRUE, <A>, <B> )
is simplified this way:
IF ( <MyCode>, <A>, <B> )
This latter code is shorter, faster, and semantically equivalent. Almost. There is a slight difference when the code is executed in a calculated column. Be advised that the goal of the article is not to expose an undesirable behavior of DAX. Despite the results being strange, the formula can easily be corrected to overcome the problems introduced by the optimization. Still, it is interesting to see how mixing optimizations that are seemingly safe – at first sight – might produce an inaccurate result. Besides, it is also interesting to see how being precise and… yes, pedantic, is how we found the very existence of the optimization.
We discovered the optimization in a scenario where we had to create a Boolean calculated column in the Sales table to simplify the execution of a particular DAX measure required for a variation of the like-for-like pattern. Specifically, the requirement was at the store level, to compute the sum of sales for the dates in the previous year, corresponding to dates with sales in the current year.
The code for the measure requires us to create a table containing the combinations of stores and dates in the current filter context and then move the dates back by one year:
Sales PY lkl :=
VAR DatesToConsider =
SELECTCOLUMNS (
ADDCOLUMNS (
CALCULATETABLE (
SUMMARIZE ( Sales, Sales[StoreKey], 'Date'[Date] ),
ALLEXCEPT ( Sales, Store, 'Date' )
),
"@PYDate", DATE (
YEAR ( 'Date'[Date] ) - 1,
MONTH ( 'Date'[Date] ),
DAY ( 'Date'[Date] )
)
),
"StoreKey", Sales[StoreKey],
"Date", [@PYDate]
)
VAR Result =
CALCULATE (
[Sales Amount],
TREATAS ( DatesToConsider, Sales[StoreKey], 'Date'[Date] )
)
RETURN
Result
As you see, the measure returns a value only when there are sales in both the current and the previous year. We selected a single store before taking the screenshot below.
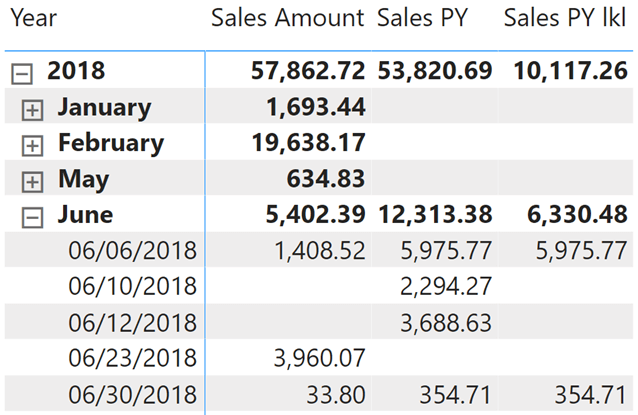
Despite working fine, the solution is quite slow on large tables because it depends on the crossjoin of stores and dates. The more stores, the slower the formula because of the increasing size of the filter that needs to be used. A possible optimization is to consolidate the condition directly in the Sales table in a Boolean calculated column.
A good option is to compute the DatesToConsider variable as a calculated table and then use LOOKUPVALUE to add the column to Sales. We should avoid using the full code of DatesToConsider in the calculated column itself; this is because the use of DATE requires the formula engine and the calculated column would require too much effort for it to be a viable solution. Hence, a calculated table looks like a better choice.
The code for the calculated table is the following:
Dates To Consider =
SELECTCOLUMNS (
ADDCOLUMNS (
CALCULATETABLE (
SUMMARIZE ( Sales, Sales[StoreKey], 'Date'[Date] ),
ALLEXCEPT ( Sales, Store, 'Date' )
),
"@PYDate", DATE (
YEAR ( 'Date'[Date] ) - 1,
MONTH ( 'Date'[Date] ),
DAY ( 'Date'[Date] )
)
),
"StoreKey", Sales[StoreKey],
"Date", [@PYDate],
"UseDate", TRUE ()
)
We added the UseDate column as a constant Boolean value to simplify the LOOKUPVALUE calculated column in Sales. Indeed, the new calculated column in sales can be authored this way:
UseDate =
LOOKUPVALUE (
'Dates To Consider'[UseDate],
'Dates To Consider'[Date], Sales[Order Date],
'Dates To Consider'[StoreKey], Sales[StoreKey]
)
LOOKUPVALUE would return TRUE for the dates to consider for the comparison, BLANK otherwise. Indeed, the Dates To Consider table contains only the dates to use for the comparison – hence the blank if no match is found.
Striving for perfection, we would like the Sales[UseDate] column to contain either TRUE or FALSE, avoiding blanks. Therefore, we can check whether the result of LOOKUPVALUE is TRUE and use a comparison operator:
UseDate =
LOOKUPVALUE (
'Dates To Consider'[UseDate],
'Dates To Consider'[Date], Sales[Order Date],
'Dates To Consider'[StoreKey], Sales[StoreKey]
) = TRUE ()
Quite surprisingly, this code also returns blanks with no FALSE being stored in any row. The reason for this is that the DAX optimizer uses a specific pattern for comparisons with TRUE. When the result of a calculation is compared with TRUE, the engine can strip the comparison and return the calculation itself. Indeed, if LOOKUPVALUE returns TRUE, then the condition is met. If LOOKUPVALUE returns either FALSE or BLANK, DAX will consider it as FALSE. Hence, the optimization makes total sense. Except for this specific scenario.
Indeed, in this scenario we are not using the result of the comparison to perform further conditional logic. We store the result directly in a calculated column. The column is of Boolean data type and – as any column in DAX – it is nullable. Therefore, BLANK and FALSE are not the same. This is why the calculated column results in either BLANK or TRUE.
Note that there would be no difference, neither in storage space nor in performance between using BLANK or FALSE for the column. It is just a matter of elegance of the model: being a Boolean we want it to be either TRUE or FALSE.
The solution is straightforward: the optimization kicks in when you compare an expression with the constant value TRUE and it does not when you compare the expression with FALSE. This is for the obvious reason that the Boolean negation needs to happen when you compare the expression with FALSE. Therefore, rewriting the column by using this last version of the code removes the effect of the optimization and it produces a neat Boolean column with either TRUE or FALSE:
UseDate =
NOT (
LOOKUPVALUE (
'Dates To Consider'[UseDate],
'Dates To Consider'[Date], Sales[Order Date],
'Dates To Consider'[StoreKey], Sales[StoreKey]
) = FALSE
)
Using the new calculated column, the code for the measure is much simpler:
Sales PY lkl optimized :=
CALCULATE (
[Sales PY],
KEEPFILTERS ( Sales[UseDate] )
)
Retrieves a value from a table.
LOOKUPVALUE ( <Result_ColumnName>, <Search_ColumnName>, <Search_Value> [, <Search_ColumnName>, <Search_Value> [, … ] ] [, <Alternate_Result>] )
Returns the specified date in datetime format.
DATE ( <Year>, <Month>, <Day> )
Returns a blank.
BLANK ( )