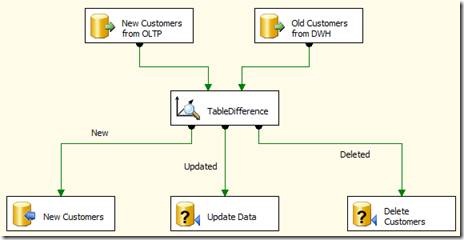
Table difference is an SSIS custom component designed to simplify the management of slowly changing dimensions and – in general – to check the differences between two tables or data flow with SSIS.
Its main advantage over Microsoft standard SCD component is its speed and ease of use, the component receives input from two sorted sources and generates different outputs for unchanged, new, deleted or updated rows.
The project is freeware, full source code is available at www.sqlbi.com.
Note to version 1.x users
The internal structure of the metadata of TableDifference is very different from the previous one. The component is able to read metadata from the previous version and write them with the new format as soon as it is called from inside BIDS so you will be able to reload all the previous metadata without loss of functionality.
However, in writing the new metadata, the component changes the lineage IDs of all the output columns so, when you open a package that contains a previous version of TableDifference, you will need to open its designer to check that everything worked fine and the correct the subsequent flows by double clicking on the components that use TableDifference outputs. I have converted a lot of packages without any problems but, if you encounter something strange, do not hesitate to contact me.
Introduction
One question that arises very often in Data Warehouse programming is “what are the differences between these two tables/flows of data?” It is often the case in SCD management; you receive several millions of customers and should decide what changes need to be done after your last successful load.
Using SSIS we have the SCD component, it works but it does it slow that in the production environment it is quite always convenient to create an “ad hoc” solution to handle the SCD.
We decided to write an SSIS component that has two inputs, one for the “old” and one for the “new” data, compares all the rows that come in from the old and the new flow and sends them to different outputs, namely:
- Unchanged rows (are the same in both input)
- Deleted rows (appear in old but not in new)
- New rows (appear in new but not in old)
- Updated rows (appear in both flows but something is changed)
The following picture illustrates the component functionality better than thousand words.
As not every update is to be handled the same way, it is possible to tag each column with an integer; the number of updated outputs is determined by the number of tags, one for each, in this way you can tag with “10” the historical attributes, with “20” other columns and decide what kind of operation to carry on with the different updates.
The inputs MUST be sorted and have a collection of fields (keys) that let the component decide when two rows from the inputs represent the same row, but this is easily accomplished by SQL Server with a simple “order by” and a convenient index; moreover the SCD do normally maintain an index by the business key, so the sorting requirement is easily accomplished and do not represent a problem.
The main structure
The structure of the component is pretty simple:
- Old Flow Input: it should be attached to a convenient query that returns all the current rows from the SCD
- New Flow Input: it can be connected to the flow where the new structure of the SCD has been computed.
Each input has a buffer where all the incoming rows are directed and maintained.
A separate thread starts as soon as data from both buffers is available and checks for the differences between them, sending the rows to the appropriate output and then removing the buffered rows from the buffers.
The buffer does not need to maintain all the data from the SCD, data is removed as soon as it can be compared with a corresponding row: the buffer, even for a several million record table, should be pretty small (but read the document to the end… some tricks may be useful to avoid memory consumption).
The outputs
The component has three standard outputs for new, deleted and unchanged rows. The number of updated rows output is determined by the user via the component editor, one output is provided for each different updateID that is inserted by the user. The outputs are named “UpdateID” followed by the updateID defined by the user.
Of course, you can easily change the name of the output to something more interesting like “Updated historical attribute” and we encourage you to do so!
The collection of output fields is computed by the component via the intersection of the two inputs: if one column appears in only one input it is not managed, if it appears in both then it will be compared and outputted.
Installing TableDifference
Installation is very simple:
· copy TableDifference.DLL into
“<Program Files>Microsoft SQL Server90DTSPipelineComponents”
· add the DLL to the GAC using “GACUTIL –I TableDifference.DLL”
No installer for the moment… sorry.
Note for Vista users: you need to run these command on a command line opened with administrator privileges to perform the tasks.
Using TableDifference
After the component is installed you should add it to the toolbar as for every SSIS component and then you are ready to use it.
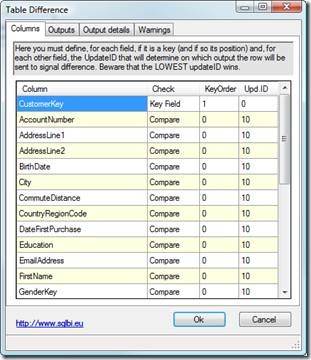
After both inputs has been attached, by double clicking on the component, you reach the component editor that shows a single window like this:
A few words about what is happening just before the component editor pops up:
- TableDifference analyzes all the columns in both inputs and compares their names. If the name of two columns and their corresponding types are identical, TableDifference adds them to the available columns to manage.
- If the flows are sorted, their sort columns will be marked as key fields, using the same order in which they appear in the sort.
- All other columns are assigned a standard Update ID of 10 and are managed as comparable columns.
Using the component editor you need to provide these information for the columns:
- Check Option: you can choose the column type between:
- Key field: these column will be used to detect when two rows from the inputs represent the same row. Beware that the inputs must be sorted by those columns
- Compare: these columns will be compared one by one to detect differences
- Prefer NEW: these columns will be copied from the NEW input directly into the output, no check
- Prefer OLD: these columns will be copied from the OLD input directly into the output, no check
- KeyOrder: If a column is of type “Key Field” it is the order under which the field appear under the “order by” clause of your query. Beware that the component do not check for the correct sorting sequence, it is up to you to provide this information.
- Update ID: each different UpdateID creates a different output flow. If you need to detect when a change appears in some column you can use different update ID. Beware that the lowest update ID wins, i.e. if AccountNumber has update id of 10 and AddressLine1 has update id of 20, then Accountnumber will be checked first and if a change is detected, the row will go to update output 10, no matter if AddressLine has a difference.
Clicking “OK” is enough for the component to generate the outputs and to define the metadata for all the outputs.
In version 2.0 there are a three new panels:
Outputs panel
In this panel you can choose which output to enable. If you are not interested, for example, in the unchanged output, then you can deselect it from this panel to avoid warnings for unused columns.
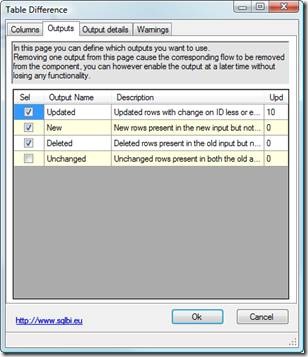
You can also rename outputs and provide a concise description of them. Renaming is very useful as it gives the data flow clearness.
Output Details
This panel let you select the columns for each output. You cannot add any column but you can disable columns for outputs that do not use them.
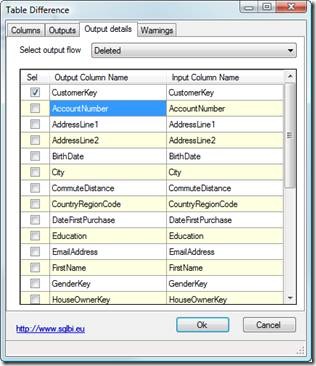
The upper combo box let you choose an output, in the grid you can select or unselect any column. This feature is useful as it avoids warnings for unused columns. In the picture, the deleted output will receive only the customer key as it will make no use of any other information.
Always remember that removing useless output columns increases the performances of the component.
Misc Options
Under this pane there are miscellaneous options.
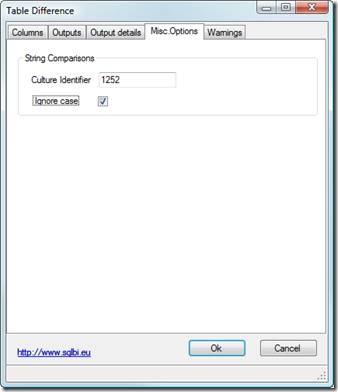
Here you can define, for string comparisons:
- The culture ID to use to perform the comparison. If not specified TableDifference will use the culture ID of the running task. The default is “empty”.
- If you want it to ignore casing during string comparisons. The default is unchecked so TableDifference will perform comparison considering case.
Warnings
This panel will list any unused column from the input. As you might recall, if two columns are not identical regarding name and type, TableDifference will ignore them. This might be an error but the decision is up to you. By checking the warnings panel you can see if TableDifference is working with all the columns you need it to compare.
FlowSync
The component works fine and do not consume memory if and only if the input from both flows come in at a synchronized speed: if one input is much faster than the other then the component will start buffering data and consume memory that will be freed only when the buffer starts to shrink.
Using the component to compare two tables with 5 millions of records we had several problems with memory, because data came in from one buffer much faster than the other and, after the difference (and hence the buffer on one input) reached 1.5 millions of records, the whole memory of the DtExec process (in a 32 bit virtual space) was filled in.
As both inputs were from a simple “Select * From” and the speed from both lines was the same, we discovered that – for some obscure reason – SSIS prefers one input to the other and do not leave enough time to both tasks, resulting in memory consumption by the component.
FlowSync is a component that will make two or more flows of data in an SSIS data flow package run at the same speed, by stopping one flow if the others run too slow. It has been created as a convenient companion to TableDifference to resolve the problems with memory occupation, it can be used by its own in the case where you want flows to run at the same speed.
It makes use of semaphores to handle synchronization, so no CPU is ever wasted, when the faster flows is stopped all the CPU is free for others (more useful) processes.
You can find source code, executable and description of FlowSync at www.sqlbi.com. We normally use flowsync when we need to compare more than half a million rows while we use TableDifference without flow sync for all the smaller tables in a project.