 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariSeveral months ago, we wrote an article (recently updated) about the SWITCH optimization in DAX and Power BI. We explained that the engine produces the best execution plan for SWITCH when the column analyzed is statically filtered in the query. Translated into Power BI artifacts, this means that when you have a slicer to select a parameter, the SWITCH function should use precisely the column exposed in the slicer and not the underlying column used for the sort order (or any other column of the same table).
For example, consider the following report where the slicer shows a list of measures that drives what to display in the matrix for the Selected Index measure.
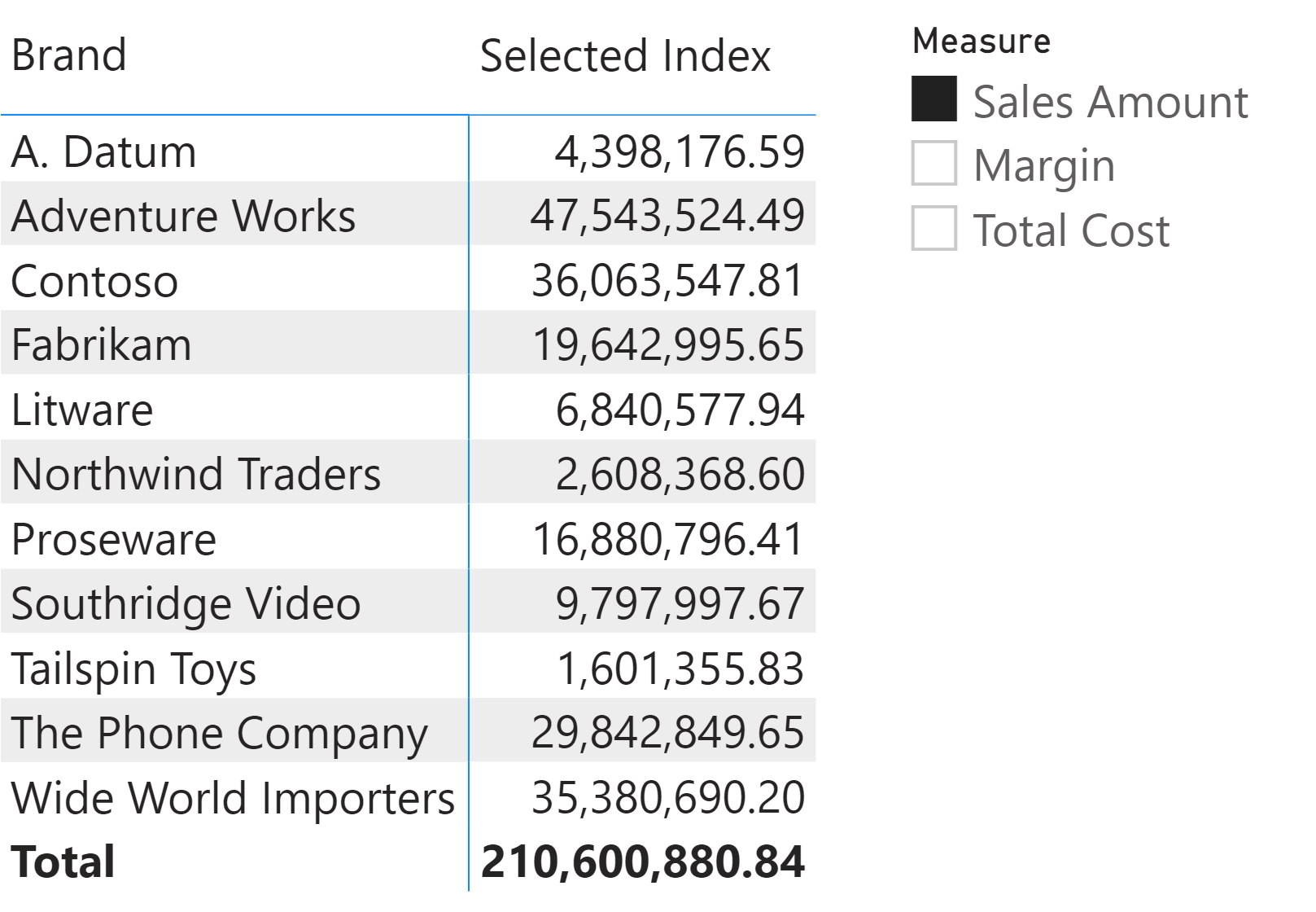
The Selected Index measure is defined this way:
Selected Index =
SWITCH (
SELECTEDVALUE ( Options[Index] ),
1, [Sales Amount],
2, [Margin],
3, [Total Cost]
)
The Options table has two columns: the Name column is displayed in the slicer, and the Index column is used to sort the names in the slicer and to apply the business logic in the SWITCH used by the Selected Index measure.
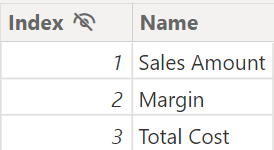
Remember that we are using a simple example to illustrate the more general case of a parameter injected in a measure through a slicer: the specific use case of this example would be better served by the Fields Parameters in Power BI, but here we need to focus on the performance differences of SWITCH when it depends on a user selection made on the report.
In the slicer, Sales Amount is before Margin because of the Options[Index] order; otherwise, the slicer would show the values of Options[Name] in alphabetical order. When you save the file, Power BI stores the selection as “Sales Amount” selected on Options[Name], ignoring the Options[Index] value. The filter generated in the query by Power BI is the following:
TREATAS( { "Sales Amount" }, 'Options'[Name] )
However, you may prefer to write the business logic using a column different from the one displayed in the slicer. For example, you might want to write a measure that will work even if you translate or rename the descriptions in Options[Name]. For this reason, the Selected Index measure reads the selection by using Options[Index], which is the hidden column used to sort the Options[Name] column.
As described in Understanding the optimization of SWITCH, this approach does not provide optimal performance because the SWITCH is applied to a column that depends on the column used in the slicer. The optimal query plan is only available when the column is the same column filtered in the query. If you find that this performance issue impacts your model and you are in an advanced stage of development, changing the existing code may be expensive. However, we can change the behavior of Power BI by using the Group By Columns, as described in Understanding Group By Columns in Power BI.
We created a copy of the Options table called Options Group By to keep a single sample file.
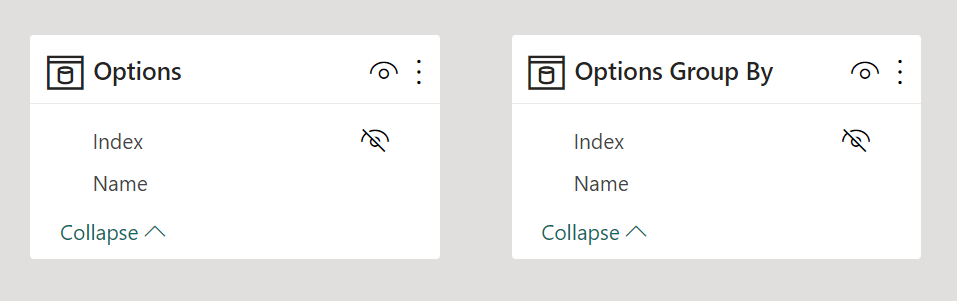
In the Options Group By table, we set the Group By Columns property of Name to be grouped by Index.
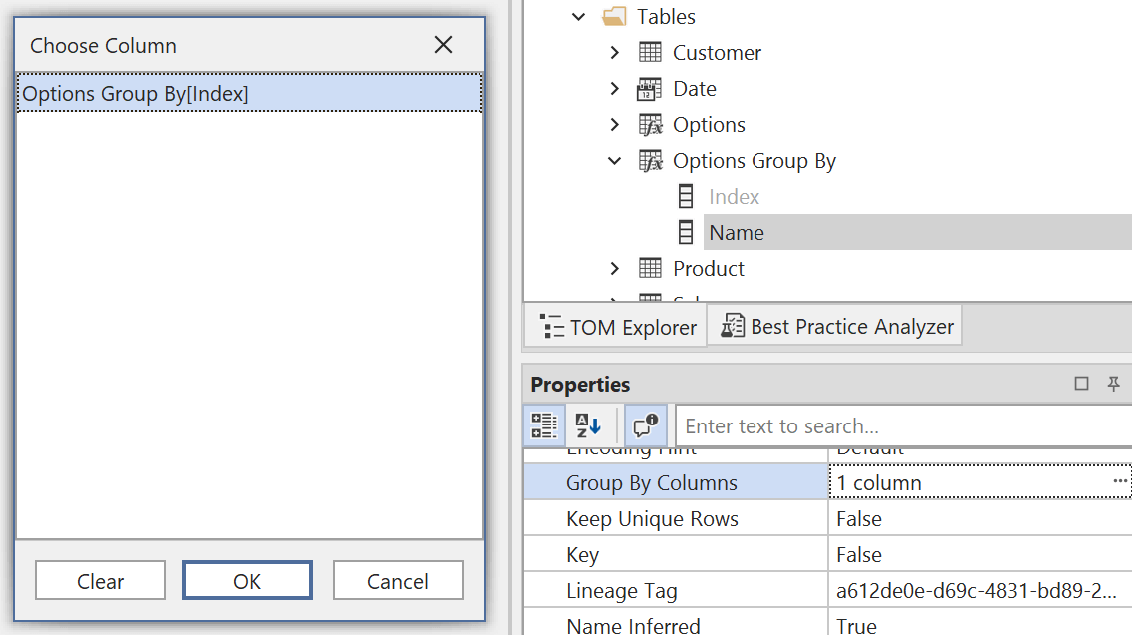
Because of this change, Power BI no longer stores the ‘Options Group By'[Name] selection by using its value: Power BI retrieves the corresponding ‘Options Group By'[Index] value, stores it as the selected value for the slicer, and filters ‘Options Group By'[Index] in the filter context with the corresponding selection. In other words, Power BI shows Name, but it actually stores and filters Index!
The Selected Index Optimized measure is almost identical to Selected Index; the only difference is that it works on Options Group By instead of Options:
Selected Index Optimized =
SWITCH (
SELECTEDVALUE ( 'Options Group By'[Index] ),
1, [Sales Amount],
2, [Margin],
3, [Total Cost]
)
The filter applied in the DAX query by Power BI uses the ‘Options Group By'[Index] column, so the query plan is optimized:
TREATAS ( { 1 }, 'Options Group By'[Index] )
We do not repeat here how SWITCH optimizes the query plan: the purpose of this article was just to add other considerations that can be useful to optimize existing models consumed only by Power BI because the Group By Columns property is not supported for MDX queries, and cannot be used in Excel reports.
Conclusion
The Group By Columns property can change the column used to store the slicer selection so that the value that is displayed can be renamed or translated in the model without losing the selection applied to an existing report. The filter is also applied directly to the column used in Group By Columns, so the SWITCH function gets an optimized query plan even if it reads the selection of a column that is not visible to the user, as long as it is the column used in Group By Columns. The biggest limitation of this technique is that the column cannot be used in Excel reports, because Excel does not automatically add the underlying column in the MDX query as Power BI does for the DAX queries generated for the report.
Returns different results depending on the value of an expression.
SWITCH ( <Expression>, <Value>, <Result> [, <Value>, <Result> [, … ] ] [, <Else>] )