 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariThe SWITCH function in DAX is widely used to define different execution paths depending on the condition of an expression. A very common case is when we want to check the state of a slicer, so that the selection made by the report user directly affects the result of a DAX formula.
Scenario
In our example, the selection in the Measure slicer defines the measure to display in the matrix.
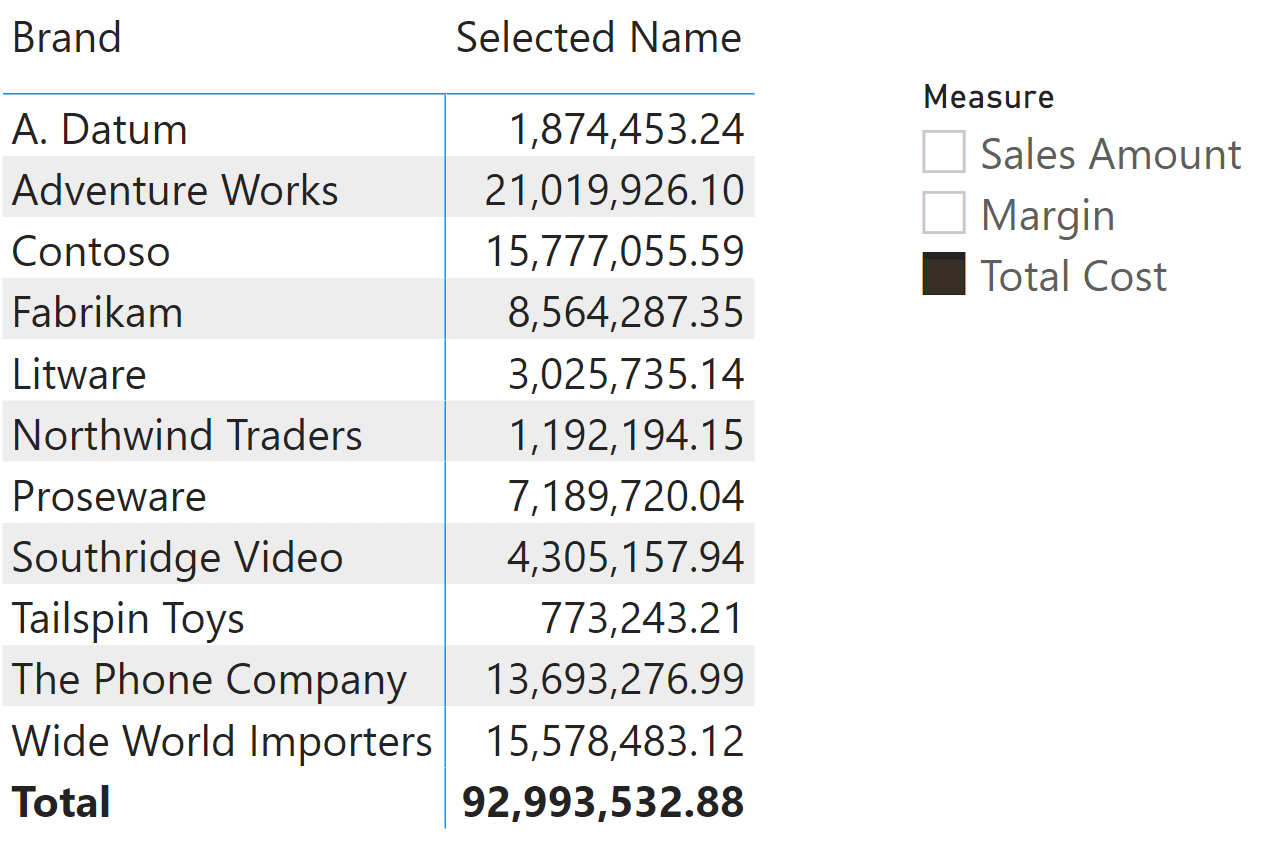
The Selected Name measure is defined as follows:
Selected Name :=
SWITCH (
SELECTEDVALUE ( Options[Name] ),
"Sales Amount", [Sales Amount],
"Total Cost", [Total Cost],
"Margin", [Margin]
)
Depending on the selection on Options[Column] – which is displayed in the Measure slicer – the Selected Name measure returns the corresponding measure. The cost to evaluate Selected Name should correspond to the cost of evaluating only one of the possible measures (Sales Amount, Total Cost, or Margin). This is what usually happens, but there are conditions where DAX is not able to correctly optimize the code. This results in performance levels being poorer than expected.
Before diving into different use case scenarios, we should take a look at the content of the Options table which is used to populate the Margin slicer. The names are not displayed in alphabetical order – Sales Amount is the first name shown, followed by Margin. This order is obtained by using the Sort by Column property to sort Option[Column] by Option[Index].
As a reference, here are the definitions of the corresponding Sales Amount, Total Cost, and Margin measures:
Sales Amount := SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
Total Cost := SUMX ( Sales, Sales[Quantity] * Sales[Unit Cost] )
Margin := [Sales Amount] - [Total Cost]
SWITCH on a column filtered directly: optimal execution
We tested performance using a shorter and simplified version of the DAX query generated by the Power BI report shown prior:
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Brand],
TREATAS ( { "Sales Amount" }, 'Options'[Name] ),
"Selected Name", [Selected Name]
)
ORDER BY 'Product'[Brand]
The Selected Name measure provides the optimal execution. First of all, the only storage request for the Sales table references Sales[Quantity] and Sales[Net Price], which are the columns used by Sales Amount. The Sales[Unit Cost] column is never referenced by the storage engine requests:
WITH
$Expr0 := (PFCAST( 'Sales'[Quantity] AS INT ) * PFCAST( 'Sales'[Net Price] AS INT ))
SELECT
'Product'[Brand], SUM ( @$Expr0 )
FROM 'Sales'
LEFT OUTER JOIN 'Product' ON 'Sales'[ProductKey]='Product'[ProductKey];
The formula engine physical query plan displays a total of 40 lines. We do not need to analyze them in detail. It is enough to realize that there is an internal join between the list of brands in Product[Brand] and the result of the storage engine query above, which aggregates the sum of Sales[Quantity] by Sales[Net Price] grouped by Product[Brand].

Notice the length of the logical query plan: 27 rows, without any mention of the Sales[Unit Cost] column used by Margin and Total Cost.

This is the expected behavior: only the columns actually needed in the calculation are referenced in the query plans and in the storage engine requests. We obtained this behavior because the SWITCH statement depends on the selection of a column that is directly filtered in the report; that selection has the same filter for every cell of the resulting matrix. From a DAX standpoint, the filter on Options[Name] is applied directly to the SUMMARIZECOLUMNS function (see line 4 in the DAX query at the beginning of this section):
Selected Name :=
SWITCH (
SELECTEDVALUE ( Options[Name] ),
"Sales Amount", [Sales Amount],
"Total Cost", [Total Cost],
"Margin", [Margin]
)
Because the SWITCH statement depends on a column that is directly filtered in the filter context, we call this scenario a SWITCH on a column filtered directly. As we will see, this is the ideal condition for the optimization of SWITCH.
SWITCH on a column filtered indirectly: formula engine overhead
A variation of the previous scenario is a SWITCH function depending on the hidden Options[Index] column, which is used to control the sort order of the names in the slicer. There could be many reasons for using this approach, like wanting to make the code insensitive to name changes in the user interface. As we will see, there is a price for that.
This time the matrix uses the Selected Index measure instead of Selected Name.
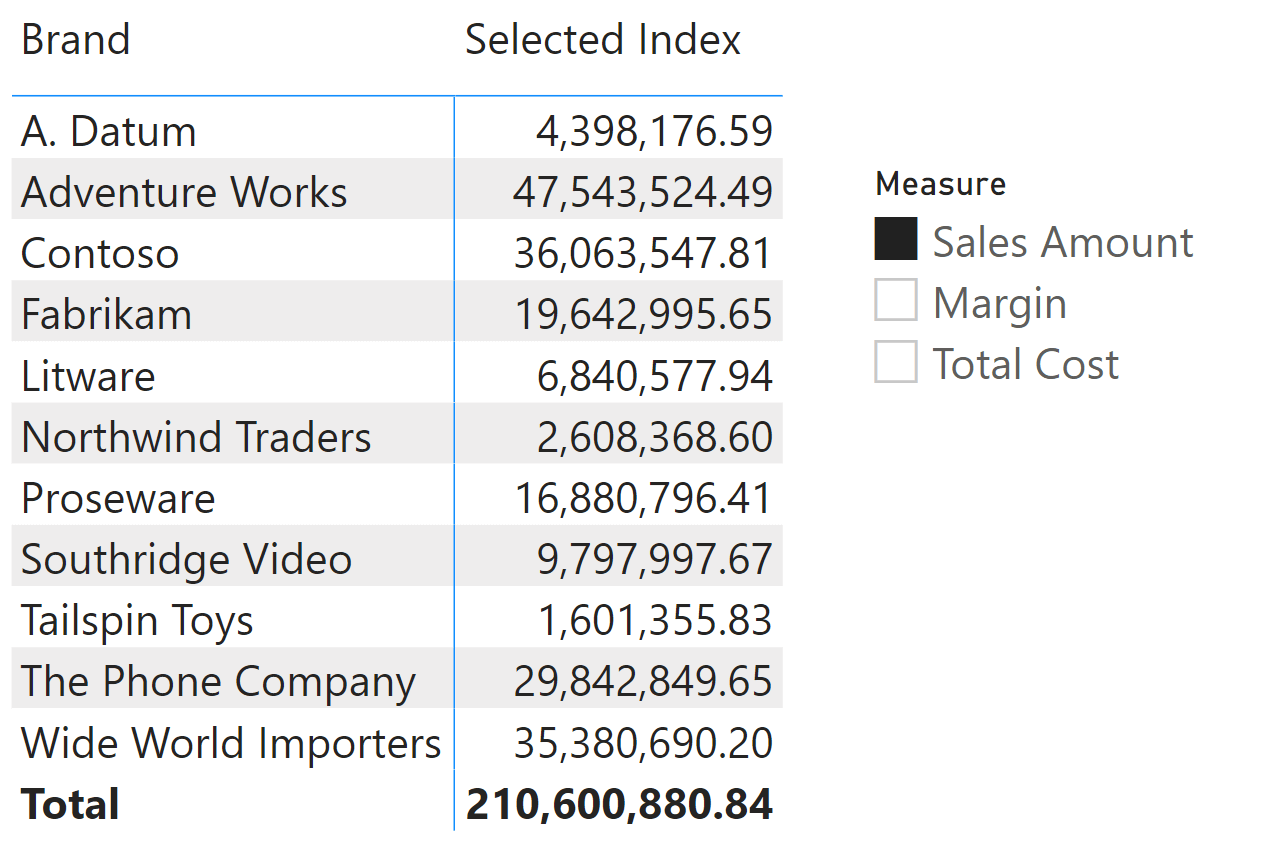
The Selected Index measure is defined as follows:
Selected Index :=
SWITCH (
SELECTEDVALUE ( Options[Index] ),
1, [Sales Amount],
2, [Margin],
3, [Total Cost]
)
The more important difference is in line 3: SWITCH now reads the selection in Options[Index] and returns the corresponding measure. We test the code using the query we saw before, still filtering the Options[Name] column:
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Brand],
TREATAS ( { "Sales Amount" }, 'Options'[Name] ),
"Selected Name", [Selected Name]
)
ORDER BY 'Product'[Brand]
Because there is only one value for Options[Index] for each value of Options[Name], we do not expect any difference in the result. The result is indeed the same and we observe a minimal impact on the storage engine requests, which retrieve the value of Options[Index] corresponding to the selection made on Options[Name] by filtering the Sales Amount name:
SELECT
SUM ( ( PFDATAID ( 'Options'[Index] ) <> 2 ) ),
MIN ( 'Options'[Index] ),
MAX ( 'Options'[Index] ),
COUNT ( )
FROM 'Options'
WHERE
'Options'[Name] = 'Sales Amount';
However, the more important thing is that there are no additional storage engine requests for the Sales table. Only Sales[Quantity] and Sales[Net Price] are referenced by a storage engine request. The Sales[Unit Price] column is never queried because it is never evaluated – at least not by the storage engine.
From a formula engine point of view, the situation is different. First of all, the logical query plan references the calculations that will never be executed. The following picture shows that there are now 76 rows instead of 27 in the logical query plan, and part of the logical query plan references the Sales[Unit Cost] column used by the Total Amount and Margin measures.

The analysis of the physical query plan is more difficult, because the aggregated columns are not displayed directly and it is hard to see the dependency on Sales[Unit Cost] there. However, the physical query plan now includes 190 rows instead of 40 rows. It shows many more Spool_Iterator branches, many of them returning 0 records.

The technical explanation is that the formula engine is unable to predict that the filter on Options[Name] will also filter a single value for Options[Index]. It has to query the model with a storage engine query to retrieve the selected values on Options[Index], so it cannot predict which execution branches will be needed. Therefore, it prepares for the execution of all the branches, even though many of them will never provide a result to the report. Unfortunately, these unused branches are not free. You can see an additional formula engine cost for them: that actual cost depends on the number of branches and on the complexity involved in the underlying formulas – a single unexecuted measure reference could hide other thousands of rows of query plan that will never produce any result.
The lesson here is, be aware that there could be an additional cost for a SWITCH expression executed on a column that is crossfiltered by other columns and that is not directly filtered in the report.
UPDATE 2023-03-28: added the workaround described in the following section.
SWITCH on a column filtered indirectly: workaround for Power BI
If you want to use the SWITCH function by using the value selected in Options[Index] column while the slicer displays the Options[Name] column, you can use the Group By Columns feature in Power BI (read Understanding Group By Columns in Power BI).
When you use that feature, the items selected in the slicer are stored by using the underlying Options[Index] column. As a consequence, the Options[Index] column is directly filtered in the filter context and generates the optimal execution we previously described in this article.
Remember that Group By Columns has the following side-effects:
- It is not supported by Excel
- The Options[Name] column selection cannot be read by using SELECTEDVALUE, and SUMMARIZE should be used instead by including both Options[Name] and Options[Index].
SWITCH on columns with complex filters: formula engine overhead
The SWITCH depending on the Options[Name] column is optimized only when there is a direct filter with a single selection. However, that filter must be produced by a simple selection and not by a complex expression in order to be optimized. For example, consider the following report with a page filter excluding Total Cost from the Measure slicer.
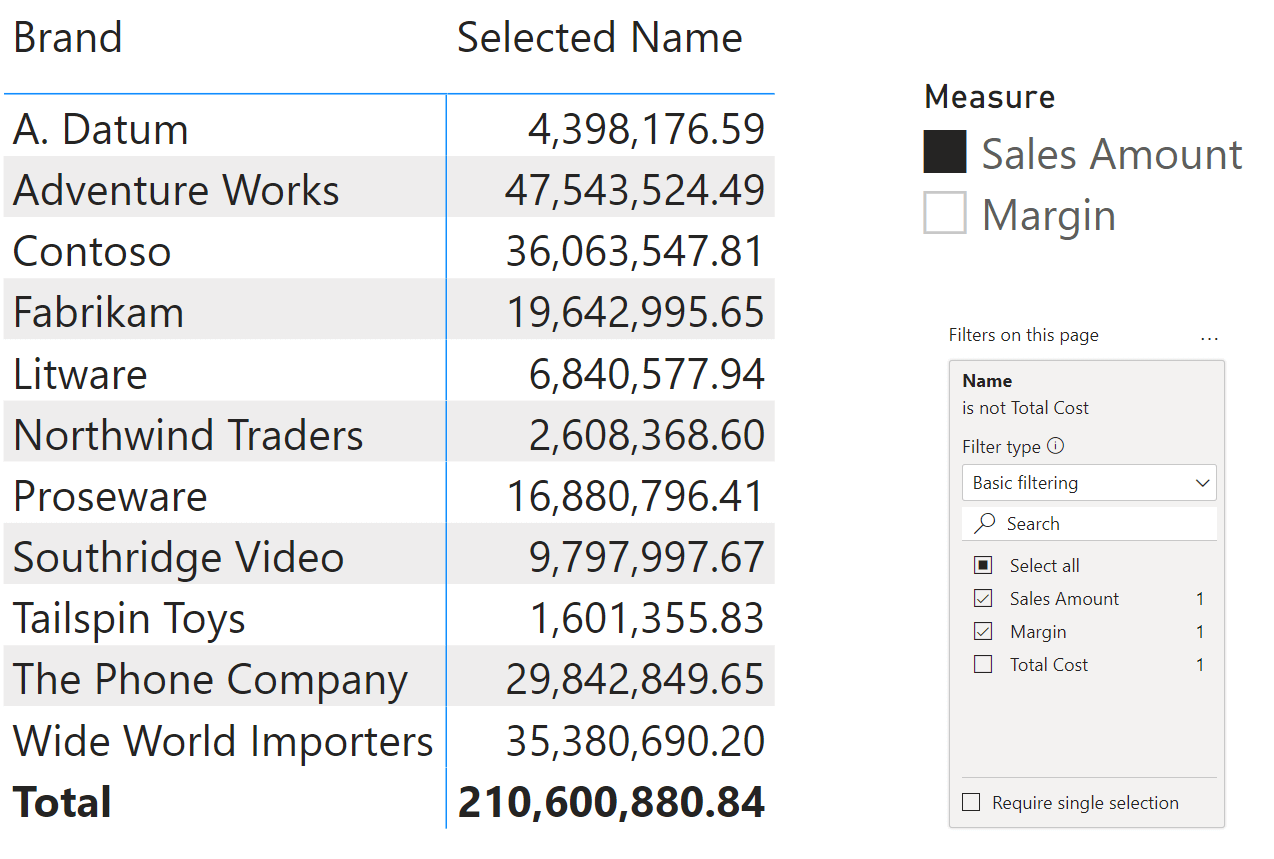
The simplified DAX query produced for the matrix in this report is the following:
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Brand],
FILTER (
ALL ( 'Options'[Name] ),
'Options'[Name] = "Sales Amount"
&& ( NOT 'Options'[Name] = "Total Cost" )
),
"Selected Name", [Selected Name]
)
ORDER BY 'Product'[Brand]
Even though the filter condition specified for Options[Name] filters only Sales Amount, the simple presence of the condition obtained by combining the page filter ( NOT ‘Options'[Name] = “Total Cost” ) with the slicer selection ( ‘Options'[Name] = “Sales Amount” ) produces a query plan for SWITCH that is not optimized. The situation is similar to the problem analyzed in the previous section. The storage engine requests are still optimized, but the formula engine spends time evaluating execution branches that do not produce any result. The logical query plan shows the dependency on Sales[Unit Cost], which is never used in the selected Sales Amount measure.

The query plan shows 196 rows (instead of the 40 rows of the more optimized plan), still including many more Spool_Iterator branches that return 0 records.

The reason why the engine does not optimize this case is more difficult to explain, because the result of the logical expression could be simplified without having access to the storage engine. However, this is the result of two filters on the same Options[Name] column applied to the matrix visual: one from the page filter and one from the slicer. The engine behavior observed is consistent and predictable – though it could change and be improved in future versions.
Also in this case, there is an additional price to pay for the lack of optimization. The bad news is that the condition described in this section depends entirely on the report user and not on the model author. While it is not possible to avoid that scenario, it is helpful to recognize it in case of performance issues, so that an action can be taken at the report level. The workaround in this case can only be applied to the report: by applying “not Total Cost” as a visual filter on the slicer instead of as a page filter, the matrix visual only receives one filter (the selection made on the slicer) and produces the optimized query plan.
Conclusions
The SWITCH statement is optimized for expressions that check a single value selected in a column. While the optimization always works to reduce the storage engine requests, the work in the formula engine is completely optimized only when SELECTEDVALUE receives the column filtered directly and without multiple filters applied to the same column. For example, a page filter that reduces the options available in the slicer used by SELECTEDVALUE could still trigger additional work at the formula engine level.
Returns different results depending on the value of an expression.
SWITCH ( <Expression>, <Value>, <Result> [, <Value>, <Result> [, … ] ] [, <Else>] )
Create a summary table for the requested totals over set of groups.
SUMMARIZECOLUMNS ( [<GroupBy_ColumnName> [, [<FilterTable>] [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<FilterTable>] [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] ] ] )
Returns the value when there’s only one value in the specified column, otherwise returns the alternate result.
SELECTEDVALUE ( <ColumnName> [, <AlternateResult>] )
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )