Today I was optimizing a package that handles a very common topic: process some rows and send all them to a flow but, for some of them, make additional processing.
A simple Multicast and a Conditional Split solve the problem, the picture explains it better than my words:
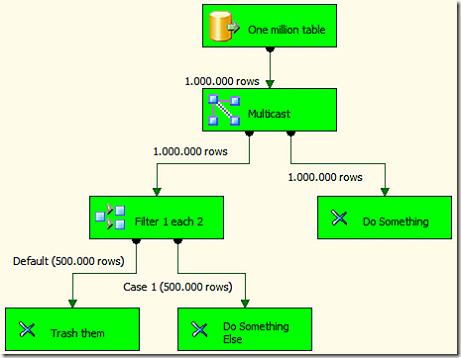
Now, I was wondering why we should duplicate one million rows to two millions and then trash half of them away. I thought a better solution was to separate the rows before and duplicate only half a million, bringing them together again with the other half million from the other flow. So I tried this solution, thas does exactly the same but does not trash anything. We are not in the age of consumerism and we do not like to trash anything, don’t we?
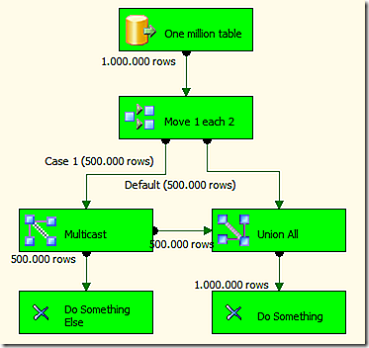
Well, even if I thought it would be a better solution, it is not. The first one (with one million rows of 1K each) takes approximately 13 seconds to run, the second one with the same data 16 seconds, that is 23% slower than before.
So, the conclusion is that SSIS still lives in the age of consumerism, the process of UNION ALL takes a very long time to process and makes trashing a better solution. There are good explanations for this (UNION ALL does a lot more work than Multicast does) but I did not think that a 23% degradation would occur.
The lesson is: it is best to trash then try to recycle, at least with data with SSIS. :)
Returns the union of the tables whose columns match.
UNION ( <Table>, <Table> [, <Table> [, … ] ] )
Returns all the rows in a table, or all the values in a column, ignoring any filters that might have been applied.
ALL ( [<TableNameOrColumnName>] [, <ColumnName> [, <ColumnName> [, … ] ] ] )