 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariA question that is often asked during the design of a Power BI data model is whether it is better to use an Integer or a Datetime column to link a fact table with the Date dimension. Historically, using Integers has always been a better choice in database design. However, Tabular is an in-memory columnar database, and its architecture is quite different from the relational databases we might be used to working with.
Indeed, in Tabular there are no technical differences between using a Datetime or an Integer to create a relationship. The database size, the query speed, and any other technical detail are absolutely identical. Therefore, the choice is not related to technical aspects, but rather on the convenience of the design. Depending on the specific requirements of your model, you might favor one data type against the other. In the most common scenarios, a Datetime proves to be better because it provides more possibilities to compute values on dates without having to rely on relationships. With that said, if your model uses Integers and you do not need to perform calculations on the dates represented in the table, then you can choose the most convenient data type – that is, the one already used in the original data source.
The remaining part of the article aims to prove the previous sentences, and to provide you with the technical details about how we tested the respective performance of the two options.
We started from the Contoso database, with 2 billion rows in Sales and dates in a 10-year range. We created two different databases: in the first one the Order Date column is stored as a Datetime, in the second one the same Order Date column is stored as an integer in the format YYYYMMDD.
Before we start the test, a bit of theory is needed. When a column is loaded in the VertiPaq engine (the in-memory database engine of Tabular), it is compressed using either hash-encoding or value encoding. Hash-encoding is the most common technique: VertiPaq creates a dictionary of the values in the column, and instead of storing the values it stores their index in the dictionary. In other words, regardless of the original datatype of the column, the column values are stored as integers. Therefore, when VertiPaq chooses hash-encoding for a column, its original data type is rather irrelevant from a technical point of view. These considerations are important in our scenario, since VertiPaq always chooses hash-encoding for columns that are involved in a relationship – as is our case.
The efficiency of hash-encoding depends on only two factors: the number of distinct values of the column and the data distribution. Regardless of whether we use an Integer or a Datetime, these two factors are identical.
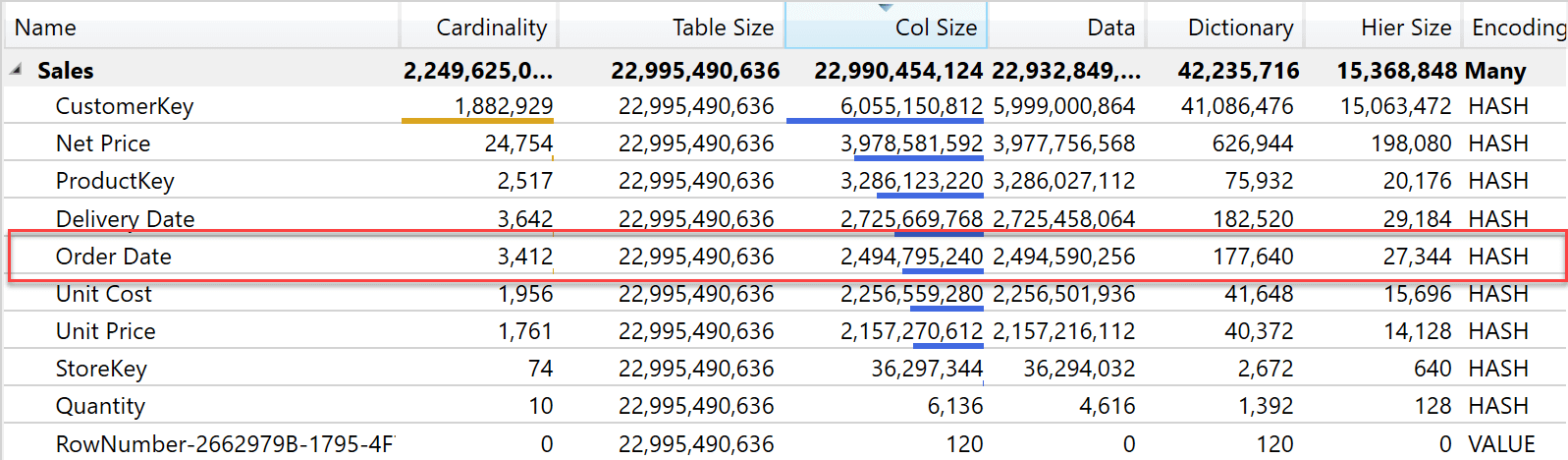
This is the reason why the size of the two columns is the same. The following figure shows the size of the Order Date column using a Datetime.
The same table, with an Integer key looks like this below.
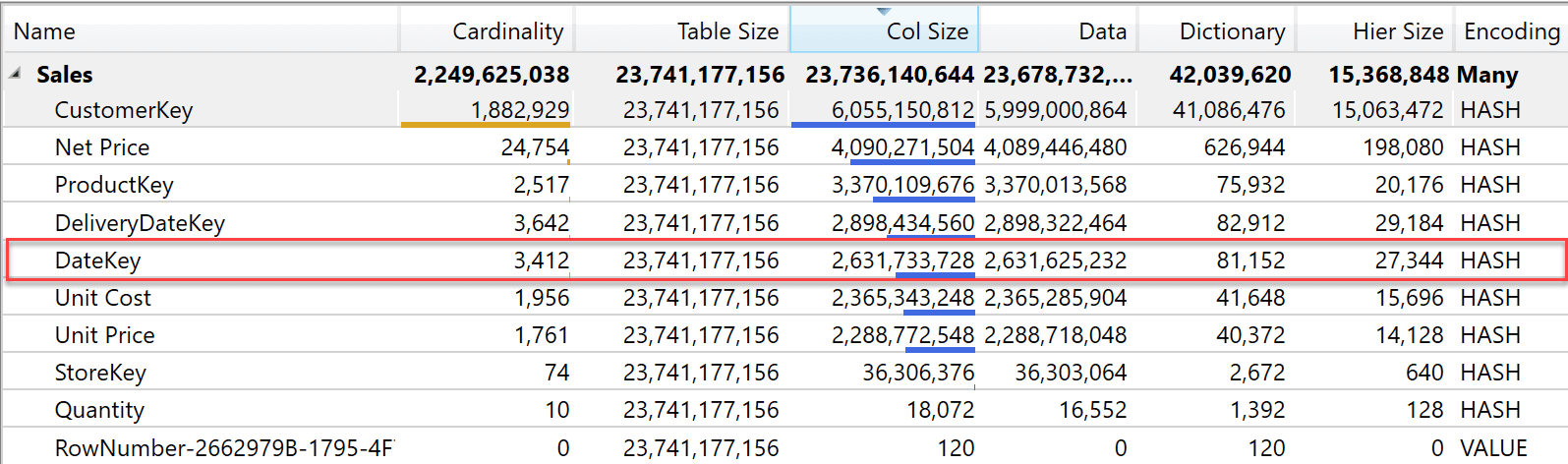
As you see, using an Integer produces a smaller dictionary. This is because each value in the dictionary is slightly smaller, but the column size is very close. Quite surprisingly, the Integer column produces a slightly larger column size: 2.6Gb compared with 2.5Gb when using a Datetime column. Overall, the difference is tiny and likely to be the result of a different choice of sort order for some segments in the table.
Because the two columns end up being the same size, all the performance tests we performed result in identical performance. From the query point of view, there are no differences between using an Integer or a DateTime.
Our findings align with the theory: we were not expecting to spot a difference from the storage and performance points of view.
There is a difference in the two data types when it comes to performing calculations. For example, if we need to compute the average delivery days by subtracting Order Date from Delivery Date, the calculation is much simpler to author in the scenario where the Sales table stores dates. Indeed, if the Sales table contains only the DateKey as an integer, then the calculation requires us to first retrieve the actual date from the Date table, and only later to perform the calculation.
Here is the sample query when the Sales table stores a DateTime:
DEFINE
MEASURE Sales[AvgDeliveryDays] =
CALCULATE (
AVERAGEX ( Sales, Sales[Delivery Date] - Sales[Order Date] ),
NOT ISBLANK ( Sales[Delivery Date] )
)
EVALUATE
SUMMARIZECOLUMNS (
'Date'[Year],
'Date'[Month],
"Avg delivery", [AvgDeliveryDays]
)
If we store Order Date using an Integer, the same query is a bit more complex because it transforms integers into dates to perform the subtraction:
DEFINE
MEASURE Sales[AvgDeliveryDays] =
CALCULATE (
AVERAGEX (
Sales,
VAR DeliveryDate =
LOOKUPVALUE ( 'Date'[Date], 'Date'[DateKey], Sales[DeliveryDateKey] )
VAR OrderDate =
RELATED ( 'Date'[Date] )
RETURN
DeliveryDate - OrderDate
),
NOT ISBLANK ( Sales[DeliveryDateKey] )
)
EVALUATE
SUMMARIZECOLUMNS (
'Date'[Year],
'Date'[Month],
"Avg delivery", [AvgDeliveryDays]
)
The difference in complexity of the code is also reflected in its performance. The query using a Datetime column runs in 873 milliseconds and it is a pure Storage Engine (SE) query:
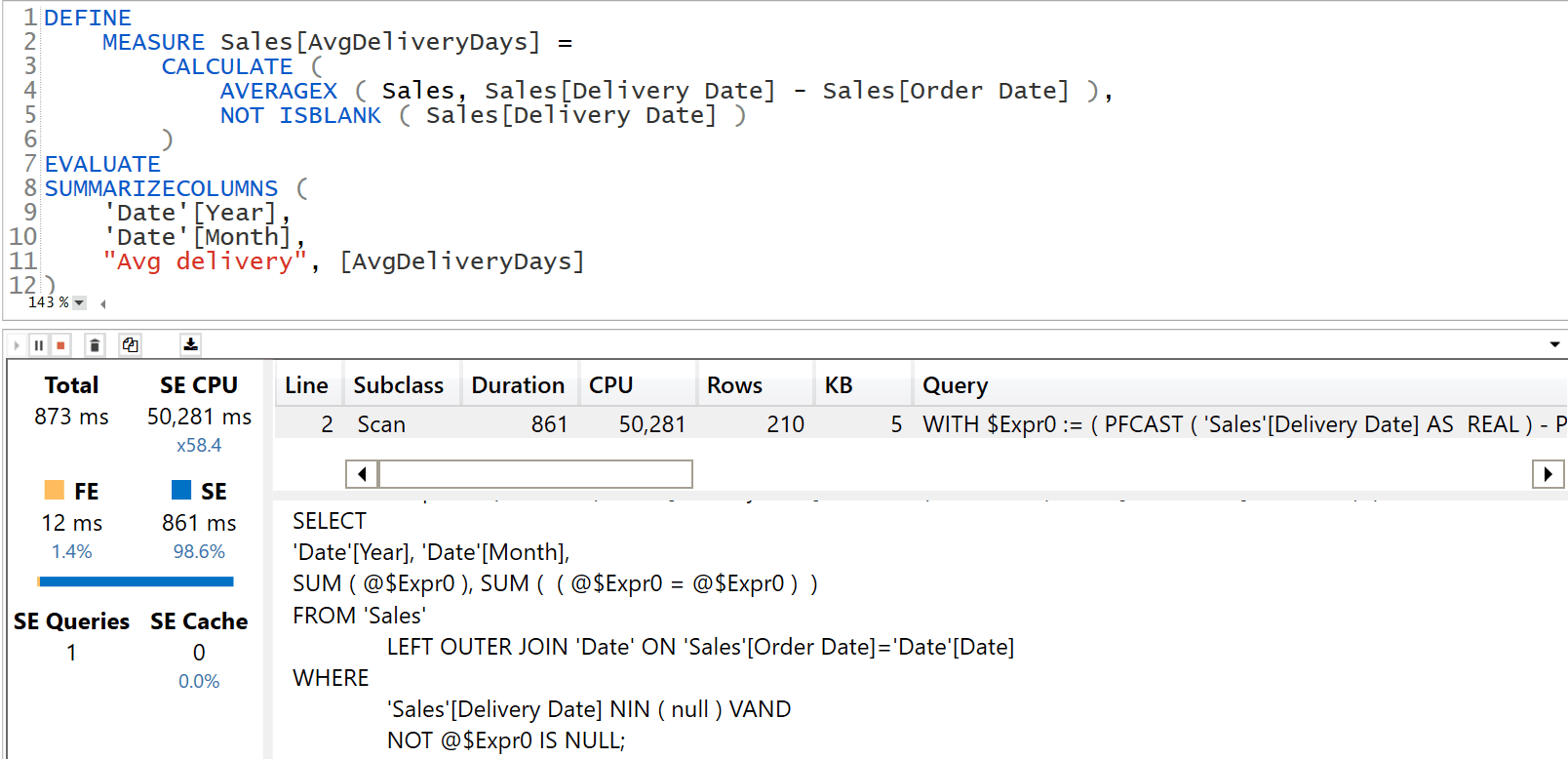
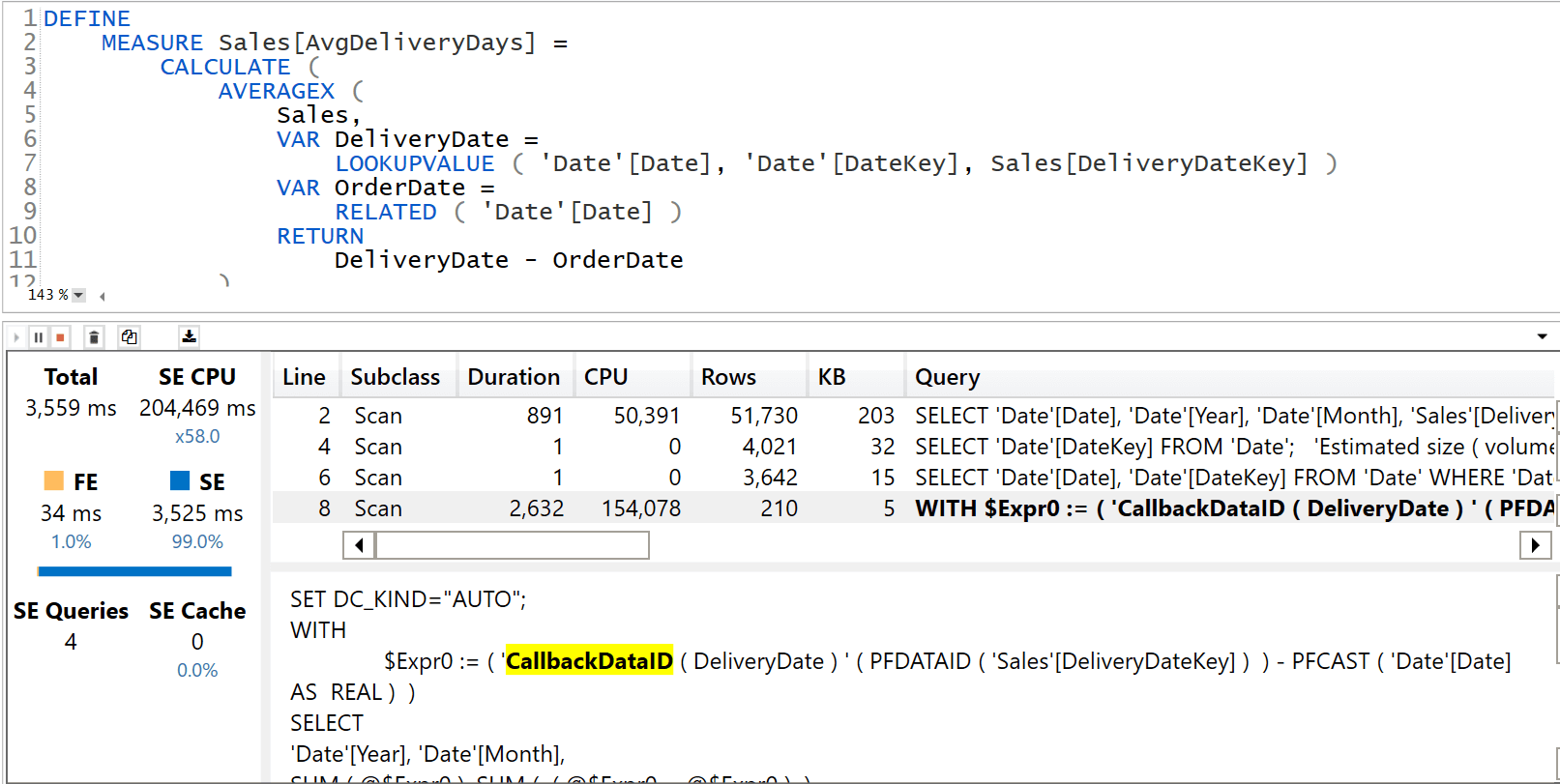
On the other hand, the query running on the model with an Integer requires 3.5 seconds. To make the comparison worse, 2.6 of these 3.5 seconds are required by a CallbackDataID that involves the usage of the Formula Engine (FE). As such, it does not take advantage of the cache.
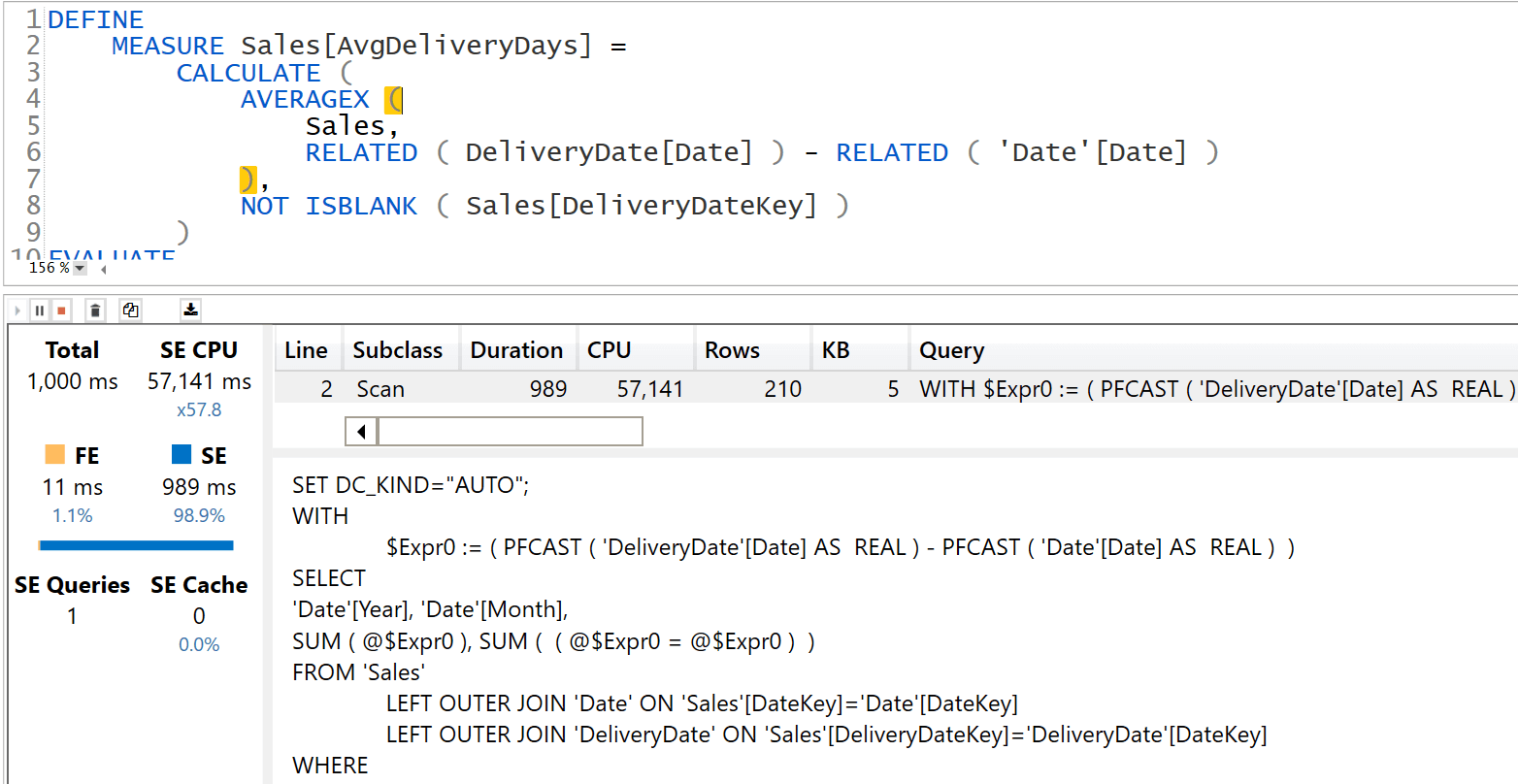
To make sure we are being thorough, it is worth noting that this scenario can be better optimized. Indeed, the complexity of the code is in the use of LOOKUPVALUE. We use LOOKUPVALUE because it would be extremely complex to use RELATED on an inactive relationship in a row context (see USERELATIONSHIP in calculated columns – SQLBI for more details on the topic). A possible solution is to create a new DeliveryDate table that contains the combinations of DateKey and Date, with a relationship with Sales based on Sales[DeliveryDateKey]. This new table is a technical table with the sole purpose of using RELATED instead of LOOKUPVALUE. As such, it is hidden.
The code would be simpler:
DEFINE
MEASURE Sales[AvgDeliveryDays] =
CALCULATE (
AVERAGEX (
Sales,
RELATED ( DeliveryDate[Date] ) - RELATED ( 'Date'[Date] )
),
NOT ISBLANK ( Sales[DeliveryDateKey] )
)
EVALUATE
SUMMARIZECOLUMNS (
'Date'[Year],
'Date'[Month],
"Avg delivery", [AvgDeliveryDays]
)
The execution time, albeit not as fast as the solution that relies on DateTime – it is 20% slower – is much better than the solution using LOOKUPVALUE.
Therefore, we can conclude that there are no differences in terms of performance and storage between using a Datetime or an Integer column. However, there is a difference in terms of usability of the column’s content.
By storing a Datetime, the value of the column is readily available in the Sales table. This makes it easier to author DAX code and to perform calculations based on the Date column. Any such calculation is more intricate if you store an Integer, because of the extra steps required to transform the Integer value into the related Date.
In the absence of calculations involving the dates, the choice is irrelevant. In case you perform calculations or if you want to stay on the safe side in case there might be future calculations, then using a Datetime is definitely a better choice.
Retrieves a value from a table.
LOOKUPVALUE ( <Result_ColumnName>, <Search_ColumnName>, <Search_Value> [, <Search_ColumnName>, <Search_Value> [, … ] ] [, <Alternate_Result>] )
Returns a related value from another table.
RELATED ( <ColumnName> )