 Alberto Ferrari
Alberto FerrariSometimes, we deal with cases where two or more entities of the same type have the same name. If we take the example of customers, the data model stores both the customer code and the customer name to correctly identify each customer. The customer code is what identifies each of the two customers with the same name as being unique.
The Contoso sample database contains many customers with the same name. For example, look at the following table: there are two customers named Jordan Allen. They have the same name but a different customer code. Indeed, they live in different states and their customer history is likely to be very different.

If we just leave the customer name in the table and remove all the columns that make them different, Power BI merges the two customers, showing misleading figures. Looking at the following matrix, the user may incorrectly conclude that the customer Jordan Allen purchased 810.94 USD worth of products. However, this never happened because that number is the sum of the purchases of two different customers with the same name.
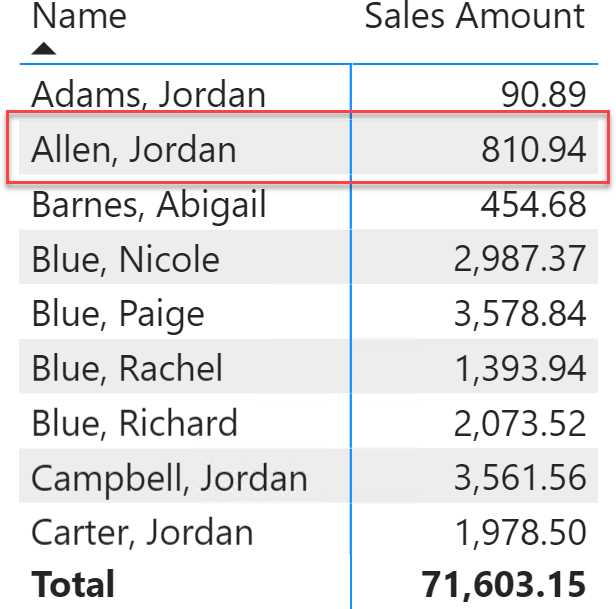
The query generated by Power BI groups by customer name. If two customers share the same name, then they are shown as a single customer.
One option to solve the scenario is to append the customer code to the customer name, to guarantee that customer names are always unique. Using the customer code is an effective technique, but the result is unpleasant to the eye because we pollute the name column with the customer code.
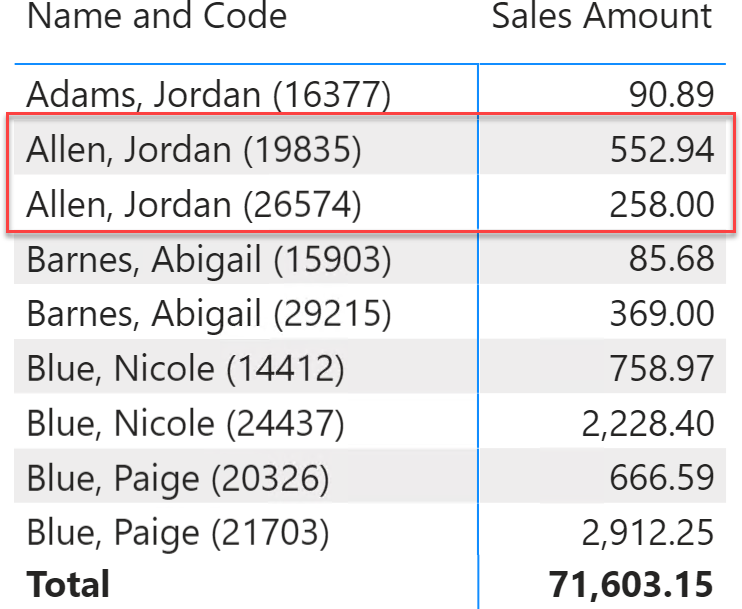
There is another technique that we can use to make the names unique, while keeping the visualization of the name the same. We can use the zero-width space, which is a very special kind of space character in the Unicode set.
Zero-width spaces are special characters that affect how to print words used in some writing systems. In this article, we are not interested in their usage for printing, but instead in their unique characteristic of being invisible to the eye. You can learn more at https://en.wikipedia.org/wiki/Whitespace_character. Among the many zero-width spaces, we chose the zero-width non-joiner Unicode 8204.
The idea is the following: if we add a zero-width space at the end of the second Jordan Allen, it looks the same as the first Jordan Allen, but it is different because his name contains the hidden space at the end. What if we have more than two customers with the same name? Well, DAX is there for us. We can author a new calculated column for the customer name, where we append to the original name a suitable number of zero-width spaces to guarantee that – no matter what – the customer name is unique.
To create the column, we must identify the customers with the same name, rank them using the customer code, and then add spaces: zero spaces to the first customer, one space to the second customer, two spaces to the third customer, and so on. In general, once we have the ranking position of the customer, we add as many zero-width spaces as its ranking position minus one. The Name Unique calculated column implements this technique:
Name Unique =
VAR CustomersWithSameName =
CALCULATETABLE (
SUMMARIZE ( Customer, Customer[Customer Code], Customer[Name] ),
ALLEXCEPT ( Customer, Customer[Name] )
)
VAR Ranking =
RANKX ( CustomersWithSameName, Customer[Customer Code],, ASC, DENSE )
VAR Blanks =
REPT ( UNICHAR ( 8204 ), Ranking - 1 )
VAR Result = Customer[Name] & Blanks
RETURN
Result
To human eyes, the result in the Name Unique column is identical to the original Name column. However, DAX sees the result differently because there are zero-width spaces at the end of the name of different customers with the same name. Indeed, the Name Unique column in the matrix produces the visualization below.
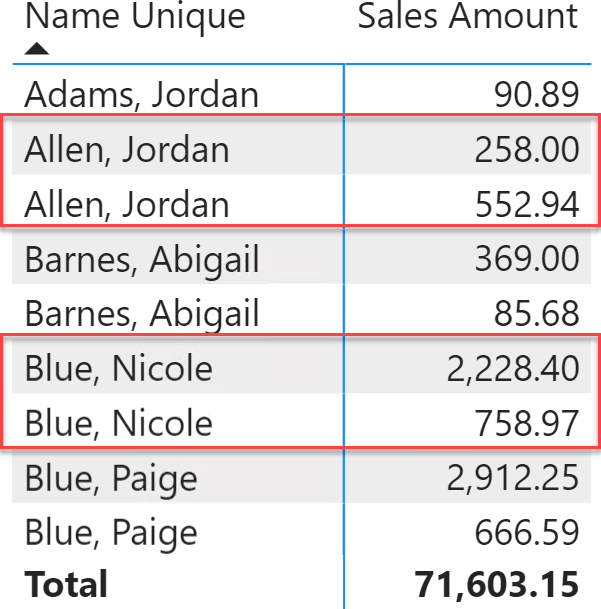
The highlighted customers with the same name are displayed in different rows, despite having the same name. The zero-width space appended to the customer name does not increase the visual length of the name itself. Indeed, the Contoso database contains 385 customers with no name. If we appended a regular space, the length of the last of those empty customers’ names would be enormous: 385 spaces. By using a zero-width space, the name still looks empty, even though the longest one has 385 characters.
To simplify the user’s browsing experience, it may be worth showing the Name Unique column, hiding the original Name column, and renaming them so that the user sees only a Name column containing the unique names. This way, the expected behavior of separating customers with the same name is the default behavior. That said, the original Customer[Name] column is still useful. For example, the original Customer[Name] column is necessary to check whether a customer name is empty or not. The Customer[Name Unique] column never contains an empty string, whereas Customer[Name] might contain an empty string.
This technique works just fine with most local cultures and languages. Be mindful that the zero-width space has a specific meaning in some languages. Therefore, it is worth checking that you can safely add a zero-width space at the end of a name in your specific culture without changing its visualization. However, if you can afford to use it, this technique opens up some exciting opportunities in Power BI that are not limited to just separating the names in a column. For example, this technique is useful to implement advanced sorting techniques in hierarchies, as we will show in a future article.