 Marco Russo
Marco RussoWhen you use VertiPaq Analyzer or the data management view (DMV) to get the size of the dictionary of a column (DISCOVER_STORAGE_TABLE_COLUMNS), you receive the size of the memory allocated for the dictionary of that column. After a refresh operation, this number could be significantly greater than the memory needed by the dictionary, misleading you on the actual size required by the dictionary.
How VertiPaq creates the dictionary
When you refresh a table, its content is read from the data source uncompressed. The data fills a segment in memory (1MB for Power Pivot and Power BI, 8MB by default in Analysis Services), and when it is completed, each column is compressed by the VertiPaq engine. For columns that have a dictionary (all the strings and usually many of the numeric ones), VertiPaq allocates an initial size of contiguous memory to store the dictionary, and it expands it as needed.
VertiPaq initially allocates 1MB for the dictionary of each column. At the end of the refresh operation, that size is still there, because the memory allocated is not trimmed down to the memory actually used. However, if VertiPaq restore an existing compressed database – which happens every time you open a Power Pivot or Power BI file – the allocation corresponds to the actual size of the dictionary.
Reading the correct dictionary size from Power BI
For example, consider the following table read by Power BI from a data source. There are only three columns, two of them with a string data type whereas the key is an integer.
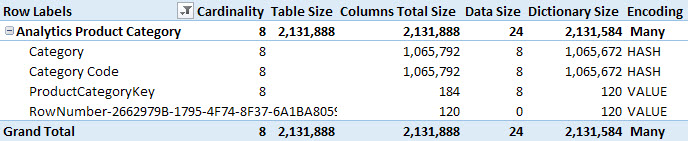
If you run VertiPaq Analyzer immediately after importing this data or refreshing the table, you will see the number in the following screenshot where every string column (Category and Category Code) has 1MB of RAM allocated for the dictionary size. This is even if the actual content of these columns is clearly much smaller than that.
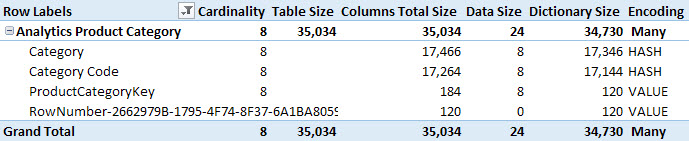
If you save the Power BI file, close it, and open it again, running VertiPaq Analyzer produces different results as you see in the following screenshot.
If you have a calculated table in the data model, it could be unaffected by the Refresh operation of the data model. This really depends on the dependencies that you have in the DAX expression of the calculated table. For example, the following expression creates a Categories table that is identical to the one imported from an external data source in the previous example.
Categories =
DATATABLE (
"ProductCategoryKey", INTEGER,
"Category Code", STRING,
"Category", STRING,
{
{ 1, "01", "Audio" },
{ 2, "02", "TV and Video" },
{ 3, "03", "Computers" },
{ 4, "04", "Cameras and camcorders" },
{ 5, "05", "Cell phones" },
{ 6, "06", "Music, Movies and Audio Books" },
{ 7, "07", "Games and Toys" },
{ 8, "08", "Home Appliances" }
}
)
The first time you create this calculated table, you will see the inflated value for the dictionary size of each column (1MB for each string column). If you close and open the file, the size of the string columns will be smaller – around 17KB each – as in the previous example. The DAX expression defining the Categories calculated table does not have dependencies on other tables. Therefore, these string columns will not increase by hitting Refresh over the data mode, but they will be rebuilt as soon as you apply any minimal change to the DAX expression – even just indenting the code for proper formatting is considered as a change in the formula.
In order to get correct dictionary measures from VertiPaq Analyzer, you have to connect VertiPaq Analyzer just after opening a Power BI file, without hitting Refresh or modifying any calculated table expressions. If this happens, then save the file, close Power BI, and open the file again in Power BI before running VertiPaq Analyzer again over it.
You can download the Power BI file at the bottom of this article and use VertiPaq Analyzer to check the dictionary size. At the beginning, you will see smaller values of the dictionary. Try to apply small changes to the DAX expression of the Categories calculated table, then refresh the VertiPaq Analyzer data and you will see inflated values of the dictionary size.
Reading the correct dictionary size from Power Pivot
If you use Power Pivot, you cannot use VertiPaq Analyzer directly. The easiest way to get the right numbers is to:
- Save the Power Pivot file
- Import the Power Pivot file in Power BI, copying the existing data and without any new process
- Run VertiPaq Analyzer over the new Power BI model
Because the model in Power BI is imported from the original in Power Pivot, you always see the correct dictionary size, as long as you do not hit the Refresh button in Power BI.
Reading the correct dictionary size from Analysis Services Tabular
Using Analysis Services Tabular, you might have a hard time reading the correct size for the dictionary. The problem is that you are probably considering a server that is supposed to run 24×7, so in ideal conditions a production server will never be in a condition where it loads the dictionary allocating the correct size. Moreover, there is increased complexity because of the different types of process actions you can run over tables and partitions.
The initial process of a new table will likely have a larger dictionary size, because of the memory allocation technique described before. The following actions guarantee that the memory allocated for the dictionary size is the minimum required:
- Detaching and then attaching a database: this operation does not affect other databases and corresponds to closing/opening Power BI as described before.
- Restoring a database: when you restore a database, the memory allocated is always optimal, just as when you detach and attach a database.
- Restarting the Analysis Services service instance: this operation impacts the availability of all the databases loaded on the same instance. You should be careful in doing that on a production server, as all the users would be affected. On Azure Analysis Services, this corresponds to Pause and Start the service.
- Restarting the server running Analysis Services: this operation impacts all the services and users connected to the same server. We mention this option only to be aware that after a server restart, you will not observe an increase in dictionary size.
- Only for integrated workspaces – closing and opening the solution in Visual Studio: please note that closing and opening the model window is not enough. The integrated workspace process starts when you open the solution in Visual Studio and is kept open even if you close the Model.bim window.
As you see, getting information from VertiPaq Analyzer could be misleading when running it over Analysis Services. However, the numbers reported by VertiPaq Analyzer are real. The overhead in memory allocation is there, and there is no way to make it disappear other than using the operations described above. On a big database, this overhead is usually not relevant, but you might want to save memory when you run small databases containing hundreds of columns.
In order to correctly interpret the dictionary size of a database running on a 24×7 server, you should also be aware that the dictionary size might increase over the required size. In fact, it is possible to observe that such overhead exists only in a few hash-encoded columns of a table, but not in all of them. Let’s consider the actions that generate this overhead:
- Database Process Full: always creates a new dictionary for hash-encoded columns in all tables
- Table Process Full/Data: always creates a new dictionary for hash-encoded columns in all tables
- Other operations: the dictionary size of each column increases (with an overhead) only if the column has a new value that was not in the dictionary before. Thus, the process operation by itself might not generate an increase in dictionary size, it depends on the data added to the table. Moreover, only columns with new values are affected.
All the scenarios where you have partial or incremental refresh of the data are subject to a mixed situation. For example, after the server has restarted to apply a service pack, certain columns have an optimal dictionary size, and others have an inflated dictionary size because they received new values during a Process Add or Refresh applied to a partition.
Conclusion
The dictionary size of a column might have additional space allocated in memory after a process operation. This overhead disappears when the column is read from a backup, when the database is attached, or when the service restarts. You should use VertiPaq Analyzer over Power BI only when you just opened an existing Power BI file. For Analysis Services, the situation can be more complex on a production server, so you should adapt the suggestion provided in this article to your scenario.