 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariHow many times have you heard an executive request a panel with the company’s sales data in real time? How frequently has this single request – which is more often a preference than an important business requirement – affected the overall architecture of your analytical solution?
In the Power BI world, requirements for real time often drive the creation of a pure DirectQuery model, with no aggregations to avoid data latency. This choice is incredibly expensive: the computational cost of each individual query is borne by the data source, which is often a relational database like SQL Server. On top of its cost, with this approach you will face scalability, performance, and modeling issues. Indeed, the relational database on top of which DirectQuery runs is mostly designed for transactional processing instead of being optimized for the workload of analytical processes. Optimizing the model is both difficult and expensive. Finally, using DirectQuery creates specific modeling constraints and the need for modeling workarounds to obtain good performance.
Creating an entire model using DirectQuery for the sole purpose of achieving a few real-time dashboards is definitely excessive. The primary scenario where relying on DirectQuery makes sense is when it is not feasible to import data quickly enough to satisfy the latency requirements for the majority of the reports. When the entire model can be in import mode, and a small number of dashboards require DirectQuery, there are better options available.
In this article, we show you how to isolate the requirement for real time and evaluate whether you can extend an Import architecture by using a push dataset instead of applying DirectQuery to the entire model, thus also affecting reports that can tolerate update latencies in the hours or days.
This article does not go into detail. It is intended to be only an introduction. You can find much more information and a step-by-step guide in the following article: Implementing real-time updates in Power BI using push datasets instead of DirectQuery.
The requirement for real time
Many executives would like to have a screen in the company lobby, where all can see the company’s sales updated in real time. You stare at the screen, mesmerized by the numbers changing.
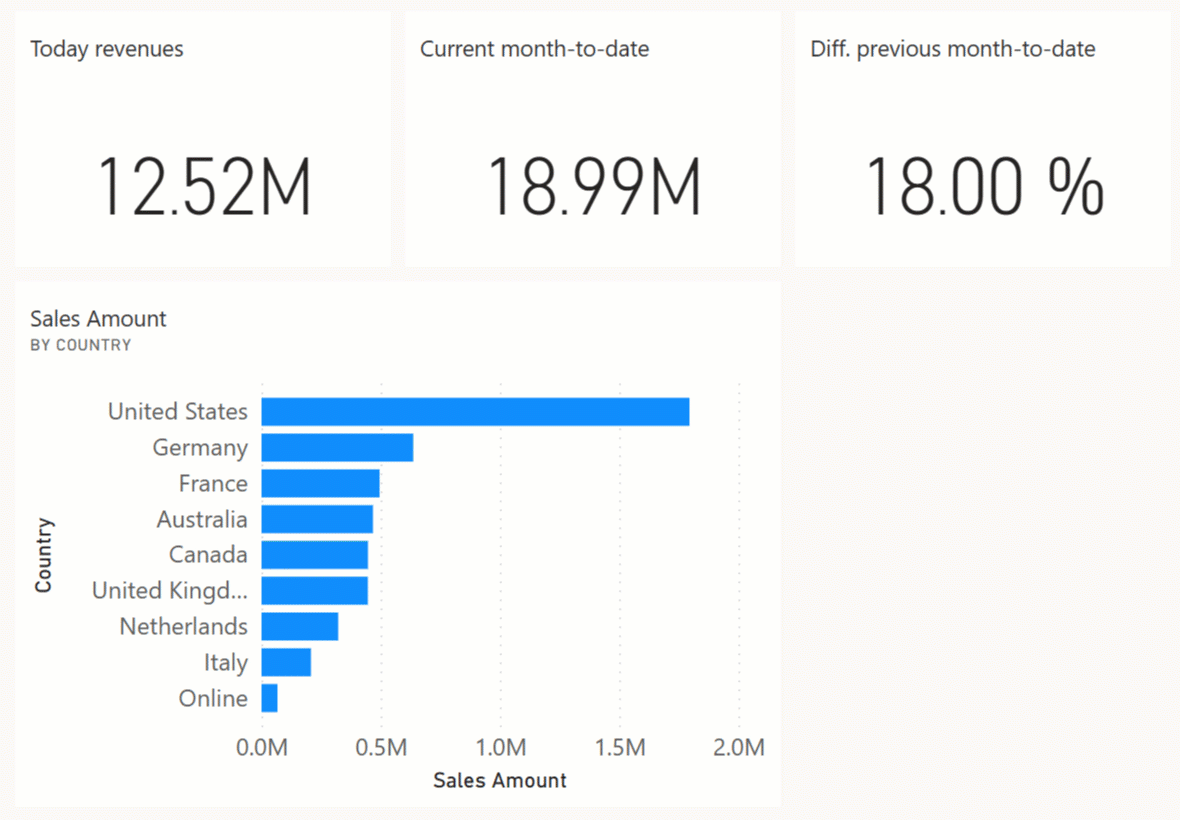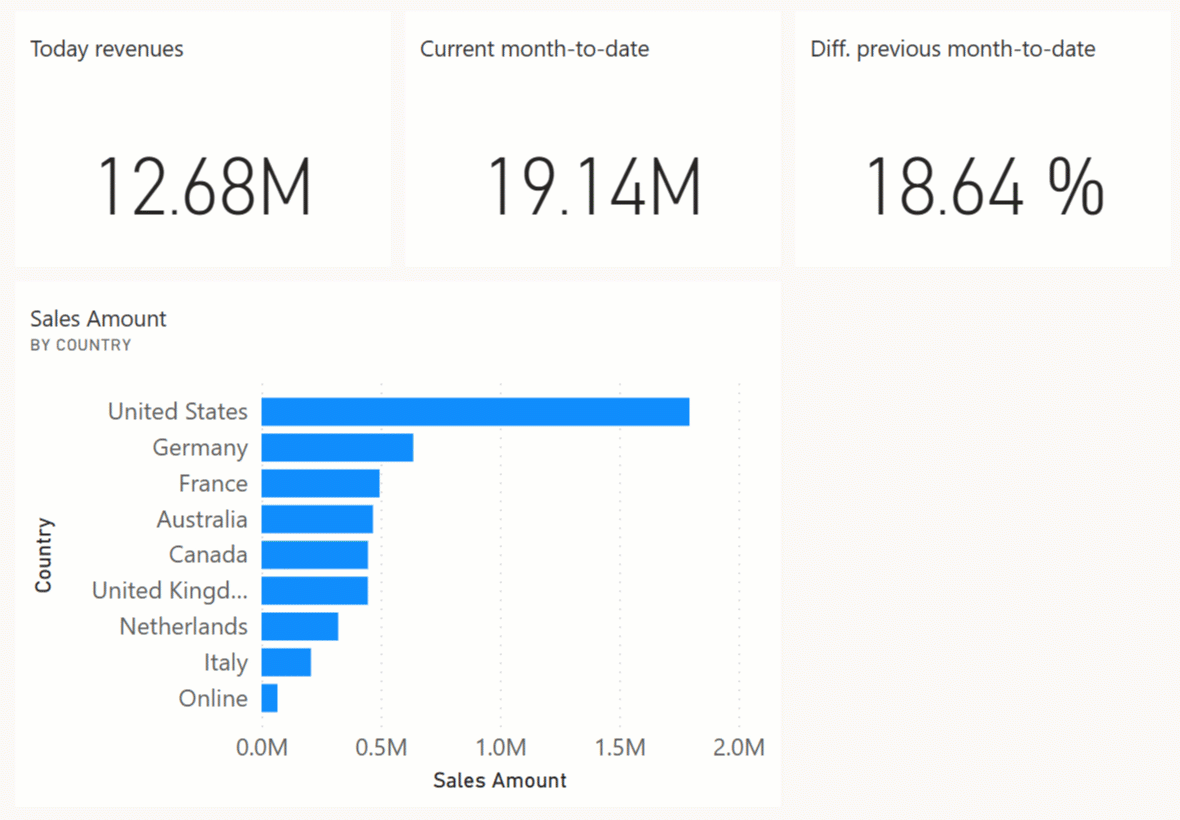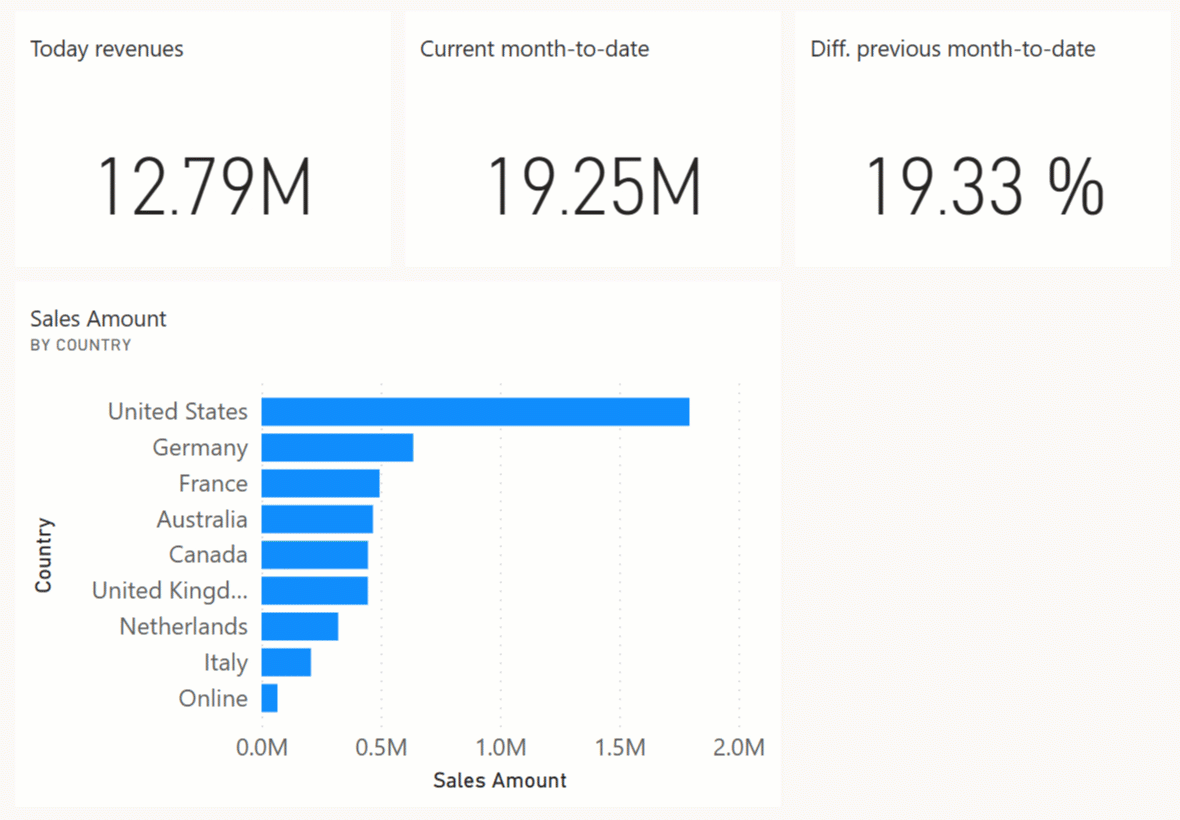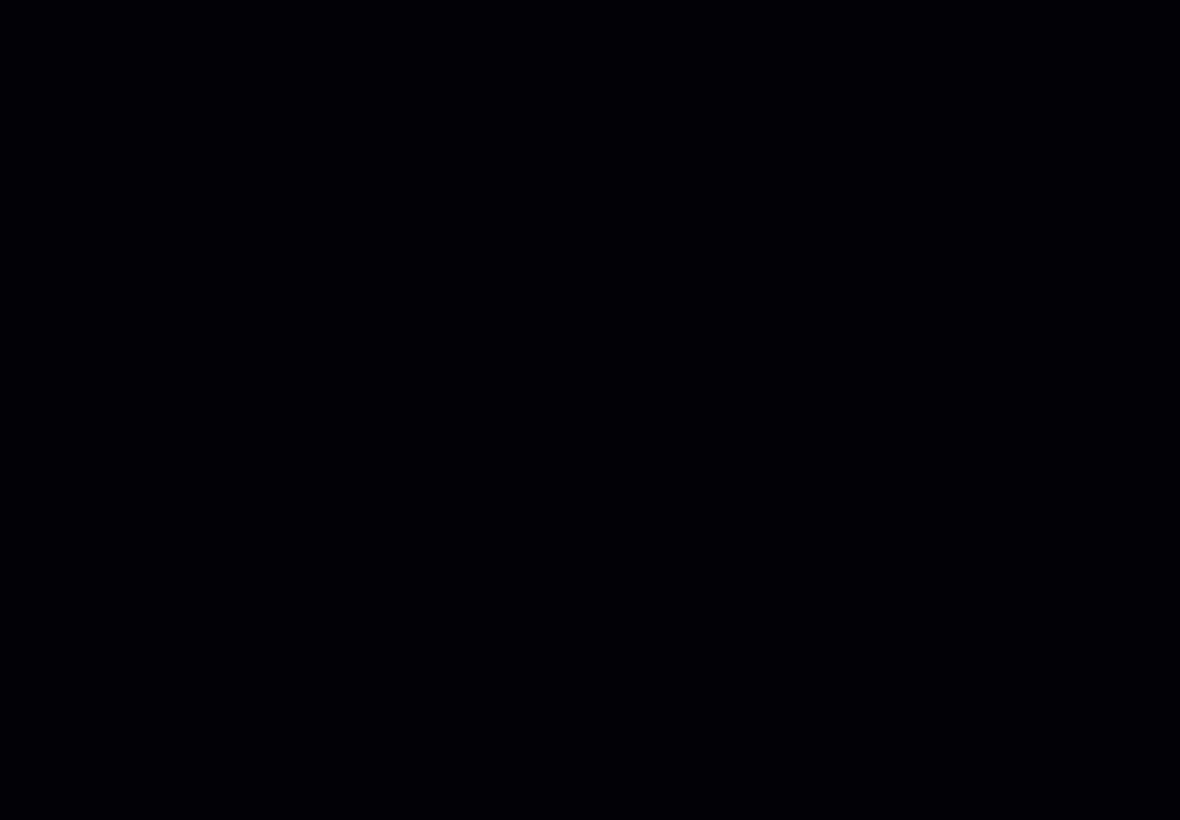
Before judging this as a sin of vanity, consider that this type of information can be a real motivational lever for those working in the company. However, if your solution enables the navigation on hundreds of reports, the overall architecture should not be affected by the desire for real time. If most reports We can evaluate an ad hoc solution for a small number of real-time reports.
The first step in checking whether a push dataset is a viable solution is to isolate the information required to build the dashboard. If you look at the dashboard above, you can easily notice that it is using a small subset of the measures and table/columns available in the overall model – namely:
- Country for each store
- Date, which applies different filters to cards and charts
- Sales Amount, plus derived measures that use time intelligence filters
The original Contoso dataset contains many more attributes: products, customers, and more. However, in the real-time dashboard those details are not necessary. Regarding the time frame needed, the report shows today’s sales, sales month-to-date and a comparison between this month’s sales and the previous month’s. Therefore the data required for the dashboard needs to cover at least these entire time periods. Finally, there is no need to store individual transactions: because Date and Store are the only dimensions required, we could save space and simplify the business logic by creating a specific structure with just one row for each store and date.
We want to create this new structure as a push dataset. We therefore design the architecture with two distinct models:
- Contoso: a regular model with imported tables and a scheduled refresh.
- Contoso RT: a subset of the Contoso model updated in real time, that has data for only a few tables and at a lower granularity for historical data.
By using a push dataset, it is possible to send new transactions to the dataset without the waiting time and the limitations of an import dataset refresh. In the end, we obtain two different datasets that can be developed, maintained, and refreshed independently. Although this makes it seem like we are doubling the effort to build the model, we are actually greatly simplifying it. Indeed, the Contoso model can be an Import model without the limitations of DirectQuery. The Contoso RT model is a push dataset. As such, its implementation requires some more effort, but its simple structure makes it a viable task. Besides, the Contoso RT model can be created in a semi-automatic way with the aid of tools that we introduce in the next part of the article.
Introducing push datasets
A push dataset is a Power BI dataset that can be created and populated only by using the Power BI API. However, the absence of a good user interface to create a push dataset limited its adoption to cases where a single table was populated with data streaming in real time.
Push datasets are often confused with streaming datasets. A streaming dataset is a dataset that is updated in real time, with the data kept in a temporary cache used only to display the visuals. There is no underlying database in a streaming dataset.
A push dataset is a regular database that is updated by pushing data into it through the Push API – instead of pulling data from data sources at refresh time. A push dataset is a real database, the main difference with a regular import model being the way it is populated. You can find a more complete description of the different real-time datasets in the Microsoft documentation.
The latency in import models depends on how frequently you refresh the data. An import model is as current as the last time it was refreshed. A push dataset is updated whenever an external application calls the Push API to send new data. Therefore, its latency depends on the code written by the developer: the sooner you push new data into it, the sooner the push dataset is up to date.
There are, however, limitations in size and throughput volume. Each table can have up to 5 million rows and up to 75 columns, while the entire dataset can have up to 75 tables. You can push up to 10,000 rows in each request, but there is a limit of 120 POST rows requests per hour for a dataset if the table contains more than 250,000 rows. In other words, you can push new rows every 30 seconds on average. Another important limitation is that we can add up to 1 million rows per hour to a single table. You can see a more complete description of these limits here: Implementing real-time updates in Power BI using push datasets instead of DirectQuery.
When you design a push dataset, you need to keep these limitations in mind. Indeed, the main idea of using push datasets for real-time dashboards is to create a dataset that is initialized at the beginning of the day, with historical data summarized at a granularity that does not exceed the limits. Once initialized, the dataset receives new data during the day through the Power BI REST API.
For example, consider a Contoso database with 10 million rows in the Sales table for 3 years of historical data. On average, there are 10,000 new rows per day, with peaks of 50,000 new rows per day. While the volume of new daily transactions is compatible with the boundaries of a push dataset, we cannot load the entire Sales table with 10 million rows. However, if we populate the Sales table with historical data grouped by Store and Date, with 100 stores we need 100,000 rows to populate a 3-year history at the store granularity. We could further limit the size by loading fewer rows, for example by limiting the historical depth. Therefore, we initialize the Sales table with 100,000 rows. Then, we load transactions occurring during the day, meaning between 10,000 and 50,000 rows per day.
The main data store is the Contoso Tabular dataset. We create the new Contoso RT dataset by using the model structure of Contoso and populating the real-time dataset with data extracted from the main database. Most of the steps required to create the Contoso RT model can be automated by leveraging the Power BI Push Tools – a set of tools designed specifically to create a push dataset out of an existing model.
Implementing a push dataset by copying an existing model
The implementation of the push dataset requires the following steps:
- Define and deploy the data model as a push dataset.
- Populate the model with the historical data copied from the imported dataset.
- Write the new transactions in the Sales table, grouping the rows in a single POST rows call every 30 seconds.
The first two steps do not require any programming effort. Instead, you can rely on the Power BI Push Tools we mentioned earlier. That open source project includes the following parts:
- A library that simplifies the access to the Power BI API libraries to create and maintain a model deployed as a push dataset.
- A command-line tool to create, maintain, and test a push dataset.
- A PowerShell cmdlet with the features of the command-line tool.
Creating the model for the push dataset
The Power BI Push Tools can transform a Tabular model into a push dataset. We want to create the Contoso RT push dataset as a copy of the Contoso dataset, where we will populate only the tables that are required for the real-time dashboard. We can remove the tables that are not used, or we can keep them in the model without populating them. Because the push dataset does not support all the features available in a regular dataset, the tool provides features to analyze and validate a model before the conversion.
Starting from the Contoso model in Power BI, we can use Tabular Editor to extract the file describing the model structure. After we save the file as Contoso.bim, we can check whether there are elements that are not compatible with a push dataset. For example, this is the output when using the PowerShell cmdlet:
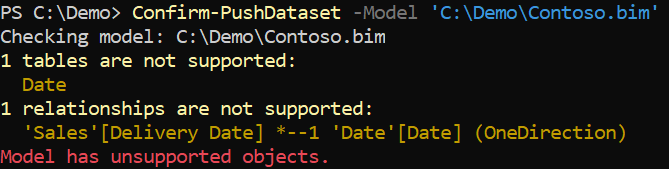
The tool detected issues that require fixing; a task that you can accomplish by using Tabular Editor to remove or fix unsupported objects. Once the model is corrected, running the tool again allows you to find out that the model.bim file is compatible with the push dataset limitations:

At this point, the Contoso.bim file can be deployed as a push dataset. A Tabular model cannot be deployed as a push dataset by using the regular tools. A push dataset must be defined by using a specific Power BI API that does not use the TOM library. The Power BI Push Tools can translate the content of a Tabular model – stored in the Contoso.bim file – into a corresponding request to the Power BI API that produces an equivalent model. For example, this is the output of the publish operation executed through the tool:

Populating a push dataset
After being created, the push dataset is immediately available though all the tables are empty. We want to initialize the tables by copying data from the Contoso dataset, which is refreshed daily. Because the structure of the two models is almost identical, we can copy the entire content of tables like Dates and Store, and we can summarize the content of the Sales table by grouping historical data by day and store.
The Power BI Push Tools offer a feature to read the result of a DAX query and push the rows into the corresponding table of a push dataset. The destination table and columns are inferred from the column names of the query results. For example, this is the PowerShell cmdlet that executes a script with a list of DAX queries populating the tables in the push dataset:

The content written in the three tables (Store, Dates, and Sales) is the result of the following three DAX queries included in the PopulateContoso.dax file. You might notice that the Date table is written in a Dates table in the push dataset, because Date cannot be used as a table name in a push dataset, and the Sales table is preaggregated at the required granularity:
EVALUATE Store
EVALUATE
SELECTCOLUMNS(
'Date',
"Dates[Date]", 'Date'[Date],
"Dates[Day of Week Number]", 'Date'[Day of Week Number],
"Dates[Day of Week]", 'Date'[Day of Week],
"Dates[Day of Week Short]", 'Date'[Day of Week Short],
"Dates[End of Month]", 'Date'[End of Month],
"Dates[Month Number]", 'Date'[Month Number],
"Dates[Month]", 'Date'[Month],
"Dates[Month Short]", 'Date'[Month Short],
"Dates[Quarter]", 'Date'[Quarter],
"Dates[Working Day]", 'Date'[Working Day],
"Dates[Working Day Number]", 'Date'[Working Day Number],
"Dates[Year]", 'Date'[Year],
"Dates[Year Month Number]", 'Date'[Year Month Number],
"Dates[Year Month]", 'Date'[Year Month],
"Dates[Year Month Short]", 'Date'[Year Month Short],
"Dates[Year Quarter Number]", 'Date'[Year Quarter Number],
"Dates[Year Quarter]", 'Date'[Year Quarter]
)
ORDER BY
Dates[Date] ASC
EVALUATE
SUMMARIZECOLUMNS (
Sales[Order Date],
Sales[StoreKey],
"Sales[Quantity]", SUM ( Sales[Quantity] ),
"Sales[Net Price]",
DIVIDE (
SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ),
SUM ( Sales[Quantity] )
),
"Sales[Unit Cost]",
DIVIDE (
SUMX ( Sales, Sales[Quantity] * Sales[Unit Cost] ),
SUM ( Sales[Quantity] )
),
"Sales[Unit Price]",
DIVIDE (
SUMX ( Sales, Sales[Quantity] * Sales[Unit Price] ),
SUM ( Sales[Quantity] )
)
)
Once the Contoso RT push dataset is populated, any report produces the same result you would get from the Contoso dataset – as long as you query the model by store and date. Filtering or grouping by product or customer attributes would not work, because that level of granularity is not available in the push dataset. The push dataset initialization should be the first operation early in the morning, just after the refresh of the Contoso dataset. The final step is to add the new transactions created during the day.
Writing new transactions into a push dataset
To complete this last step, the Power BI Push Tools are not helpful. This is despite the fact that the Power BI Push Tools come with a feature to simulate the generation of new transactions, writing them into the push dataset. This way you can produce a proof of concept for your data model without requiring the help of a developer:
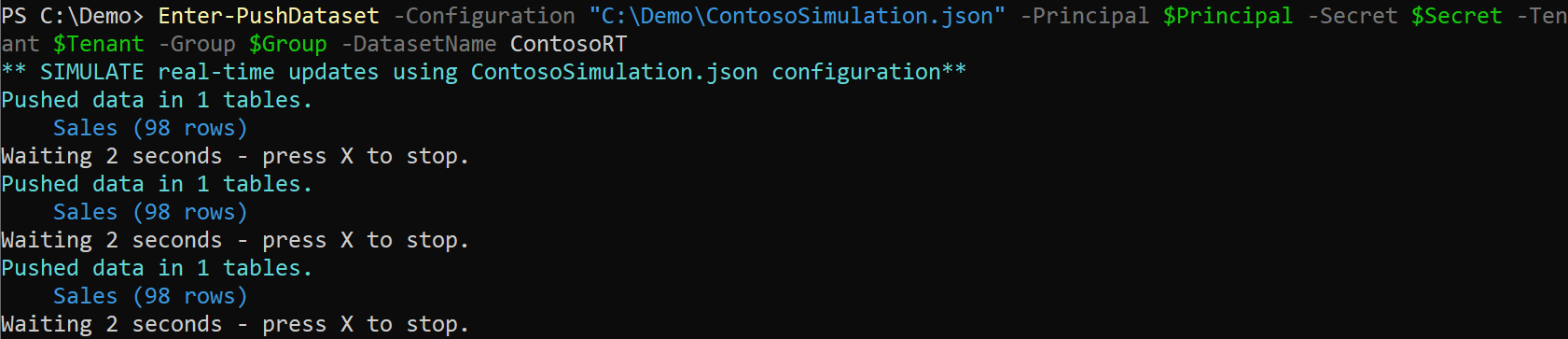
Once you show a complete demo (with fictitious data for the real-time transactions), it should be easier to get approval for a real implementation.
In order to implement the solution for real, you have several options:
- Asking a developer to implement a service that intercepts new transactions on your transactional system and sends them straight to the push dataset. This would be the ideal solution to avoid expensive polling requests on the data source.
- Implementing a Power Automate flow that polls the data source every 30 seconds, looks for new transactions, and writes them on the push dataset.
Power Automate is a simpler solution, as it does not require developer skills to call the Power BI API and to authenticate the service requests. In the first solution, the developer must create a service that correctly authenticates with the Power BI service to use the Power BI REST API. In our experience, the authentication process could be the most complex part. More details on the topic are available in this video and article here: Creating a service principal account for Power BI API – SQLBI.
While involving a developer might sound like an expensive proposition, if you want to avoid a scalability issue, it is the best option. From an architectural perspective, capturing the new transactions in an inexpensive way is a key element of this architecture, and it cannot be generalized. , it could be an extension of the middle tier, a trigger on a database, or an event defined in an existing system. The more expensive operation is the polling technique, which could be necessary if none of the other options are achievable.
Analyzing licensing and development costs
We mentioned earlier that the real-time dataset can be an effective solution to obtain the best result at a minimal cost. It is now time to go into more detail about the economical side of this solution.
First of all, in terms of licensing the good news is that push datasets are available on both Power BI Pro and Power BI Premium, with the same set of features and limitations. Push datasets do not require Premium, even though Power BI Premium might present an advantage to automate the daily initialization process.
Because the push dataset is derived from a regular dataset, the maintenance of the original dataset might require updates to the push dataset. However, as long as the requirements for a real-time dashboard do not involve adding more data, you just have to make sure that the DAX queries used for the push dataset initialization are not impacted by the changes in the original dataset; you also want to check that the measure expressions do not need to be updated in the push dataset.
Regarding the development cost: it is hard to estimate because it really depends on the existing infrastructure. However, a C# developer with good knowledge of Azure, .NET Core, and Microsoft Authentication Library should be able to use the Power BI API without any more previous experience – it is just a REST API, after all. The development time could be within two to five days in the most common scenarios. Clearly, this is a rough estimate and it depends on many other factors – but the point is that we are not talking about months of work. Just make sure the developer has the skills required, because the authentication part is the hardest skill to find.
As you see, we have analyzed the additional costs introduced by the push dataset. You should put these costs in perspective and make sure you balance them out with the huge savings introduced by the push dataset, because the main model needs to not be in DirectQuery. An import model is easier to build, maintain, and optimize, if compared with a DirectQuery model. Therefore, you have to spend time and money to build an additional model, all the while saving time and money because you can use an import model for the main database.
Conclusions
Creating a real-time dashboard in Power BI is possible with a minimal investment and great results in terms of low latency and good scalability. It does not require DirectQuery. It entails a small development effort, but it represents an investment that can satisfy a hard requirement (real-time updates for a small number of dashboards and reports) without a larger impact on the overall architecture of an analytical solution.
By using Tabular Editor and Power BI Push Tools, you can derive a push dataset from a regular dataset. The push dataset is usually a subset of the original dataset and keeps dependencies on its source rather minimal.
Let us repeat again why this could be a good architecture: No changes to the original model, minimal dependencies (only columns/data imported), need to synchronize the model only if something important changes in the measures. If you want to create a proof of concept, read and download the sample content of this article: Implementing real-time updates in Power BI using push datasets instead of DirectQuery.