 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariLike all the functions of the ALL* family, ALLEXCEPT can offer two different behaviors: it can be used as a table function, or as a CALCULATE modifier. ALLEXCEPT is seldom used as a table function. ALLEXCEPT is mostly used along with CALCULATE to remove all filters from a table, except for some columns.
In DAX, there are basically two patterns available to remove all the filters from a table except for some columns:
UsingAllExcept :=
CALCULATE (
[Sales Amount],
ALLEXCEPT (Customer, Customer[Continent] )
)
UsingAllValues :=
CALCULATE (
[Sales Amount],
ALL ( Customer ),
VALUES ( Customer[Continent] )
)
The first measure uses ALLEXCEPT, the second one uses the combination of ALL and VALUES. Despite looking identical in their semantics, the two techniques result in different behaviors. Using ALLEXCEPT is more likely to result in errors, because it is sensitive to the external filter context due to ALLEXCEPT being used as a CALCULATE modifier.
Moreover, DAX introduced REMOVEFILTERS in 2019 which is an alias for ALL when used as a CALCULATE modifier. It results in more readable code. UsingRemoveFiltersValues in the next code is semantically equivalent to UsingAllValues:
UsingRemoveFiltersValues :=
CALCULATE (
[Sales Amount],
REMOVEFILTERS ( Customer ),
VALUES ( Customer[Continent] )
)
In most scenarios, the pair REMOVEFILTERS/VALUES is what you need to implement the semantic of a measure. You should consider ALLEXCEPT as a CALCULATE modifier in more advanced cases, such as removing circular depencies in calculated columns. This is explained in Understanding circular dependencies in DAX – SQLBI.
Let me elaborate on the topic with an example. The following report shows the sales amount sliced by continent and country, along with a PercOverContinent measure that shows the percentage of the country over the total of the continent.
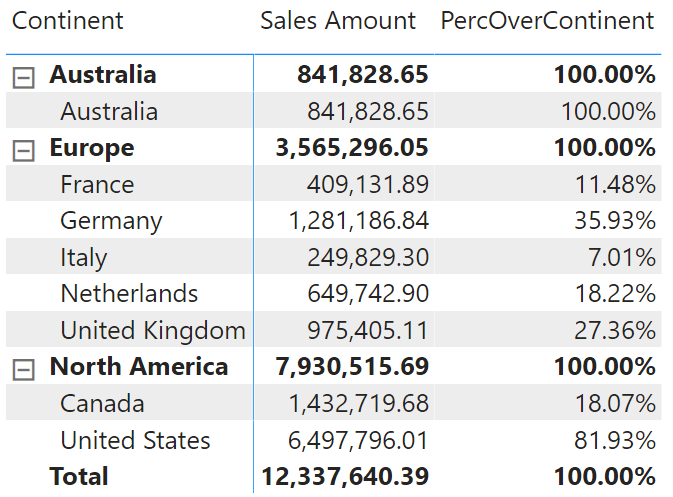
In order to compute PercOverContinent, we need to divide Sales Amount (that is, the Sales Amount measure in the current filter context) by the same measure in a filter context where we remove all filters from the Customer table, except for the Continent column. A possible implementation is the following:
PercOverContinent :=
VAR SelSales = [Sales Amount]
VAR ConSales =
CALCULATE (
[Sales Amount],
ALLEXCEPT (
'Customer',
'Customer'[Continent]
)
)
VAR Result =
DIVIDE ( SelSales, ConSales )
RETURN
Result
You can author the same measure in different ways, for example by using REMOVEFILTERS on Customer[Country], even though that would result in a different calculation. Indeed, by using ALLEXCEPT you create a measure that works when you slice by any column in the Customer table, always retaining the filter on Continent only. For example, the PercOverContinent measure produces the percentage of State over Continent, when you slice by Continent and State.
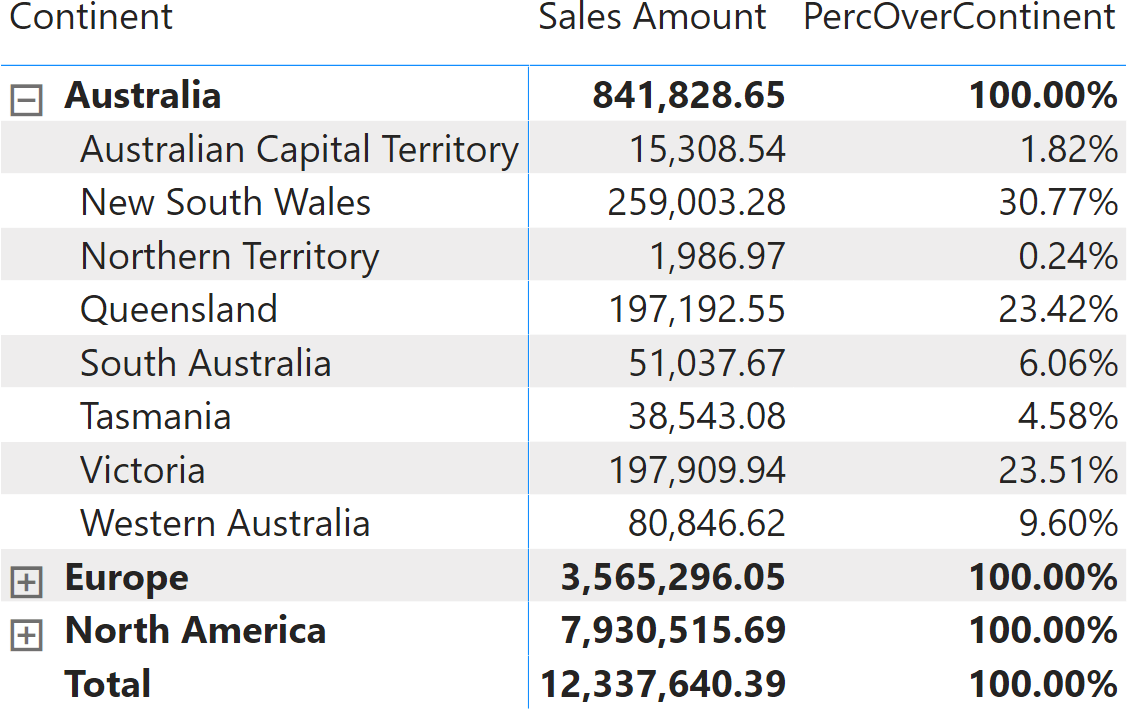
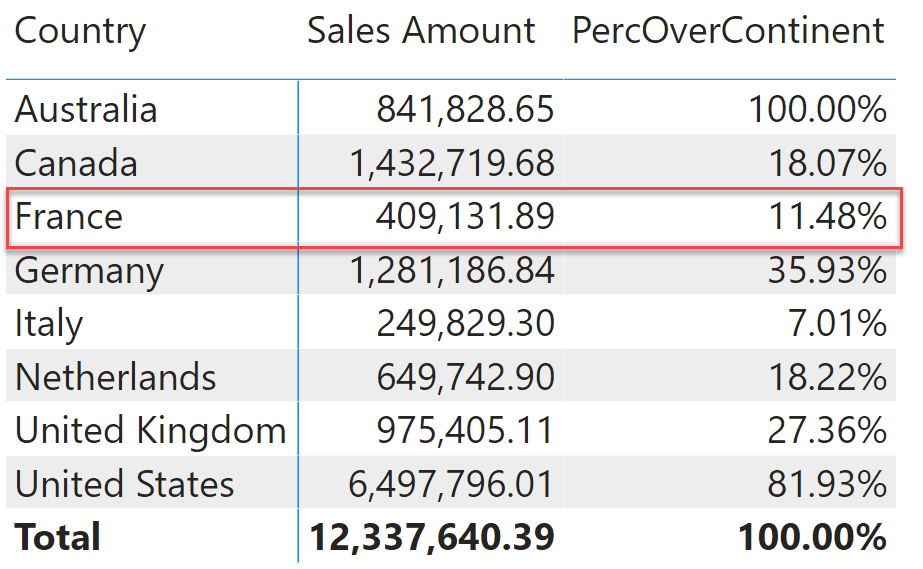
Despite working in this specific report, the PercOverContinent measure is written in a fragile way. In order to understand the problem, let us go back to the previous report that slices by Country. In the next figure, look at the percentage shown for France: it is 11.48%.
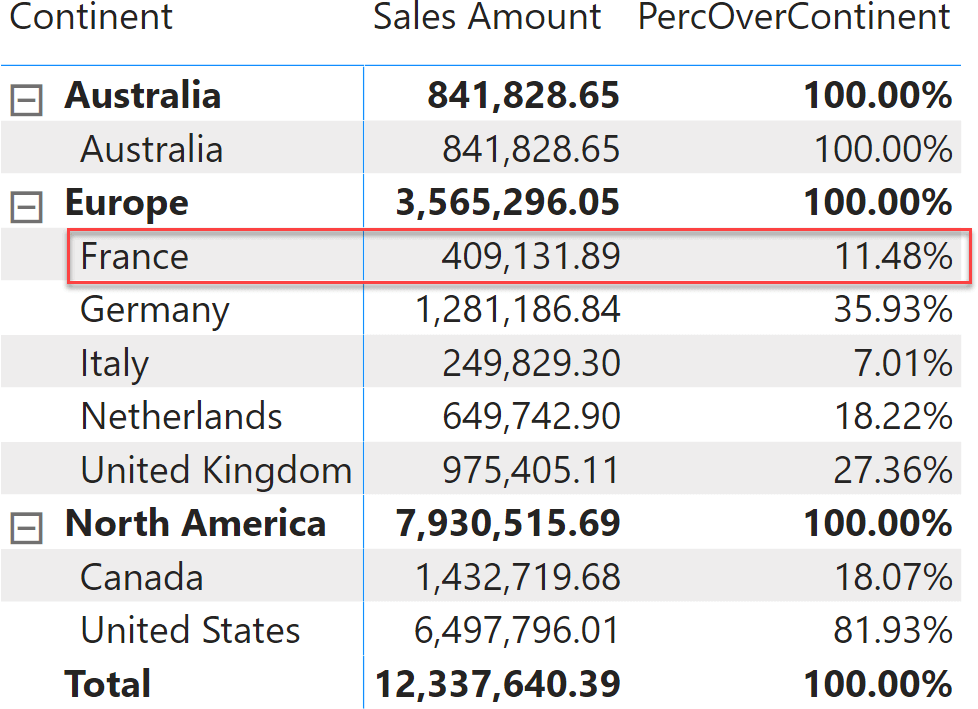
The value is correct: France represents 11.48% of sales against the total of Europe. Nonetheless, if we remove the continent from the report, the number suddenly changes to 3.32%.
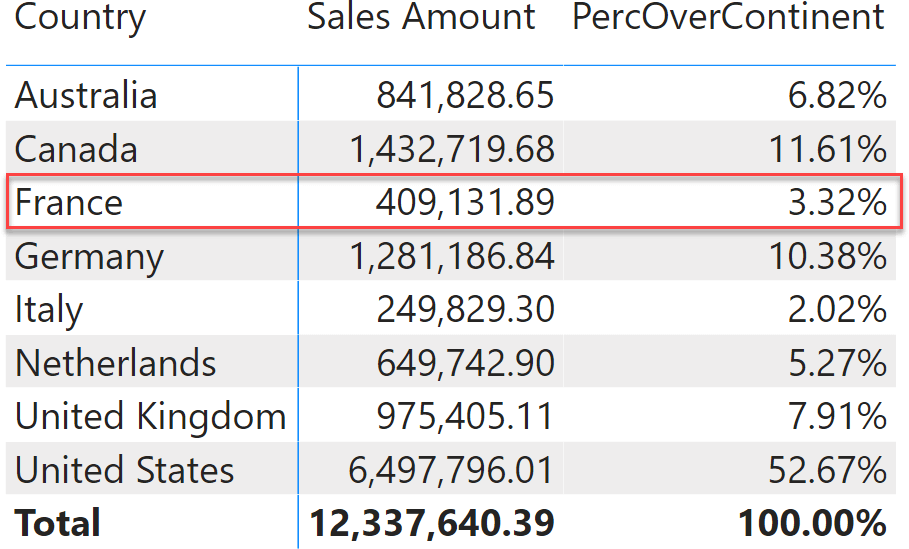
Indeed, by using ALLEXCEPT we created a measure that works if and only if the report includes the Continent column. If the report does not place a filter on Continent, the measure stops working. Doing the math, you discover that 3.32% is the percentage of France against the total sales all over the world. The filter on Europe disappeared at the denominator, despite us explicitly asking – by using ALLEXCEPT – to keep that filter.
To understand the reason why the measure does not work, we must focus on the filter context of the cell for France. We specifically look at the difference between the cell where it is working and the one where it is not.
When the measure is working as expected, the filter context contains both the Continent (Europe) and the Country (France).

When ALLEXCEPT is applied as a CALCULATE modifier in the denominator, ALLEXCEPT removes all the filters from the Customer table (there are two filters) except for a filter on Continent (there is one filter for the continent). Therefore, ALLEXCEPT removes the filter from Country but leaves the filter on the continent untouched. As a consequence, the denominator computes the sales in Europe as expected.
The scenario where the formula computes the wrong value (3.32%) is different. In the cell computing the inaccurate result, the filter context does not contain a filter over Customer[Continent]. This happens because we removed the continent from the matrix. Therefore, the filter context contains only a filter for Country.

In this scenario, when ALLEXCEPT is applied it removes all the filters from the Customer table, except for a filter on Continent. It turns out that there are no filters on Continent. Therefore, ALLEXCEPT removes all the filters, leaving an empty filter context. As a consequence, the value computed at the denominator is not the value of Sales Amount for Europe, but the grand total of Sales Amount for all the customers.
It is common for DAX newbies to forget that ALLEXCEPT, as a CALCULATE modifier, does not introduce new filters. It can only remove existing ones. If there are no filters on Customer[Continent] when ALLEXCEPT is invoked, there will be no filters after ALLEXCEPT has done its job.
If you want to remove all filters from a table except for some columns, a safer method is to rely on the pair REMOVEFILTERS/VALUES. REMOVEFILTERS (or ALL) removes all the filters from the table; VALUES evaluates the values of a column as visible in the current filter context, and applies the result as a filter:
PercOverContinent :=
VAR SelSales = [Sales Amount]
VAR ConSales =
CALCULATE (
[Sales Amount],
REMOVEFILTERS ( 'Customer' ),
VALUES ( 'Customer'[Continent] )
)
VAR Result =
DIVIDE ( SelSales, ConSales )
RETURN
Result
When evaluated for France, VALUES returns “Europe” because Customer[Continent] is cross-filtered by the explicit filter present on the Customer[Country] column. Therefore, ALL removes any filter from the Customer table – including a filter on the Continent, if present. VALUES restores the filter on the Continent column. It is worth remembering that VALUES is not a CALCULATE modifier. VALUES always applies its filter to the filter context, because it is a table function. Since the result of VALUES is a table containing “Europe”, the resulting filter filters the continents visible in the selection, regardless of the continent (Europe) being already present in the filter context or not.
You can use VALUES when you need to retain a filter on a single column. If you need to keep a filter on multiple columns, you can use SUMMARIZE instead of VALUES to build a suitable table that contains the columns you want to retain in the filter context.
As an example, to compute the percentage of the city against the state you must retain the filter on three columns: State, Country and Continent. This can be achieved with the following code:
PercOverState :=
VAR SelSales = [Sales Amount]
VAR StateSales =
CALCULATE (
[Sales Amount],
REMOVEFILTERS ( 'Customer' ),
SUMMARIZE (
'Customer',
'Customer'[Continent],
'Customer'[Country],
'Customer'[State]
)
)
VAR Result =
DIVIDE ( SelSales, StateSales )
RETURN
Result
A measure written using ALL/VALUES works regardless of the columns used in the report. As such, it guarantees a correct result for a measure whose semantic is a ratio over a specified column. This is not to say that you should not use ALLEXCEPT at all. There are scenarios where ALLEXCEPT makes sense and works perfectly fine. Mastering DAX requires you to understand well how the filter context is manipulated by the different functions available in DAX, so that you can write sound and strong code that works on any report.
NOTE: a previous version of this article written in 2016 is available here.
Returns all the rows in a table, or all the values in a column, ignoring any filters that might have been applied.
ALL ( [<TableNameOrColumnName>] [, <ColumnName> [, <ColumnName> [, … ] ] ] )
Returns all the rows in a table except for those rows that are affected by the specified column filters.
ALLEXCEPT ( <TableName>, <ColumnName> [, <ColumnName> [, … ] ] )
Evaluates an expression in a context modified by filters.
CALCULATE ( <Expression> [, <Filter> [, <Filter> [, … ] ] ] )
When a column name is given, returns a single-column table of unique values. When a table name is given, returns a table with the same columns and all the rows of the table (including duplicates) with the additional blank row caused by an invalid relationship if present.
VALUES ( <TableNameOrColumnName> )
Clear filters from the specified tables or columns.
REMOVEFILTERS ( [<TableNameOrColumnName>] [, <ColumnName> [, <ColumnName> [, … ] ] ] )
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )