 Marco Russo
Marco RussoFrom hereinafter, the article describes the architecture in Analysis Services, but all the concepts are identical in Power BI.
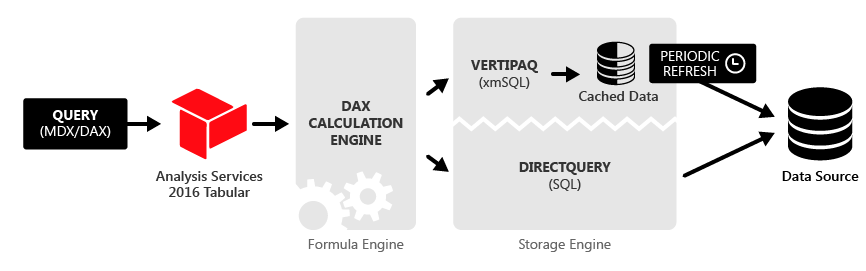
When you create a data model in DirectQuery mode, you can include in the data model only tables from a single relational database, and every MDX or DAX query generates one or more SQL query to the source database. When you use DirectQuery, the VertiPaq engine does not store a copy of the data in memory, and you do not have to process the data model in advance. In practice, DirectQuery replaces VertiPaq as a storage engine in the Analysis Services architecture, as you see in the following schema.
Every time DirectQuery generates a query to SQL Server, it only retrieves a predefined maximum number of rows from SQL Server, which is 1 million by default. The reason of this behavior is to limit queries that could run too long, requesting too much memory on Analysis Services to store an intermediate result during a more complex query.
For example, consider the following DAX query:
EVALUATE ROW ( "rows", COUNTROWS ( Sales ) )
It generates a corresponding SQL query that returns only one row:
SELECT COUNT_BIG(*) AS [a0]
FROM ( ( SELECT [Analytics].[Sales].*
FROM [Analytics].[Sales]
) ) AS [t1];)
However, other DAX queries might transfer a large number of rows to Analysis Services for a following evaluation. For example, consider this other DAX query:
EVALUATE
ROW (
"orders",
COUNTROWS (
ALL ( Sales[Order Number], Sales[Order Line Number] )
)
)
The SQL query that is generated does not execute the COUNT operation on SQL Server, and transfer the list of existing combination of Order Number and Order Line Number values to Analysis Services. However, a TOP clause limits the number of rows that could be returned by this query to 1 million:
SELECT TOP ( 1000001 )
[t1].[Order Number],
[t1].[Order Line Number]
FROM ( ( SELECT [Analytics].[Sales].*
FROM [Analytics].[Sales]
) ) AS [t1]
GROUP BY [t1].[Order Number],
[t1].[Order Line Number];
If the result is greater than 1 million of rows, the number of rows transferred is exactly one million and one. When this happens, SSAS assumes that there are other rows that have not been transferred, and the result based on this incomplete result would be incorrect. Thus, it returns this error:
The resultset of a query to external data source has exceeded the maximum allowed size of ‘1000000’ rows.
This default limit of 1 million rows is the same used for models created by Power BI Desktop. However, you might want to increase this setting on your SSAS instance. To do that, you have to manually edit the msmdsrv.ini configuration file, specifying a different limit for the MaxIntermediateRowsetSize setting, which has to be added to the file using the following syntax, because it is not present by default:
<ConfigurationSettings>
. . .
<DAX>
<DQ>
<MaxIntermediateRowsetSize>1000000
</MaxIntermediateRowsetSize>
</DQ>
</DAX>
. . .
Unfortunately, you cannot modify this setting for Power BI in a supported way. You can find more details about this and other settings for DAX in the MSDN documentation online.
If you have a SSAS Tabular server with a good amount of memory and a good bandwidth for connecting to the data source in DirectQuery mode, you probably want to increase this number to a higher number. As a rule of thumb, this setting should be higher than the larger dimension a star schema model. For example, if you have 4 millions of products and 8 millions of customers, you should increase the MaxIntermediateRowsetSize setting to 10 million. In this way, any query aggregating the data at the customer level would continue to work. Using a value that is too high (such as 100 million) could exhaust the memory and/or timeout the query before the limit is reached, so a lower limit helps to avoid such a critical condition.
Counts the number of rows in the table where the specified column has a non-blank value.
COUNT ( <ColumnName> )