 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariRow context is the second fundamental concept in writing DAX code. In a previous article, we introduced the first concept – the filter context – using a visual approach. In this article, we rely on graphical visualization to describe a row context.
This article provides a different perspective on a topic already discussed in other row context articles: read them to get more insights about this important concept for DAX.
A column reference requires a row context
Whenever you have a column reference in a DAX expression, you need a row context to evaluate the expression. For example, consider the following DAX expression:
Sales[Quantity] * Sales[Net Price]
The formula multiplies Quantity by Net Price in the Sales table. More precisely, the formula performs the following steps:
- It gets the value of the Quantity column in the current row of the Sales
- It gets the value of the Net Price column in the current row of the Sales
- It multiplies the two values obtained in the previous steps.
Every column reference requires a “current row” to be evaluated. However, what is the meaning of a “current row”? Well, we used “current row” as a generic way to identify a concept very specific to DAX: the row context.
A row context identifies a single row of a table. For example, consider the following Sales table.
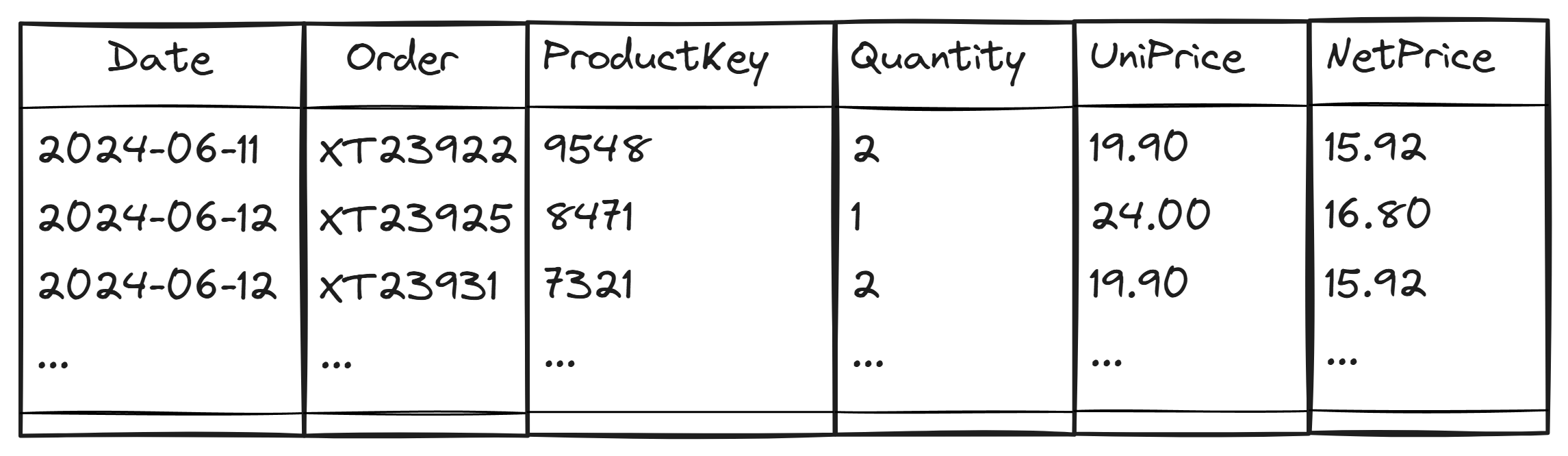
We can represent the row context for the second row of Sales by highlighting that row.
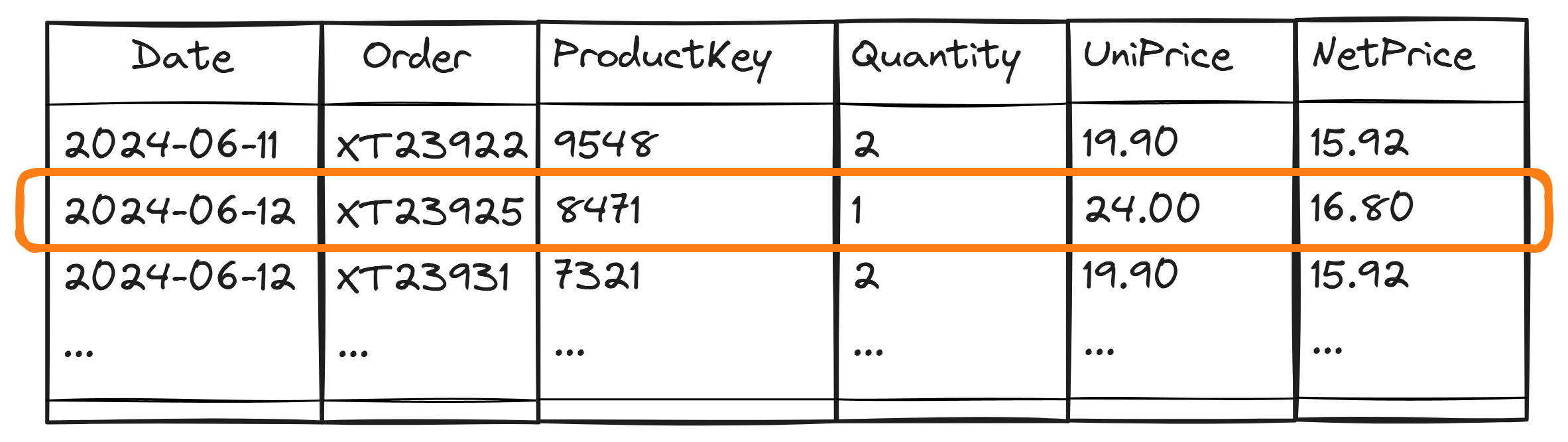
However, we could also represent the row context using a table with only one row—the row pointed by the row context.

This latter representation is particularly helpful in describing the context transition, a topic
for a future article.
How to get a row context
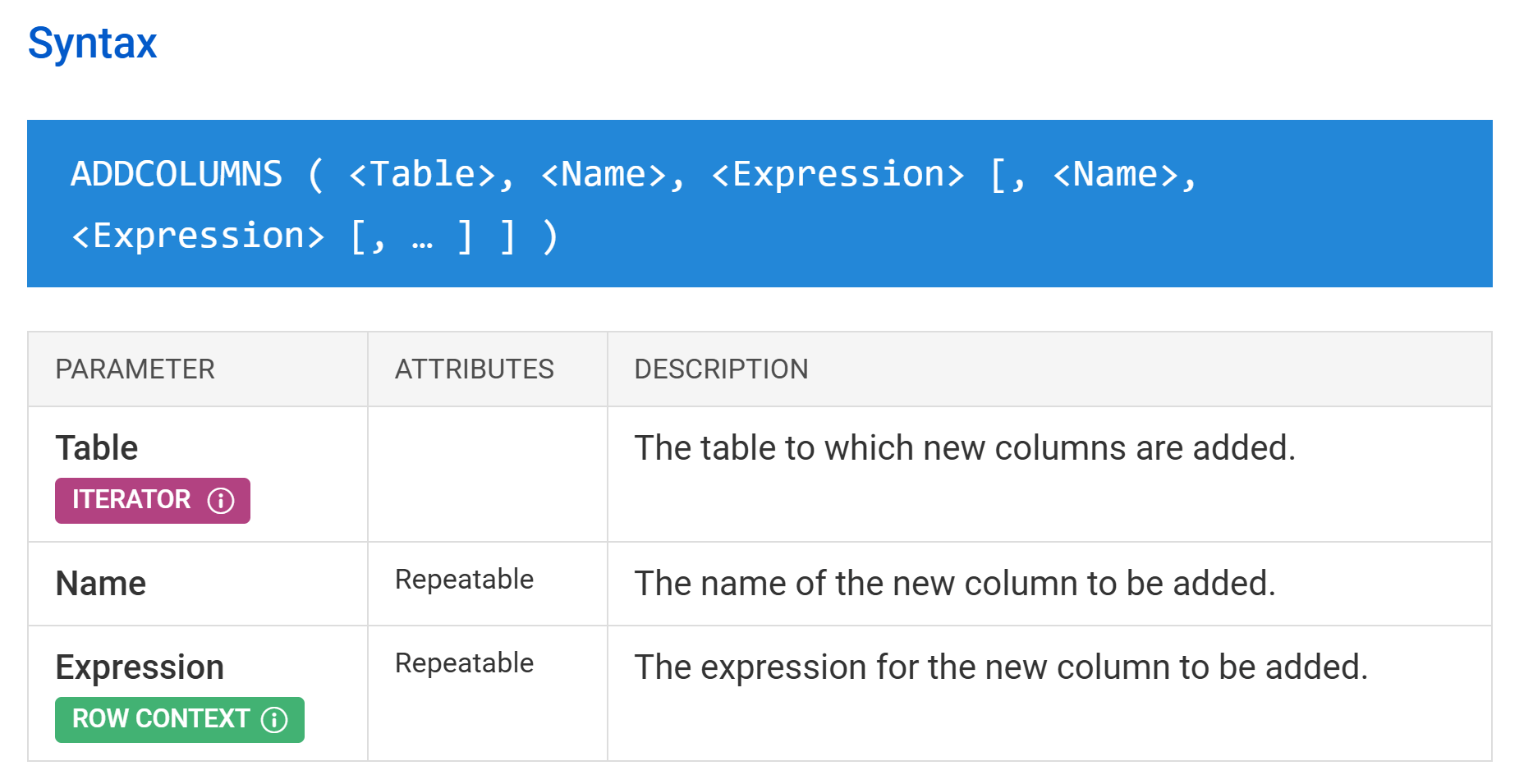
A row context can be obtained by iterating a table with an iterator function in DAX. In the DAX Guide, every function that iterates a table has an iterator tag for the table that is iterated and a row context tag for each parameter that provides a DAX expression executed in a row context over the iterated table. For example, the first argument of ADDCOLUMNS is the table iterated, and there could be one or more expressions evaluated in a row context for each row of the iterated table.
You can filter the Iterator group on the DAX Guide to get a list of all the iterators.
Thus, an iterator always scans a table row by row. The row context always provides access to the entire row, even though our expression only uses a few columns.
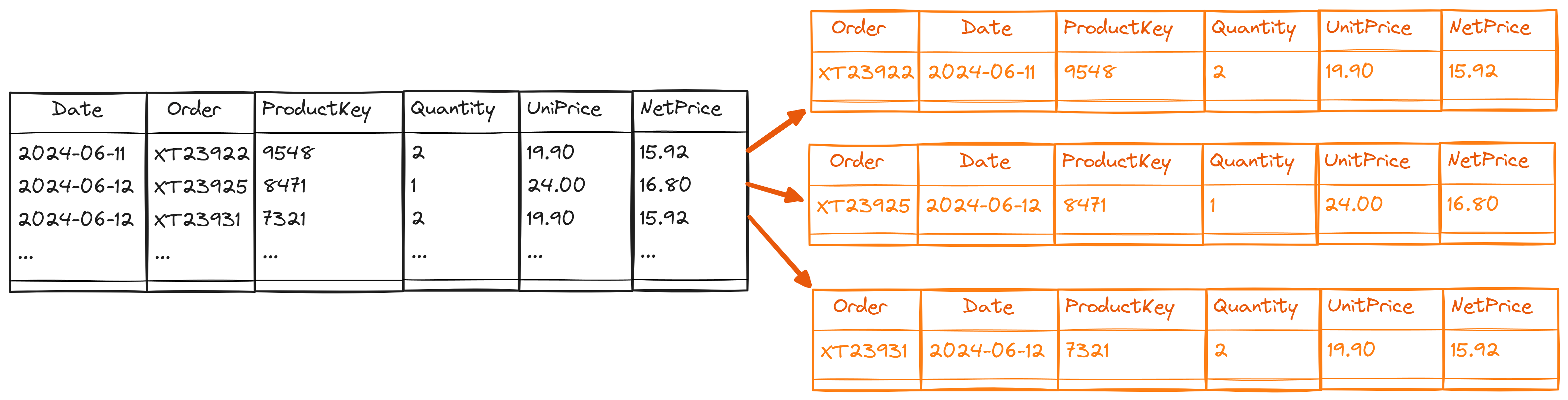
While the engine might optimize the execution considering only the columns referenced in a DAX expression, from a conceptual point of view, we have access to all the columns of the iterated table. However, the row context does not have a materialization cost because it only represents a position in a table. Again, we can represent the row context with a table that has all the columns of the original table and only one row, but this table does not duplicate any data – it is just a conceptual model that makes it easier to explain how DAX works.
A calculated column is a special case of an iterator. When the model is refreshed, the engine executes the expression of a calculated column for each table row, storing its result in a separate column. Unlike iterators, which iterate the rows visible through the filter context, calculated columns are evaluated in an empty filter context, so they always iterate all the table rows.
A filter context filters, a row context iterates
When you execute a DAX expression, both the filter and row contexts are usually involved. For example, consider the following definition of the Sales Amount measure:
Sales Amount =
SUMX (
Sales,
Sales[Quantity] * Sales[Net Price]
)
SUMX is a DAX iterator that executes the second argument for each row of the table in the first argument. We say that SUMX iterates the table expression specified in the first argument. The filter context filters that table expression. The simplest table expression we can use is just the Sales table reference. A table reference in DAX is always filtered by the filter context, so SUMX iterates the rows in Sales visible in the filter context. For example, the following diagram shows this behavior when we apply a filter on June 12th, 2024.
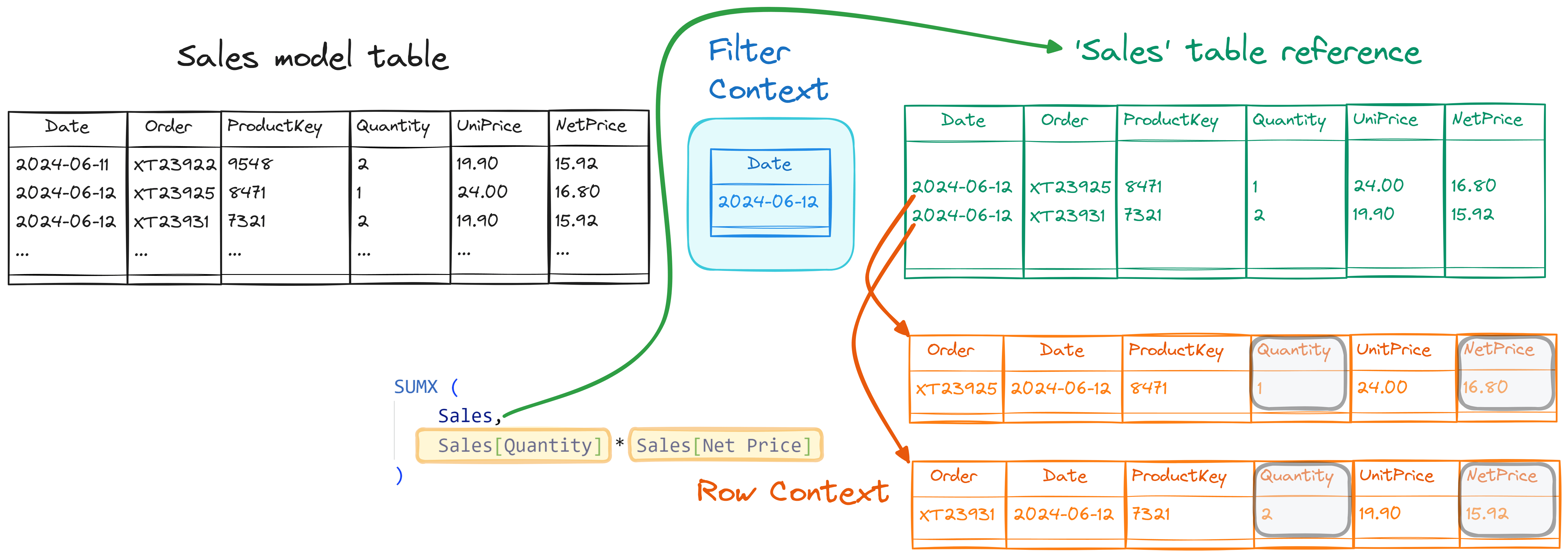
The Sales name is used to identify two different concepts:
- On the left, we have the Sales table in the semantic model. When we talk about the “model table”, we consider the physical table in the semantic model with all the rows, ignoring any filter.
- On the right, we have the Sales table reference. A table reference in DAX is always filtered by the security filters and by the filter context. The table reference is like a “view” on the model table that returns only the “visible” rows. DAX cannot override the security filters, whereas the filter context can be manipulated by adding and removing filters using CALCULATE and CALCULATETABLE.
The SUMX expression executes these operations:
- It evaluates the first argument in the filter context.
- For each row in the table obtained at (1), it evaluates the second argument in the corresponding row context and the same filter context.
The filter context is no longer relevant if we only use column references in the second argument. However, this could be important if we have other expressions. For example, the following measure divides the amount of each transaction by a number defined by a sliced selection:
Sales Amount Scale A =
SUMX (
Sales,
DIVIDE (
Sales[Quantity] * Sales[Net Price],
SELECTEDVALUE ( Scale[Scale] )
)
)
The SELECTEDVALUE function returns the current selection of a slicer on Scale because the filter context is still active in that expression. The code shown is not ideal because if the expression does not depend on the row context, it could be evaluated before the iterator, making it explicit that this dependency does not exist:
Sales Amount Scale B =
VAR _Factor = SELECTEDVALUE ( Scale[Scale], 1 )
RETURN
SUMX (
Sales,
(Sales[Quantity] * Sales[Net Price]) / _Factor
)
In this specific case, the division should be outside SUMX. However, we just wanted to clarify that the filter context is still available in the expression evaluated in a row context in the iterator. We used these last examples for educational purposes. Code optimization is not a goal of this article.
The table expression defines cardinality
The row context iterates all the rows returned by the table expression provided to the iterator function. Therefore, the cardinality of an iteration is defined by the table expression. For example, consider the following two measures:
Sales Amount Projection =
VAR SalesProjection =
SELECTCOLUMNS (
Sales,
Sales[Quantity],
Sales[Net Price]
)
RETURN
SUMX (
SalesProjection,
Sales[Quantity] * Sales[Net Price]
)
Sales Amount Grouped =
VAR SalesGrouped =
SUMMARIZE (
Sales,
Sales[Quantity],
Sales[Net Price]
)
RETURN
SUMX (
SalesGrouped,
Sales[Quantity] * Sales[Net Price]
)
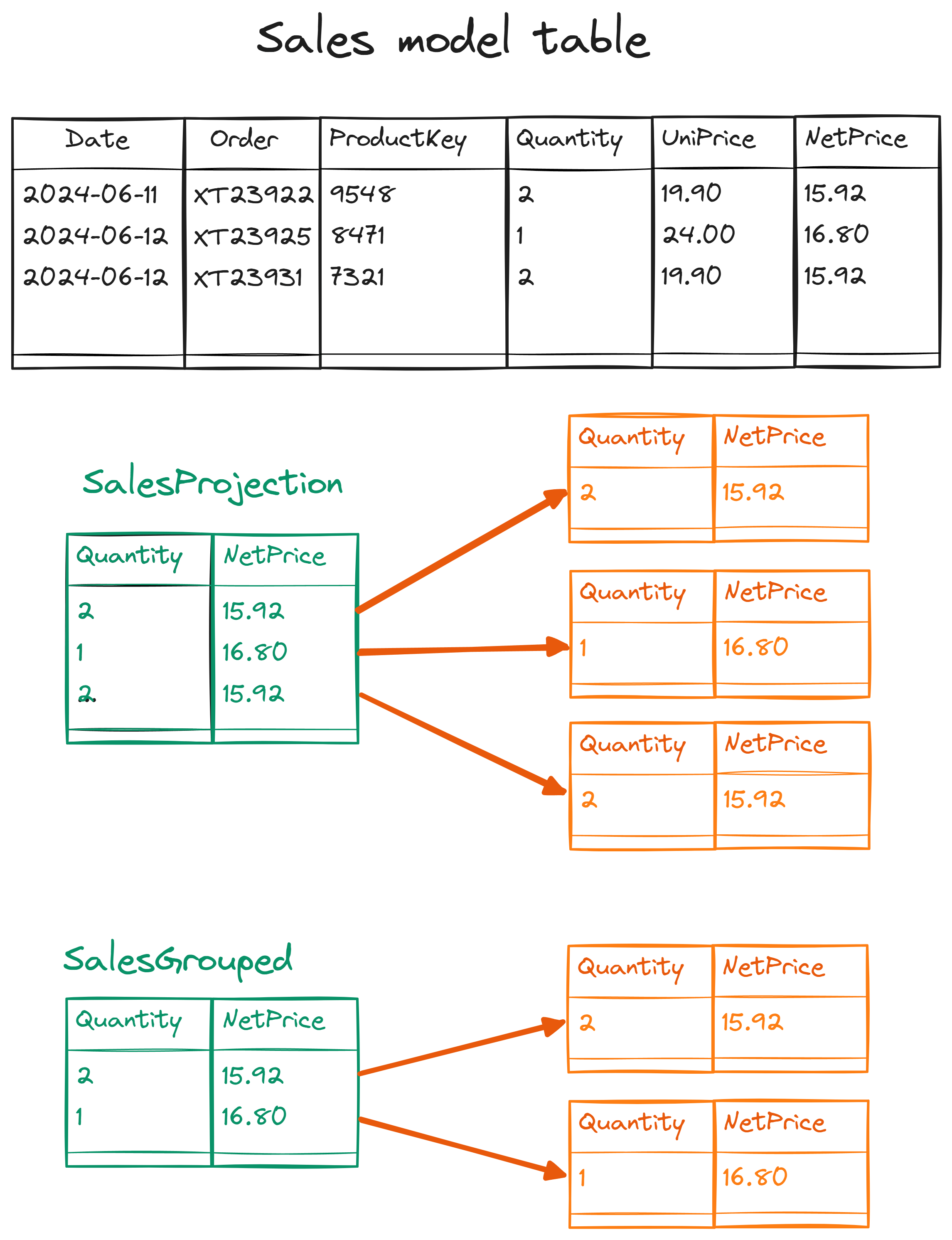
The Sales Amount Projection measure returns the same result as Sales Amount because the number of rows iterated (the cardinality) is the same. Indeed, even though the SalesProjection variable has only two columns, the number of rows is the same. From a performance point of view, as long as the table is not materialized, we do not pay the price of allocating in memory the unused model columns potentially referenced. However, for the purposes of this article, we can ignore that: what matters is that the result of SUMX depends on the number of rows iterated, and this number is the same. The SELECTCOLUMNS function does not change the cardinality of the table iterated.
The Sales Amount Grouped measure returns a different result because it iterates the number of unique combinations of Quantity and Net Price in Sales returned by SUMMARIZE. Indeed, SUMMARIZE can return a smaller number of rows from the table provided in the first argument, which usually results in a smaller cardinality of the result. This same smaller cardinality explains the different result. The following picture shows the content of the SalesProjection and SalesGrouped variables used by the two measures.
Conclusions
The row context can be represented visually by using a row selection in a table or by representing the row as a table with all the columns and a single row. This latter representation will be useful when we discuss the context transition in a future article.
Iterators obtain a row context and control the cardinality of the iteration through the table expression iterated. Indeed, simple table references usually show only a subset of the rows available in the model because of the filter context. Representing the table expression provided to the iterator in a graphical way helps understand the cardinality of the iteration and the columns available to the row context.
Returns a table with new columns specified by the DAX expressions.
ADDCOLUMNS ( <Table>, <Name>, <Expression> [, <Name>, <Expression> [, … ] ] )
Returns the sum of an expression evaluated for each row in a table.
SUMX ( <Table>, <Expression> )
Evaluates an expression in a context modified by filters.
CALCULATE ( <Expression> [, <Filter> [, <Filter> [, … ] ] ] )
Evaluates a table expression in a context modified by filters.
CALCULATETABLE ( <Table> [, <Filter> [, <Filter> [, … ] ] ] )
Returns the value when there’s only one value in the specified column, otherwise returns the alternate result.
SELECTEDVALUE ( <ColumnName> [, <AlternateResult>] )
Returns a table with selected columns from the table and new columns specified by the DAX expressions.
SELECTCOLUMNS ( <Table> [[, <Name>], <Expression> [[, <Name>], <Expression> [, … ] ] ] )
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )