 Marco Russo
Marco RussoA large amount of Power BI users use DAX to write measures and calculated columns. However, any DAX formula is part of a DAX query, which is processed by two engines: the formula engine and the storage engine. In order to understand their role, we can analyze how Power BI retrieves the data for a report.
For example, consider the following visualization in Power BI. It displays the Sales Amount and Margin% measures by month, filtering only the United States.
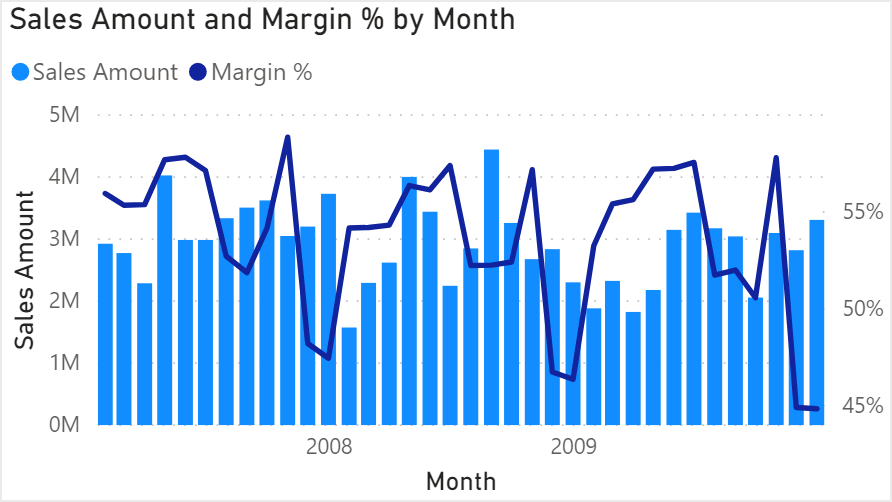
The visual displays in a graphical way the result of the Sales Amount and Margin% measures, which are defined in the model as follows:
Sales Amount := SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ) Total Cost := SUMX ( Sales, Sales[Quantity] * Sales[Unit Cost] ) Margin := [Sales Amount] - [Total Cost] Margin % := DIVIDE ( [Margin], [Sales Amount] )
The visual retrieves the data to display by using the following DAX query, which can be obtained using Performance Analyzer:
DEFINE
VAR __DS0FilterTable =
TREATAS ( { "United States" }, 'Customer'[Country] )
VAR __DS0Core =
SUMMARIZECOLUMNS (
'Date'[End of month],
__DS0FilterTable,
"Sales_Amount", 'Sales'[Sales Amount],
"Margin__", 'Sales'[Margin %]
)
VAR __DS0BodyLimited =
SAMPLE ( 3502, __DS0Core, 'Date'[End of month], 1 )
EVALUATE
__DS0BodyLimited
ORDER BY 'Date'[End of month]
Power BI sends the DAX query to the Analysis Services engine that contains the semantic model. This engine could be local to Power BI Desktop, or it could be an external service: on-premises (SQL Server Analysis Services) or in the cloud (Azure Analysis Services). The connection to a dataset published on Power BI also performs a connection to a special cloud instance of Analysis Services.
When Analysis Services receives the query, it generates and executes a query plan. The query plan is executed by two engines: the formula engine and the storage engine.
We can observe this execution by analyzing the query with DAX Studio. The query plan is a dense list of operations.

In the query plan, each node processes the result of one or more children nodes. Each node corresponds to an operation performed by the formula engine. However, there is a special node that represents a request made to a different service: the storage engine. The formula engine can process data, but it is cannot retrieve data from the tables in the data model. The storage engine is the one in charge of data retrieval. In the previous figure, the highlighted nodes are in charge of storage engine requests. Because the model used is DirectQuery, these nodes are all DirectQueryResult; they are SQL queries sent to SQL Server. For a DirectQuery model, a DAX query retrieves the data by using the DirectQuery storage engine.
Even though the previous query plan shows five storage engine queries, the Server Timings pane in DAX Studio shows only one SQL query. SE refers to time spent in the storage engine, FE in the formula engine.
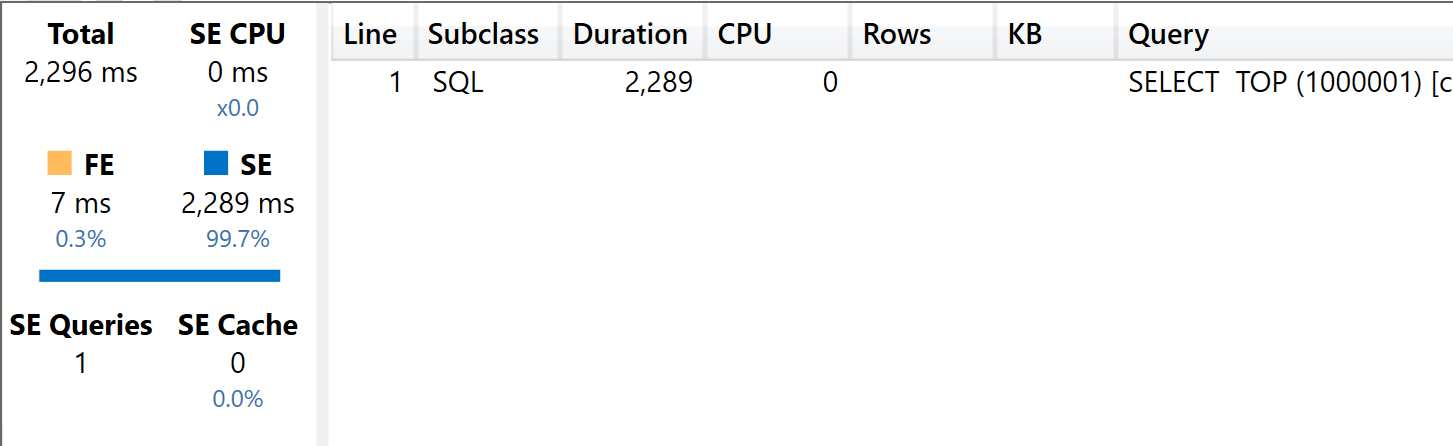
All five nodes consume the result produced by a single execution of the following SQL query:
SELECT TOP (1000001)
[c74],
SUM([a0]) AS [a0],
SUM([a1]) AS [a1]
FROM (
SELECT
[t0].[Quantity] AS [c4],
[t0].[Unit Cost] AS [c7],
[t0].[Net Price] AS [c8],
[t2].[Country] AS [c52],
[t3].[End of month] AS [c74],
([t0].[Quantity] * [t0].[Unit Cost]) AS [a0],
([t0].[Quantity] * [t0].[Net Price]) AS [a1]
FROM (
(
( select [ProductKey],[CustomerKey],[Order Date],[Quantity],
[Unit Price],[Unit Discount],[Unit Cost],[Net Price]
from [Analytics].[Sales] as [$Table]) AS [t0]
LEFT OUTER JOIN
(select [CustomerKey],[Customer Code],[Title],[Name],[Birth Date],
[Marital Status],[Gender],[Yearly Income],[Total Children],
[Children At Home],[Education],[Occupation],[House Ownership],
[Cars Owned],[Continent],[City],[State],[Country],
[Address Line 1],[Address Line 2],[Phone],
[Date First Purchase],[Customer Type],[Company Name]
from [Analytics].[Customer] as [$Table]) AS [t2] on
(
[t0].[CustomerKey] = [t2].[CustomerKey]
)
)
LEFT OUTER JOIN (
SELECT
[t3].[Date] AS [Date],
EOMONTH([t3].[Date], 0) AS [End of month]
FROM
(
(select [Date] as [Date],[DateKey] as [DateKey],
[Calendar Year Number] as [Year],
[Calendar Year Quarter Number] as [Year Quarter Number],
[Calendar Year Quarter] as [Year Quarter],
[Calendar Year Month Number] as [Year Month Number],
[Calendar Year Month] as [Year Month],
[Month Number] as [Month Number], [Month] as [Month],
[Day of Week Number] as [Day of Week Number],
[Day of Week] as [Day of Week],
[Working Day] as [Working Day],
[Is Holiday] as [Is Holiday],
[Holiday Name] as [Holiday Name]
from [Analytics].[Date] as [$Table])
) AS [t3]
) AS [t3] on
(
[t0].[Order Date] = [t3].[Date]
)
)
) AS [t0]
WHERE (
[c52] = N'United States'
)
GROUP BY [c74]
The query retrieves the columns needed to resolve the DAX query, performing the aggregations of a row-level expression directly in SQL; indeed, SQL offers such aggregation as part of its features. When the DAX query needs data from SQL Server, the formula engine processes the raw data retrieved through the DirectQuery storage engine.
We can repeat the same analysis with an identical report created by importing the content of the tables in memory instead of using DirectQuery. In this case, the query plan describing the behavior of the formula engine is slightly different, because the capabilities of the storage engine are different. The DAX query we have seen at the beginning executed on a model made of imported tables produces the following query plan.

This time, the requests made to the storage engine are identified by nodes named “Cache”. In addition to this, in this case the five references to a storage engine request correspond to a single storage engine query, which is executed more than 300 times faster than with DirectQuery.

The in-memory storage engine used by tables imported in the model is called VertiPaq. Whenever you create a table in Power BI by using the Import or Dual storage mode, the content of the table is read only once from the datasource when you refresh the model, and the data is stored compressed in memory. The queries made to the VertiPaq storage engine are described in a human readable format called xmSQL. This is the single xmSQL query executed by the previous query plan:
WITH
$Expr0 := ( PFCAST ( 'Analytics Sales'[Quantity] AS INT )
* PFCAST ( 'Analytics Sales'[Unit Cost] AS INT ) ) ,
$Expr1 := ( PFCAST ( 'Analytics Sales'[Quantity] AS INT )
* PFCAST ( 'Analytics Sales'[Net Price] AS INT ) )
SELECT
'Analytics Date'[Column],
SUM ( @$Expr0 ), SUM ( @$Expr1 )
FROM 'Analytics Sales'
LEFT OUTER JOIN 'Analytics Date'
ON 'Analytics Sales'[Order Date]='Analytics Date'[Date]
LEFT OUTER JOIN 'Analytics Customer'
ON 'Analytics Sales'[CustomerKey]='Analytics Customer'[CustomerKey]
WHERE
'Analytics Customer'[Country] = 'United States';
In this case, the query plans generated for DirectQuery and VertiPaq are very similar. The different storage engine queries in SQL and xmSQL return the same result, a table with three columns:
- a date column representing the month;
- a numeric column sum of Quantity * Unit Cost for the month;
- a numeric column sum of Quantity * Net Price for the month.
The two numeric columns returned correspond to the result expected for the Total Cost and Sales Amount measures respectively. However, the measures required by the DAX query are Sales Amount and Margin %. Because the result provided by the storage engine does not correspond to the result of the DAX query, we can deduce that the missing part of the calculation is performed by the formula engine. Indeed, by knowing the result of Sales Amount and Total Cost, the formula engine computes the result of the Margin% measure:
Margin := [Sales Amount] - [Total Cost] Margin % := DIVIDE ( [Margin], [Sales Amount] )
After this practical example, we can describe in more detail the role of the formula and storage engines.
Differences between the formula engine and the storage engine
There are two engines involved in the execution of a DAX query:
- The formula engine processes the request, generating and executing a query plan.
- The storage engine retrieves data out of the Tabular model to answer the requests made by the formula engine. The storage engine has two implementations:
- VertiPaq hosts a copy of the data in memory that is refreshed periodically from the data source.
- DirectQuery forwards queries directly to the original data source for every request.
The formula engine is the higher-level execution unit of the query engine. It can handle all the operations requested by DAX.
When the formula engine must retrieve data from the underlying tables, it forwards the requests to the storage engine. The queries sent to the storage engine might vary from a simple retrieval of the raw table data to more complex queries aggregating data and joining tables. The storage engine only communicates with the formula engine. The storage engine returns data in an uncompressed format, regardless of the original format of the data.
A Tabular model usually stores data using either the VertiPaq or the DirectQuery storage engine. However, composite models can use both technologies within the same data model and for the same tables. The choice of which engine to use is made in the query plan for each storage engine request in each DAX query.
Tasks of the formula engine
The formula engine converts a DAX query into a query plan with a list of physical steps to execute. Each step in the query plan corresponds to a specific operation executed by the formula engine. Typical operators of the formula engine include joins between tables, filtering with complex conditions, aggregations, and lookups. Some of these operators require data from columns in the data model. In these cases, the formula engine sends a request to the storage engine, which answers by returning a datacache. A datacache is a temporary storage area created by the storage engine and read by the formula engine that contains the result of a storage engine query.
Datacaches are not compressed; datacaches are plain in-memory tables stored in an uncompressed format, regardless of the storage engine they come from. Because the formula engine is single-threaded, any operation executed in the formula engine uses just one thread and one core, no matter how many cores are available. The formula engine sends requests to the storage engine sequentially, one query at a time. A certain degree of parallelism is available only within each request to the storage engine, which has a different architecture and can take advantage of the multiple cores available.
Tasks of the storage engine
The goal of the storage engine is to scan the database and produce the datacaches needed by the formula engine. The storage engine is independent from DAX. For example, DirectQuery on SQL Server uses SQL as the storage engine. The internal storage engine of Tabular (known as VertiPaq) is independent from DAX too, even tough the VertiPaq storage engine allows some communication with the DAX formula engine through CallbackDataId requests.
The storage engine executes exclusively the queries allowed by its own set of operators. Depending on the kind of storage engine used, the set of operators might range from very limited (VertiPaq) to very rich (SQL).
Every table in a model can have a different storage engine technology:
- Import: Also called in-memory, or VertiPaq. The content of the table is stored by the VertiPaq engine, copying and restructuring the data from the data source during data refresh.
- DirectQuery: The content of the table is read from the data source at query time, and it is not stored in memory during data refresh.
- Dual: The table can be queried in both VertiPaq and DirectQuery. During data refresh the table is loaded in memory by the VertiPaq engine. But at query time, the table may also be read in DirectQuery mode with the most up-to-date information.
In this article we do not look at aggregations, which are just alternative options to retrieve the data from the storage engine in order to achieve better performance.
The storage engine might feature a parallel implementation. For example, both VertiPaq and SQL Server can use multiple cores to process a single storage engine request. However, the storage engine receives requests from the formula engine, which sends them synchronously. Thus, the formula engine waits for one storage engine query to finish before sending the next one. Therefore, parallelism in the storage engine might be reduced by the lack of parallelism in the formula engine.
Conclusions
Understanding the different roles of the formula and storage engines when executing a DAX query is the first step towards optimizing that DAX query. Many performance issues such as the large materialization of datacaches or an excessive number of storage engine requests are often the symptoms of issues in the data model or in DAX formulas.