 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariSlicers with too many values might be inconvenient for users, as they must search for the desired selection among too many lines. In such cases, a common solution is to build a hierarchy and use slicers with multiple columns inside, or multiple slicers, each with one column. However, this solution works only in structures with a natural hierarchy, like continents and countries. Indeed, each country belongs to only one continent so the hierarchy can be easily created with a new column.
If the hierarchy is non-natural, the relationship between the parent and the children is many-to-many, requiring a specific type of relationship. For example, let us pretend we have two users (Marco and Alberto) interested in different brands. We want to reduce the number of items visible in the slicer to only the ones relevant to each user. Both Marco and Alberto wish to see A. Datum. However, for the other brands, they have different interests.
When the user selects Alberto, the only visible items are Alberto’s.
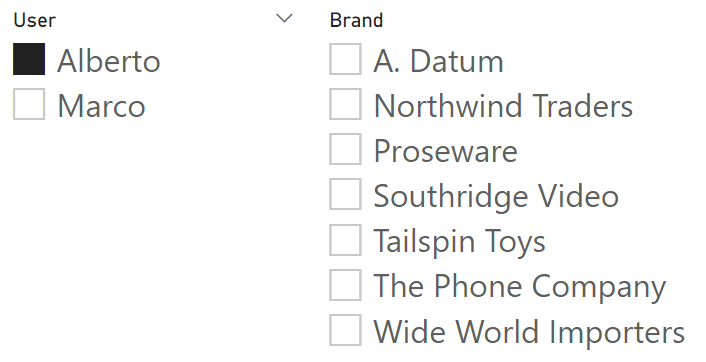
Be mindful that this technique is not about securing items. If you need a similar security solution, you need to implement the code and the model using security roles. Here, the goal is only to make it easier for specific users to focus on interesting brands.
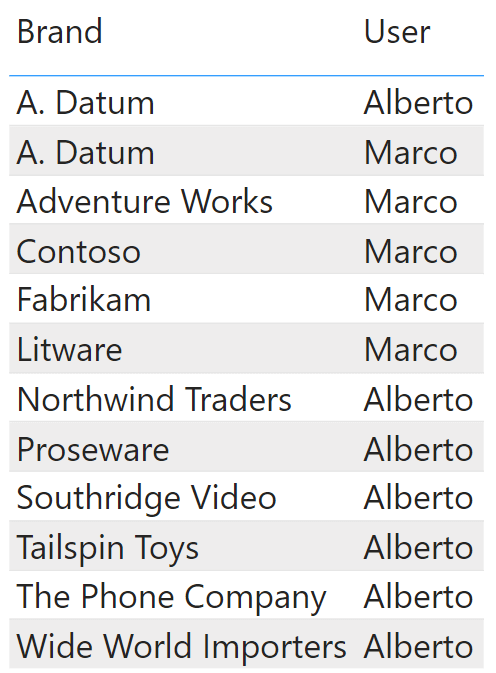
The solution to this scenario is rather simple: we can create a table containing the allowed pairs of values and then build the correct relationship with the table containing the values. In the example, we created a simple calculated table in DAX:
Brand selection =
SELECTCOLUMNS (
{
( "A. Datum", "Marco" ),
( "A. Datum", "Alberto" ),
( "Adventure Works", "Marco" ),
( "Contoso", "Marco" ),
( "Fabrikam", "Marco" ),
( "Litware", "Marco" ),
( "Northwind Traders", "Alberto" ),
( "Proseware", "Alberto" ),
( "Southridge Video", "Alberto" ),
( "Tailspin Toys", "Alberto" ),
( "The Phone Company", "Alberto" ),
( "Wide World Importers", "Alberto" )
},
"Brand", [Value1],
"User", [Value2]
)
We must then create a relationship between the Brand selection table and the Product table. Because Brand is not a key in Product, we must create a many-to-many cardinality relationship with the cross-filter direction where Brand filters Product.
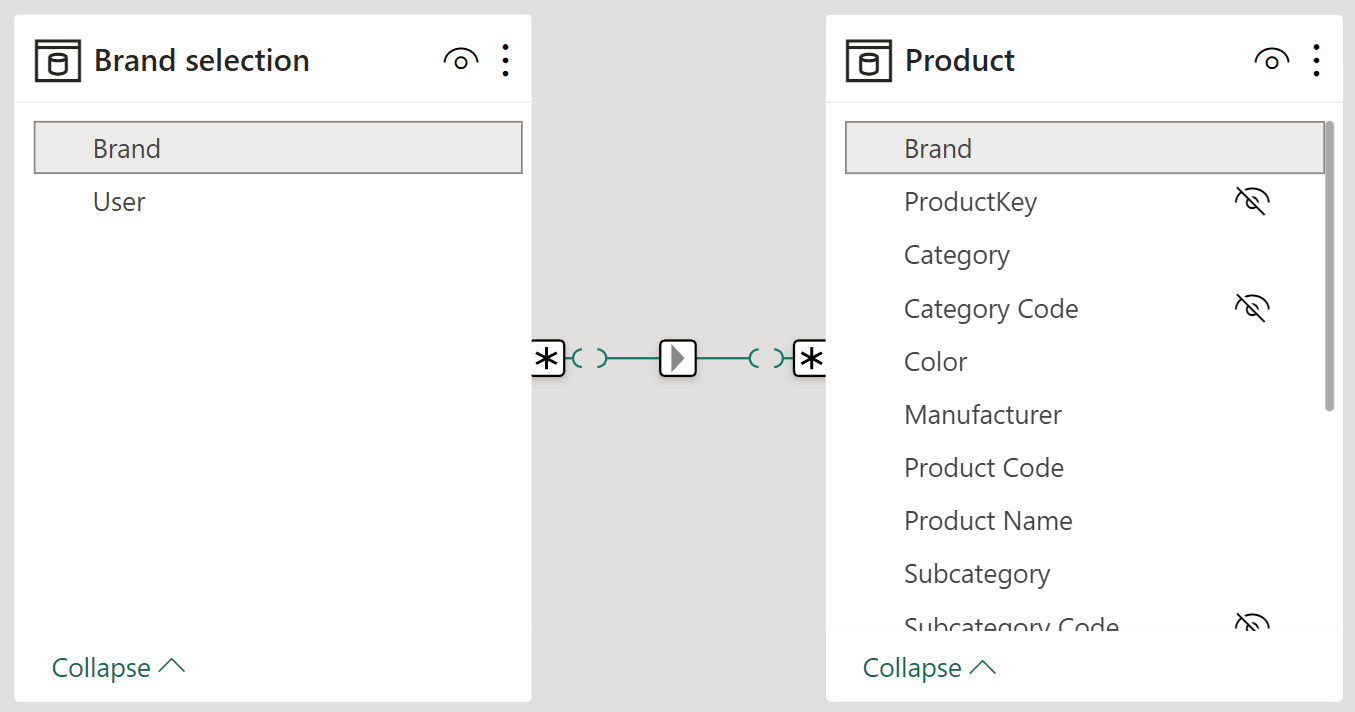
Once the relationship is in place, filter context propagation does its magic and filters slicers automatically.
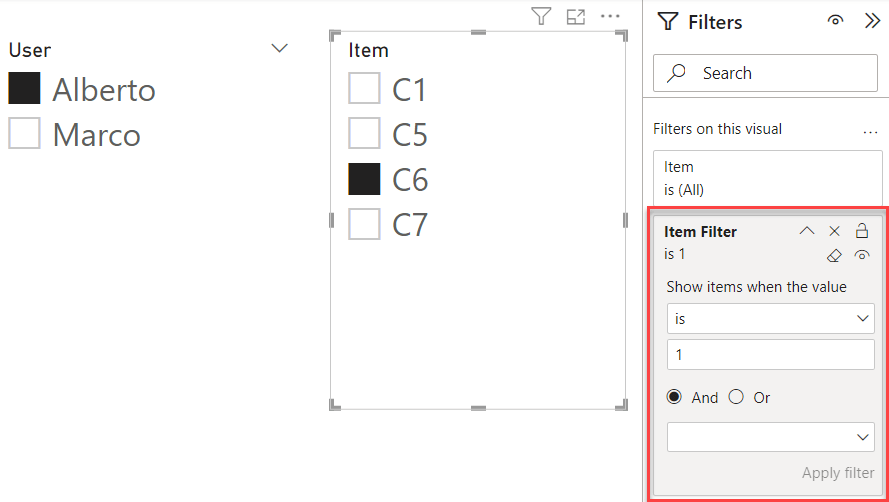
The scenario is a bit more tricky if the items in the slicer originate from a calculation group. Calculation groups have a limitation: they cannot participate in a relationship. Because of this, we cannot rely on a many-to-many relationship or a bidirectional filter to perform cross-filtering. Indeed, the Items calculation group and the Item selection table cannot remain separate from each other.
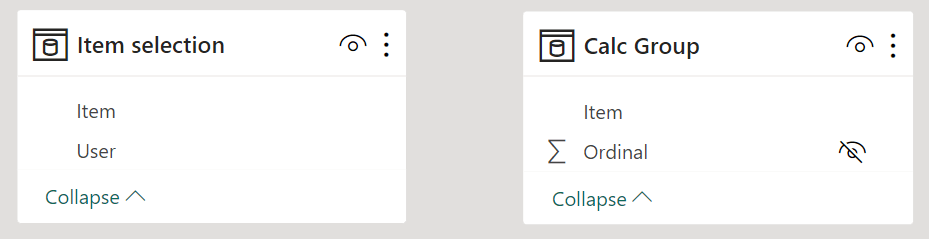
However, in this scenario, a simple DAX measure comes in handy, acting as a filter for the slicer:
Item Filter =
VAR CurrentUserSelection = VALUES ( 'Item selection'[Item] )
VAR CurrentCalcItem = SELECTEDVALUE ( 'Calc Group'[Item] )
VAR Result = INT ( CurrentCalcItem IN CurrentUserSelection )
RETURN
Result
The measure needs to return an integer value because measures returning Boolean values cannot be used as filters in the filter panel. Once the measure is in the model, adding it as a filter on the slicer, and filtering the value 1, is enough to activate the desired behavior.
A simple and neat solution where DAX comes in to help build a more usable report.