 Marco Russo
Marco RussoUPDATE 2022-06-07: Read the new article that includes a video: Using KEEPFILTERS in DAX.
There is an additional disclaimer to this article – if you think that it is too complex, just skip to the next paragraph, but if you think you already know KEEPFILTERS, please read this. If you read our book The Definitive Guide to DAX, you might consider KEEPFILTERS as only necessary when you have arbitrarily shaped filters that you do not want to lose by applying additional filters on individual columns. However, KEEPFILTERS’ relevance is quite a bit wider. In a way, this article is a way of making up for not having included a better description of KEEPFILTERS in our book.
Single column filters
The syntax you use in CALCULATE to apply a filter is always a table. When you use a predicate, it is internally transformed into a corresponding FILTER statement. For example, consider this expression:
AlwaysRed :=
CALCULATE (
[Sales Amount],
Products[Color] = "Red"
)
Internally, the filter expression is transformed into a FILTER, as described here:
AlwaysRed_Filter :=
CALCULATE (
[Sales Amount],
FILTER (
ALL ( Products[Color] ),
Products[Color] = "Red"
)
)
The semantic of the filter removes any existing filter applied to the same column, replacing it with the new filter defined in the predicate condition.
If you do not want to lose the existing filter, a widespread technique – used extensively in our previous books – is to replace ALL with VALUES, as in the following example:
OnlyRed_Values :=
CALCULATE (
[Sales Amount],
FILTER (
VALUES ( Products[Color] ),
Products[Color] = "Red"
)
)
The difference between the two functions is clearly visible in the following example. In the AlwaysRed measure, the filter over the Color column replaces the color in the row, whereas in the OnlyRed_Values measure the filter over the Color column intersects the filter of the color in the row.
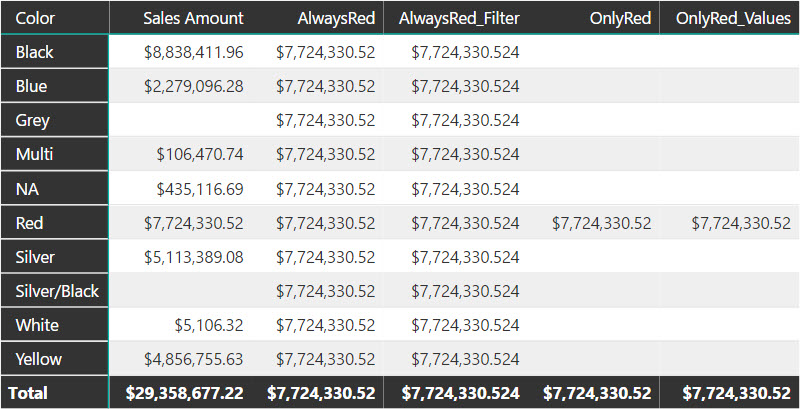
The same result for the OnlyRed_Values measure is possible using the KEEPFILTERS syntax, as in the OnlyRed measure:
OnlyRed :=
CALCULATE (
[Sales Amount],
KEEPFILTERS ( Products[Color] = "Red" )
)
Internally, this corresponds to the following FILTER:
OnlyRed_KeepfiltersAll :=
CALCULATE (
[Sales Amount],
KEEPFILTERS (
FILTER (
ALL ( Products[Color] ),
Products[Color] = "Red"
)
)
)
We have seen three different syntaxes for OnlyRed producing the same result. Which is better? At first sight, you might think that the VALUES version is faster than the KEEPFILTERS one, because the number of elements iterated is potentially smaller. However, what the engine does is not necessarily what the semantic of the query might lead us to think, as long as the result is the same. In fact, the KEEPFILTERS version is slightly better. The absolute difference is minimal, but why write FILTER ( VALUES ( t[col] ), t[col] = “Red” ) when you can write KEEPFILTERS ( t[col] = “Red” ) ?
For those readers excited about details: the query plan in the KEEPFILTERS version is shorter, and saves a small storage engine query. In absolute terms, we are talking about something that is not even measurable. You will not see a performance improvement using KEEPFILTERS, but this is just to say that you cannot find a reason not to use it.
Multiple column filters
For a simple filter on a single column, KEEPFILTERS is certainly a good choice. What if you have multi-column filters? Even in this case, the KEEPFILTERS option is usually better.
For example, this below computes a measure for Products whose Cost is lower than 5 or ListPrice is lower than 10:
AlwaysLow :=
CALCULATE (
[Sales Amount],
FILTER (
ALL ( Products[Cost], Products[ListPrice] ),
Products[Cost] < 5
|| Products[ListPrice] < 10
)
)
The result of the measure always considers all the Cost and ListPrice values satisfying the required conditions, regardless of the existing selection over the two columns.
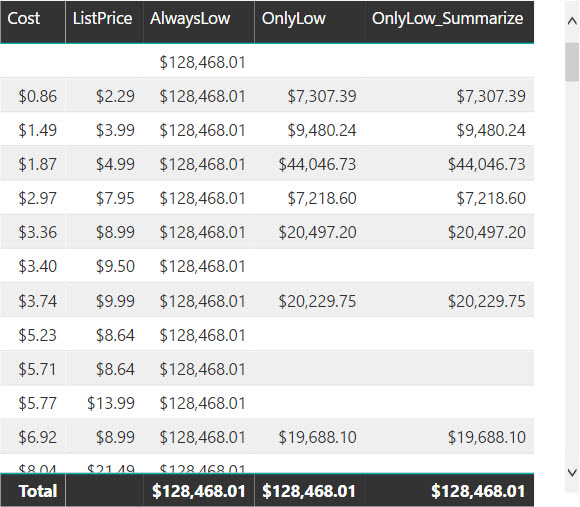
Because there is no syntax for VALUES with more than one column, the SUMMARIZE function can be used to retrieve the existing combinations in the filter context corresponding to the desired conditions.
OnlyLow_Summarize :=
CALCULATE (
[Sales Amount],
FILTER (
SUMMARIZE ( Products, Products[Cost], Products[ListPrice] ),
Products[Cost] < 5
|| Products[ListPrice] < 10
)
)
However, the same result is achievable also by wrapping the original FILTER condition based on ALL in a KEEPFILTERS function call, as in the OnlyLow measure.
OnlyLow :=
CALCULATE (
[Sales Amount],
KEEPFILTERS (
FILTER (
ALL ( Products[Cost], Products[ListPrice] ),
Products[Cost] < 5
|| Products[ListPrice] < 10
)
)
)
In this case the difference between the two options could be bigger, depending on the cardinality of the combinations considered. In terms of coding, the SUMMARIZE version usually results in a shorter code. However, the KEEPFILTERS version is usually the faster one, but further tests could be necessary in case the filter condition has complex expressions or CallbackDataID calls in the storage engine queries.
Conclusions
For both single column and multiple columns filter predicates, using KEEPFILTERS is a better choice than writing an explicit FILTER function using VALUES or SUMMARIZE to get the correct initial granularity – based on the existing filter context. KEEPFILTERS provides better performance and simplifies the code for single column filters.
Changes the CALCULATE and CALCULATETABLE function filtering semantics.
KEEPFILTERS ( <Expression> )
Evaluates an expression in a context modified by filters.
CALCULATE ( <Expression> [, <Filter> [, <Filter> [, … ] ] ] )
Returns a table that has been filtered.
FILTER ( <Table>, <FilterExpression> )
Returns all the rows in a table, or all the values in a column, ignoring any filters that might have been applied.
ALL ( [<TableNameOrColumnName>] [, <ColumnName> [, <ColumnName> [, … ] ] ] )
When a column name is given, returns a single-column table of unique values. When a table name is given, returns a table with the same columns and all the rows of the table (including duplicates) with the additional blank row caused by an invalid relationship if present.
VALUES ( <TableNameOrColumnName> )
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )