 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariPushing calculations down to the VertiPaq storage engine is always a good practice. Sometimes this is not feasible. However, carefully analyzing the aggregated expression can lead to optimization ideas that produce excellent query plans.
DAX developers should not be scared of iterators. Their performance is great as long as the expression computed during the iteration can be pushed down to the VertiPaq storage engine. Hence, a measure like Sales Amount is just perfect:
DEFINE
MEASURE Sales[Sales Amount] =
SUMX (
Sales,
Sales[Quantity] * Sales[Net Price]
)
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Color],
"Sales Amount", [Sales Amount]
)
Running this test query on our Contoso 100M database (which contains 200M rows in Sales) displays excellent performance.
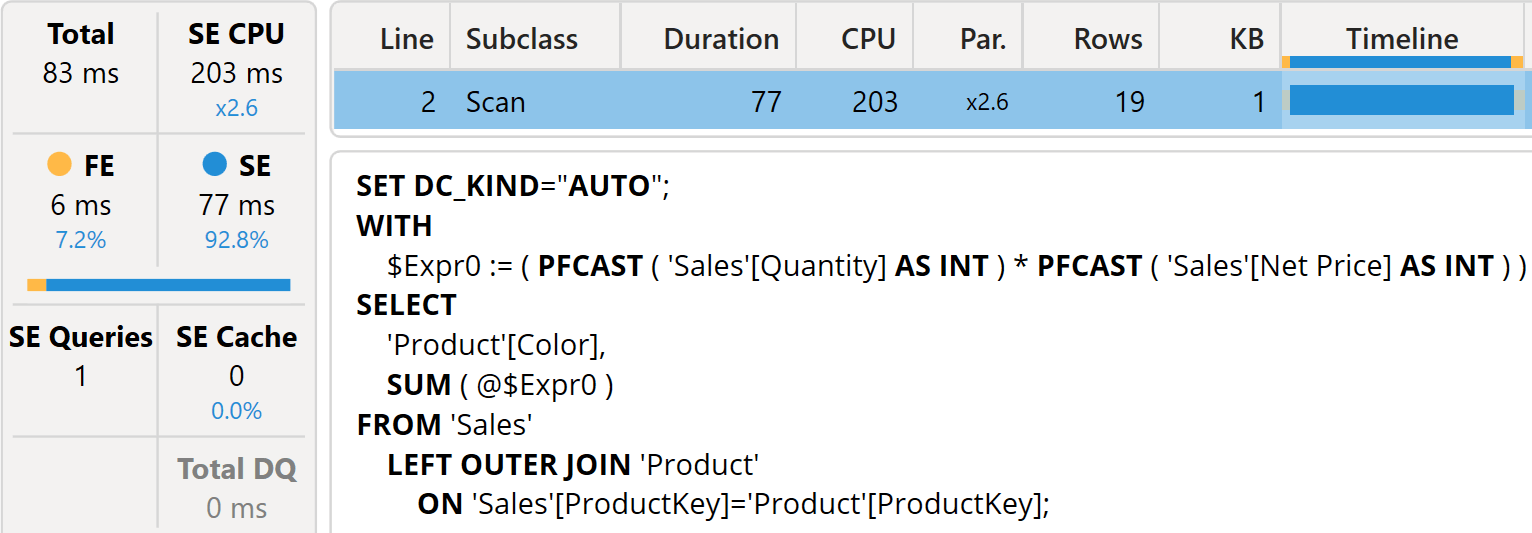
The query uses only 200ms of storage engine CPU, and is resolved in a single xmSQL query. Timings would be different on different hardware. However, we know this query is running at its optimal speed.
The iteration is very fast because the VertiPaq storage engine can execute the expression aggregated. Being a simple multiplication, it falls well within the capabilities of VertiPaq. However, a small change in the expression being iterated has a profound negative impact on performance. In the following query, we add a ROUND function to round the net price to the first decimal:
DEFINE
MEASURE Sales[Sales Amount] =
SUMX (
Sales,
Sales[Quantity] * ROUND ( Sales[Net Price], 1 )
)
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Color],
"Sales Amount", [Sales Amount]
)
The storage engine cannot execute ROUND. Therefore, in this scenario, it requires the intervention of the formula engine through VertiCalc and a callback.
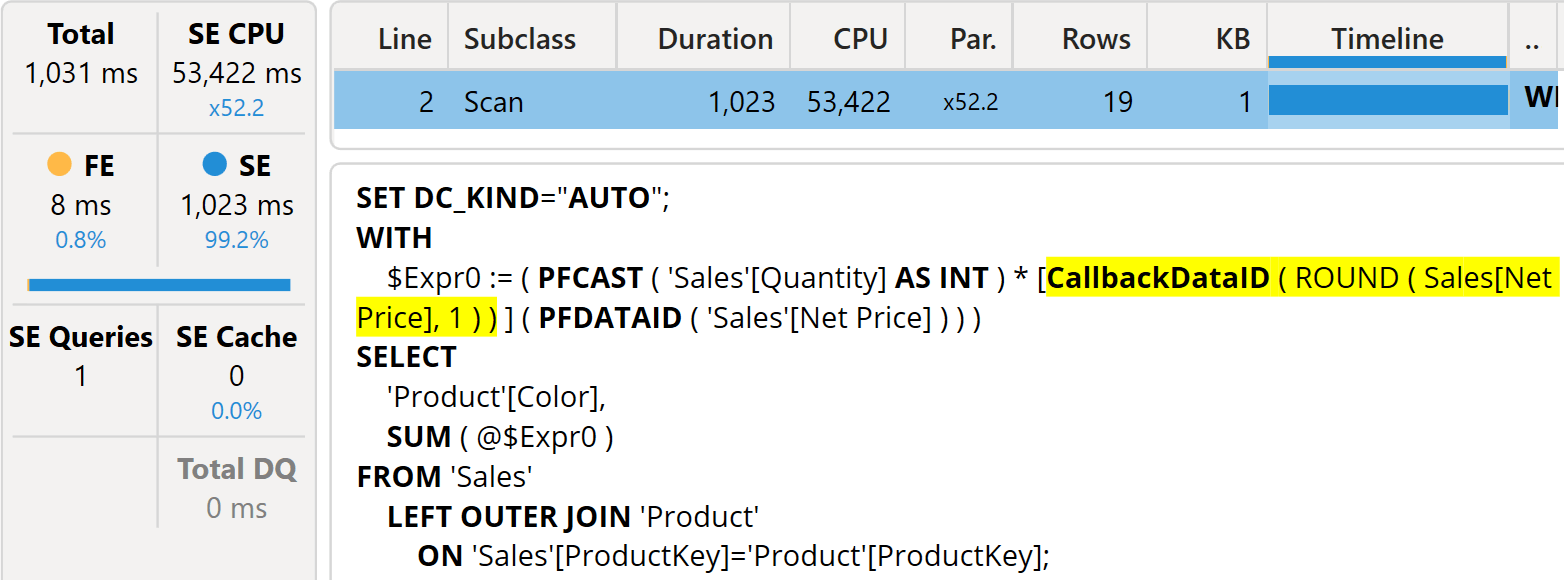
The storage engine CPU went from 203 milliseconds to 53,422. The execution time is still very good, mainly because of parallelism. However, the performance penalty is impressive.
Though expensive, a practical solution would be to materialize the result of ROUND in a calculated column to avoid computing it at query time. However, that technique is very seldom suitable, as it involves increasing the size of the fact table with a potentially large column.
This scenario is extremely common. It is tough to get rid of all callbacks. Besides, callbacks are an essential feature of Tabular, and when used reasonably, they greatly help obtain good performance. But when performance is on the radar, reducing the number of callbacks is always a step in the right direction.
In this scenario, the key to improving performance is to analyze the expression being aggregated:
MEASURE Sales[Sales Amount] =
SUMX (
Sales,
Sales[Quantity] * ROUND ( Sales[Net Price], 1 )
)
We are using ROUND to transform the Sales[Net Price] column. ROUND is being called 200M times, once for each row in Sales. Reducing the number of calls to ROUND will improve performance. Thinking more about the scenario reveals that there is no need to perform the rounding 200M times: there are not 200M different values of Sales[Net Price]. A quick database analysis shows that Sales[Net Price] contains 24,754 distinct values. Therefore, we could compute those 24K rounded values and multiply them with the already-rounded numbers.
The following code achieves our goal:
DEFINE
MEASURE Sales[Sales Amount] =
SUMX (
SUMMARIZE (
Sales,
Sales[Net Price]
),
CALCULATE ( SUM ( Sales[Quantity] ) ) * ROUND ( Sales[Net Price], 1 )
)
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Color],
"Sales Amount", [Sales Amount]
)
The innermost SUMMARIZE retrieves the distinct values of Sales[Net Price]. For each possible value of Net Price, SUMX performs the context transition to compute the sum of quantities sold at that given net price, and eventually, it multiplies the value by the rounded net price.
Once executed, the query shows no callbacks, and the performance is much better.
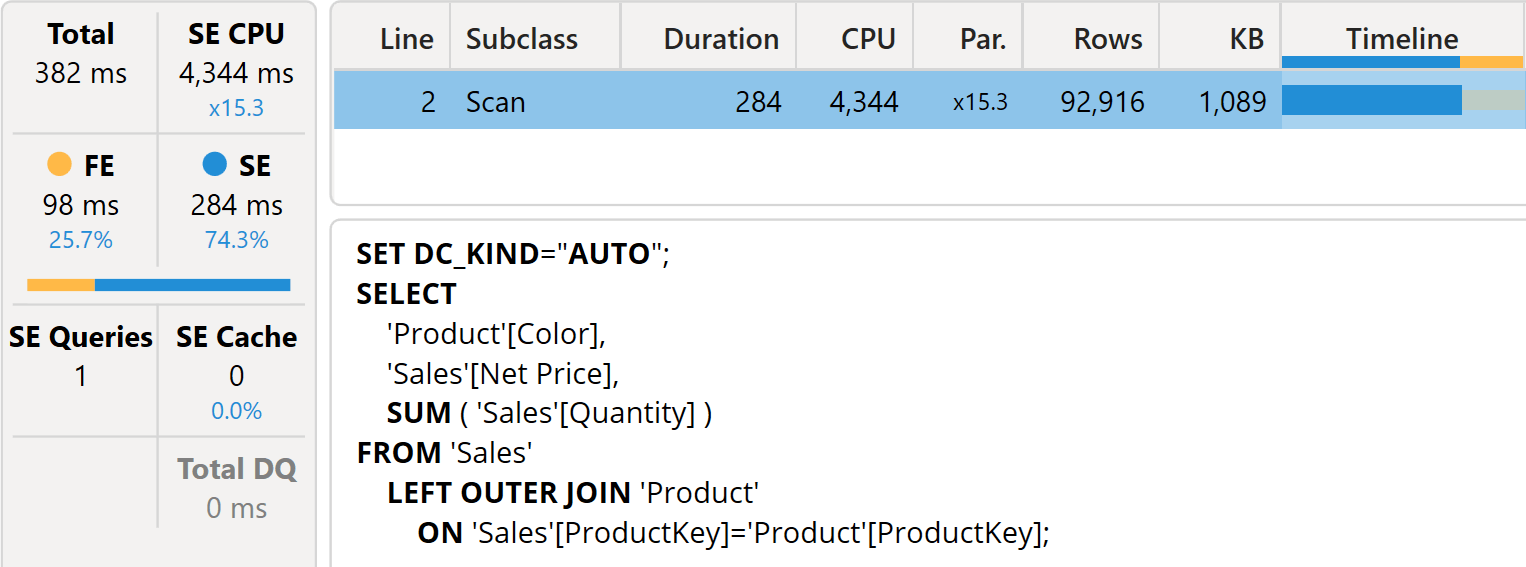
Despite being slower than the original Sales Amount, this version runs much faster because it reduces the number of calls to ROUND. Besides, the invocation of ROUND now occurs in the formula engine, thus removing the need for any communication between the formula engine and the storage engine. Finally, with the need for callbacks removed, the use of the cache system of Tabular is greatly improved.
Before moving on, it is worth noting that this pattern is one of the infrequent scenarios where using variables or making the code more readable hurts performance. Indeed, a good DAX developer would rewrite the measure by introducing a couple of variables with the glorious goal of making the code easier to read:
DEFINE
MEASURE Sales[Sales Amount] =
VAR RoundedNetPrices =
ADDCOLUMNS (
SUMMARIZE ( Sales, Sales[Net Price] ),
"@Rounded Net Price", ROUND ( Sales[Net Price], 1 ),
"@Sum Of Quantity", CALCULATE ( SUM ( Sales[Quantity] ) )
)
VAR Result =
SUMX ( RoundedNetPrices, [@Rounded Net Price] * [@Sum Of Quantity] )
RETURN
Result
EVALUATE
SUMMARIZECOLUMNS ( 'Product'[Color], "Sales Amount", [Sales Amount] )
However, the code now includes ADDCOLUMNS. ADDCOLUMNS always requires two calculations: one to compute the columns being added, and one to compute the distinct values of the original table that columns are to be added to. In our scenario, this requires an additional scan of Sales, thus lowering performance.
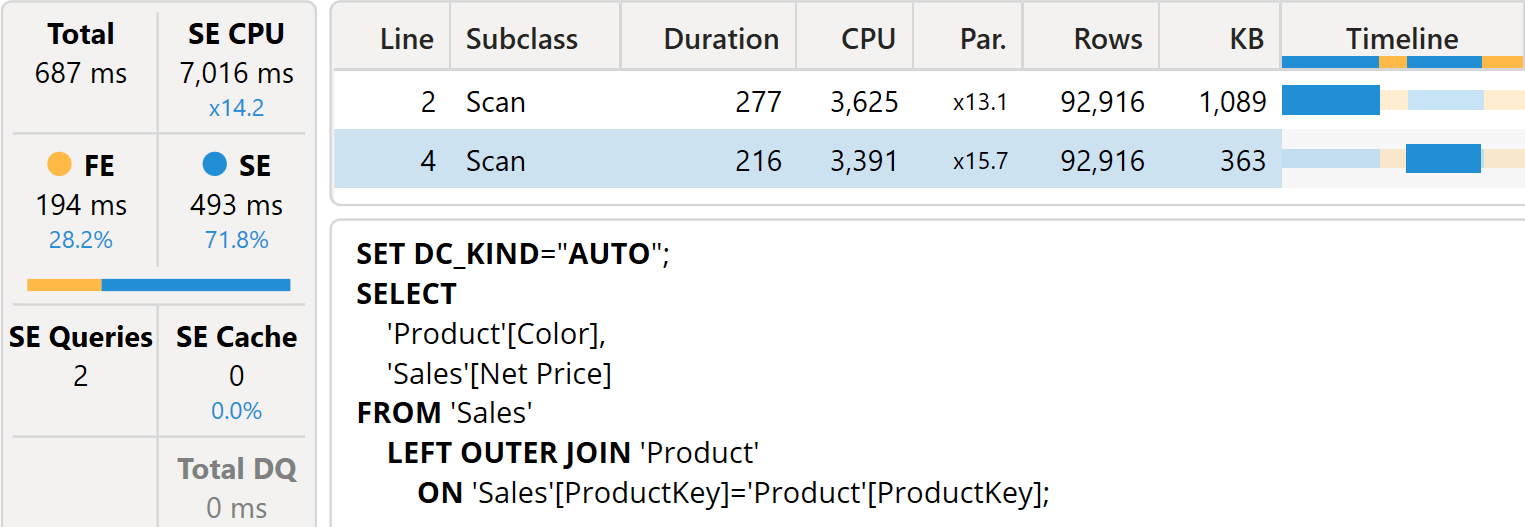
Despite being better than the version that iterates over 200M rows, this last version using ADDCOLUMNS is slower because it requires two scans of Sales rather than the single scan executed by the previous formula, without variables.
Be mindful that the problem is not ADDCOLUMNS in itself. A version using SUMMARIZE alone not only shows the same query plan but also requires a much deeper understanding of the peculiar behavior of SUMMARIZE and of clustering. Therefore, we strongly discourage our readers from using the following approach:
DEFINE
MEASURE Sales[Sales Amount] =
VAR RoundedNetPrices =
SUMMARIZE (
Sales,
Sales[Net Price],
"@Rounded Net Price", ROUND ( Sales[Net Price], 1 ),
"@Sum Of Quantity", CALCULATE ( SUM ( Sales[Quantity] ) )
)
VAR Result =
SUMX ( RoundedNetPrices, [@Rounded Net Price] * [@Sum Of Quantity] )
RETURN
Result
EVALUATE
SUMMARIZECOLUMNS ( 'Product'[Color], "Sales Amount", [Sales Amount] )
If you are unfamiliar with the reason we advise against using SUMMARIZE to add a new column to its output, you can find more information in the article, All the secrets of SUMMARIZE. Get ready for some intense reading!
Conclusions
The presence of callbacks inside iterations over large tables may harm the performance of your DAX code. A careful analysis of the expression being computed may reduce the iterations and decrease the number of calls to functions that require the formula engine.
Despite not always being possible, this optimization produces great results. It should be part of your DAX optimization toolbelt, ready to be used whenever feasible.
Rounds a number to a specified number of digits.
ROUND ( <Number>, <NumberOfDigits> )
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )
Returns the sum of an expression evaluated for each row in a table.
SUMX ( <Table>, <Expression> )
Returns a table with new columns specified by the DAX expressions.
ADDCOLUMNS ( <Table>, <Name>, <Expression> [, <Name>, <Expression> [, … ] ] )