 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariYou have probably heard multiple times the same answer to many questions about DAX and, to be honest, about nearly anything IT-related: “it depends”. Is it fine to create a calculated column, or is it better to avoid it? Yes, no… it depends. Is it better to create one, two, or three fact tables? It depends. Is a composite model the right choice? It depends. However, a few questions have a strong, clear answer, and in this article, we focus on one of those. Is it better to filter a table or a column with CALCULATE? Here, the answer is simple and definite: filter columns, not tables. The same principle is applied to CALCULATETABLE, even though the example in this article only shows CALCULATE.
Whenever you filter a table, you weaken your code in two different ways: performance and correctness. A measure that uses CALCULATE with a table filter will likely be slow and possibly incorrect. A measure that uses a column filter is faster and more robust. However, newbies often find that filtering a table is a good habit, mainly because they replicate in DAX the same habits they had in SQL, or because they have not found a scenario yet where filtering a column or a table really matters. Therefore, in this article, we analyze a simple scenario where a straightforward formula filtering a table returns incorrect results with the additional burden of spending a lot of time to compute those wrong numbers.
The model is a variation of our usual Contoso database. This time, Contoso contains two fact tables: Sales and Receipts. The Sales table keeps track of customers’ orders – including CustomerKey for each transaction – whereas Receipts records stores’ transactions. The Receipts table is not linked to Customer.
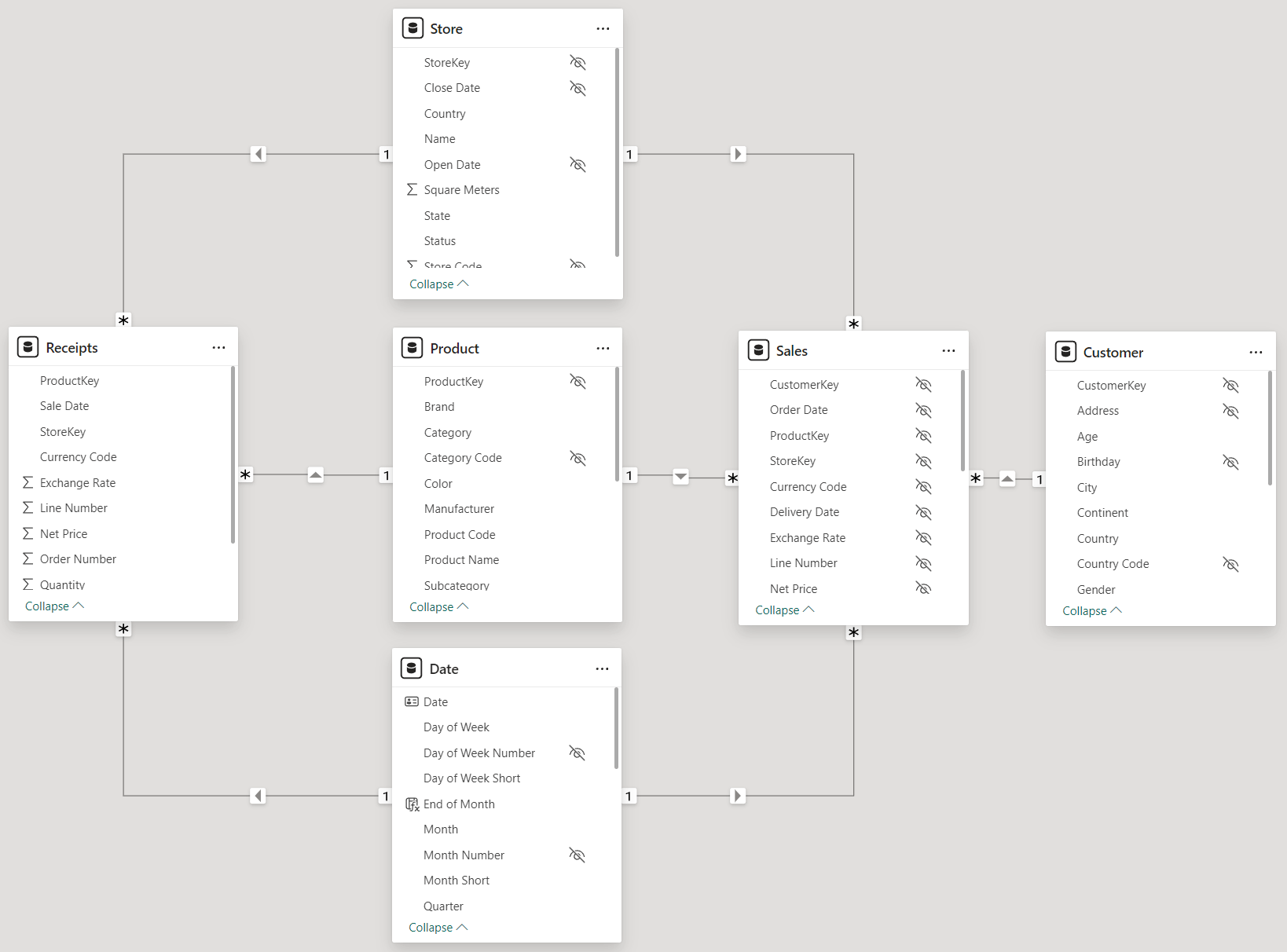
Based on this model, it is easy to compute the volume produced by Sales and Receipts, and the combined amount obtained by summing both:
Sales Amount = SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
Receipts Amount = SUMX ( Receipts, Receipts[Quantity] * Receipts[Net Price] )
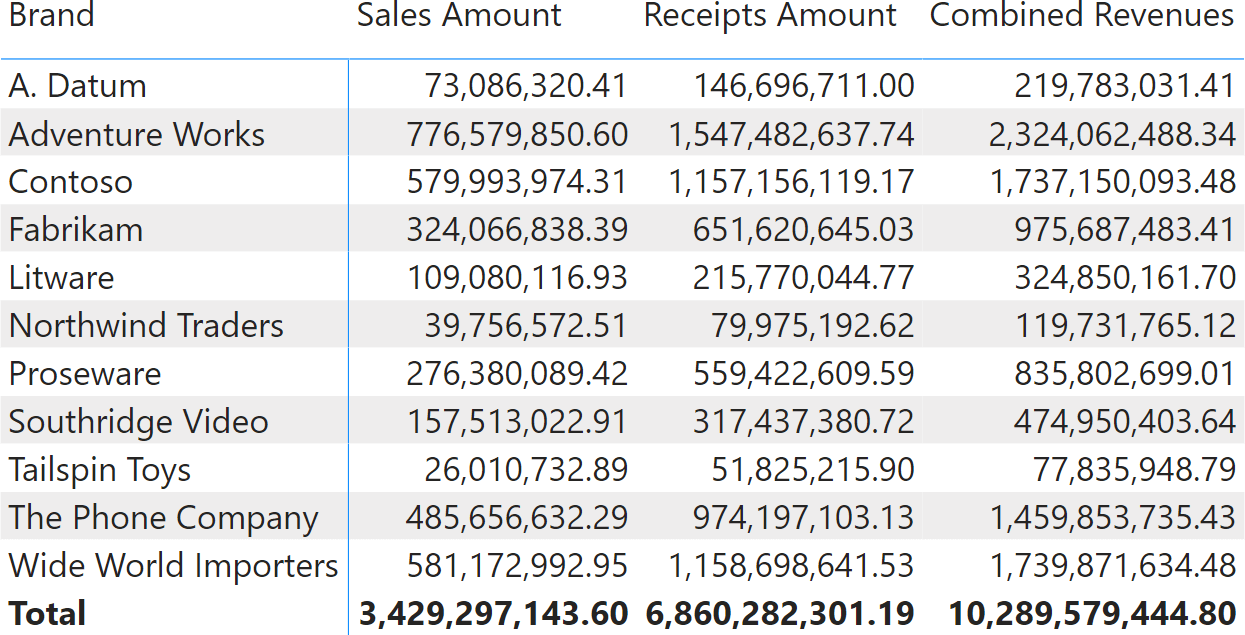
Combined Revenues = [Sales Amount] + [Receipts Amount]
When used in a report, the result is straightforward.
The further requirement is to analyze transactions where the amount is larger than 500 USD. The filter must be applied to both Sales and Receipts transactions through a CALCULATE statement. The first version of the code produces an incorrect result, even though it is not obvious at first sight:
Large Revenues Wrong =
CALCULATE (
[Combined Revenues],
FILTER (
Sales,
Sales[Quantity] * Sales[Net Price] >= 500
),
FILTER (
Receipts,
Receipts[Quantity] * Receipts[Net Price] >= 500
)
)
CALCULATE applies two filters: one on Sales and one on Receipts. Both filters use a similar expression, with the only difference being the table being referenced. Despite it looking fine, the Large Revenues Wrong measure produces incorrect results because it filters over tables rather than columns.
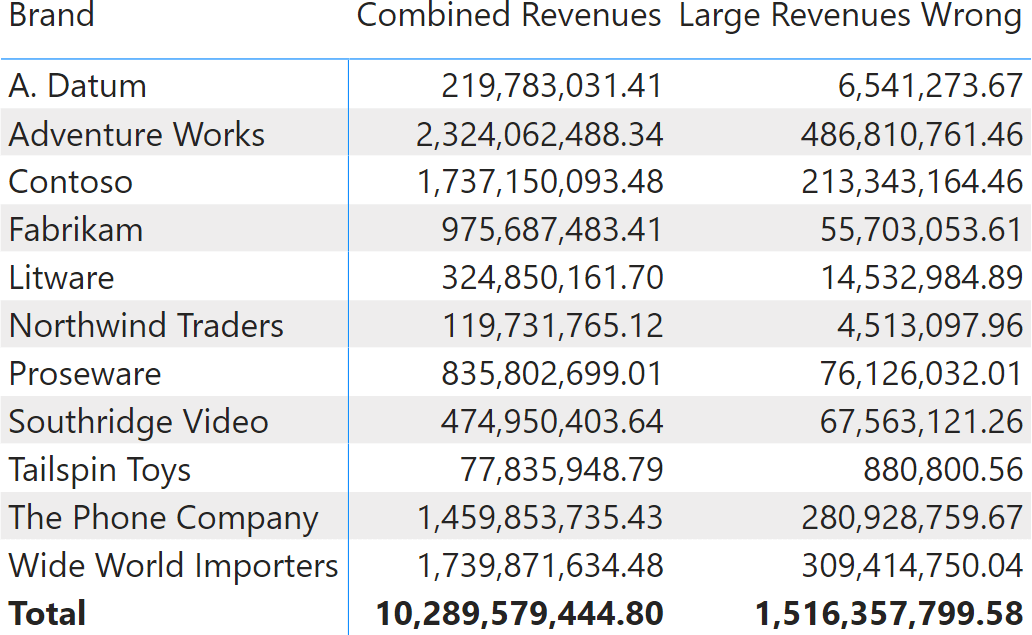
At first sight, there seems to be nothing wrong. The report shows a value that looks reasonable. However, as soon as you show the report to business users, they will complain about the numbers being too small: in their experience, the value of large transactions should be bigger. Moreover, the report takes more than six seconds to render on our test database with 10M rows (the downloadable version is smaller; therefore, the performance impact is lower, despite still being present).
Investigating the topic would require quite some effort, even for seasoned DAX developers, because it requires a good understanding of expanded tables. If you are new to expanded tables in DAX and you want to learn more about them, please take a look at the article, Expanded tables in DAX.
Before we dive into the details, let us look at the correct formula:
Large Revenues Correct =
CALCULATE(
[Combined Revenues],
KEEPFILTERS ( Sales[Quantity] * Sales[Net Price] >= 500 ),
KEEPFILTERS ( Receipts[Quantity] * Receipts[Net Price] >= 500 )
)
The correct formula in Large Revenues Correct does not use table filters. Instead, it uses regular column filters – albeit working on two columns – with KEEPFILTERS. This time, the result is correct.
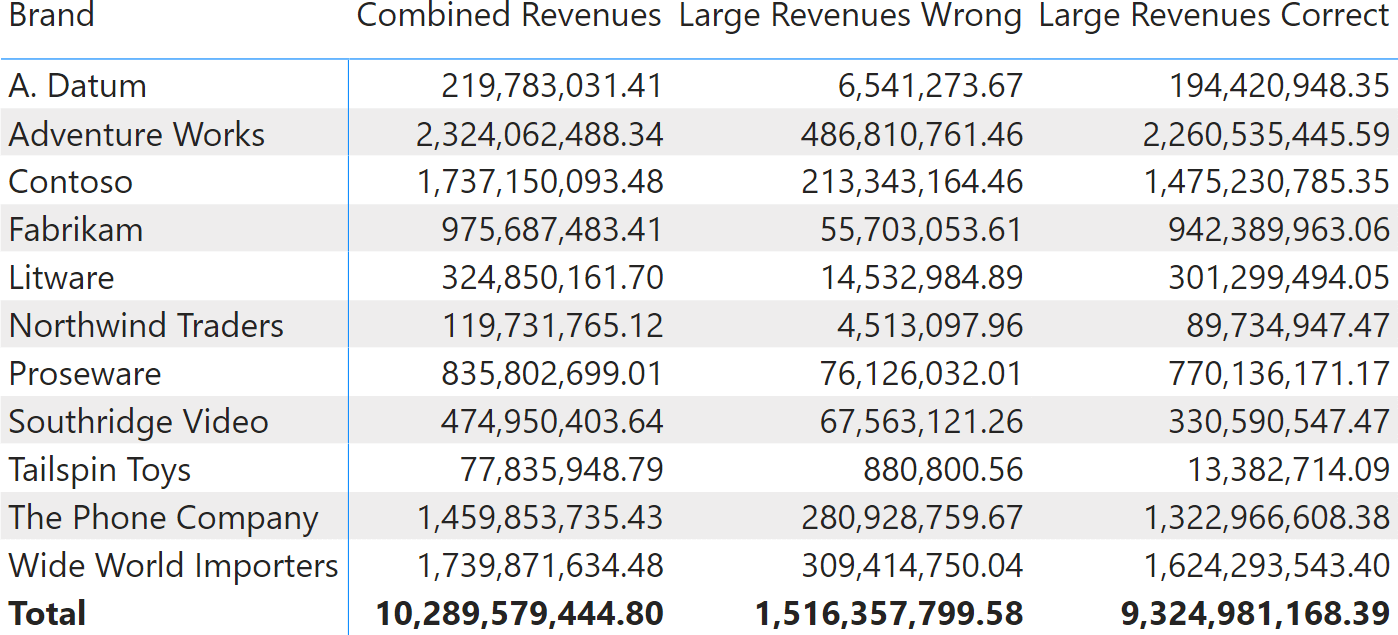
The Large Revenues Correct version filters columns and is way faster and more robust. The Large Revenues Wrong measure has two serious issues: performance and correctness. Let us investigate both issues to understand the rationale behind the best practice of never filtering tables.
We started analyzing the result, which is incorrect because of table expansion. When filtering tables, DAX always places the filter over the expanded version of the table being filtered. Therefore, filtering Sales really means filtering the expanded version of Sales. Because of the existing relationships in the model, the expanded version of Sales includes Date, Store, Customer, and Product. The expanded version of Receipts includes Date, Store, and Product:
Large Revenues Wrong =
CALCULATE (
[Combined Revenues],
--
-- Filters Sales, Customer, Date, Product, and Store
--
FILTER (
Sales,
Sales[Quantity] * Sales[Net Price] >= 500
),
--
-- Filters Receipts, Date, Product, and Store
--
FILTER (
Receipts,
Receipts[Quantity] * Receipts[Net Price] >= 500
)
)
The two table filters intersect on Date, Product, and Store. Therefore, once the two filters work together in the new filter context created by CALCULATE, the result is that only the combinations of Date, Product, and Store that exist in both tables remain visible to evaluate Combined Revenues. Therefore, the sales reported are only the ones where the same product was sold on the same date and store through both a customer order and a direct sale. In other words, the same combination of date, store, and product should exist in both Sales and Receipts. This explains why the numbers reported are smaller than expected: few transactions satisfy the resulting filter.
The Large Revenues Correct measure filters only columns. Therefore, the two filters do not intersect on any column:
Large Revenues Correct =
CALCULATE(
[Combined Revenues],
--
-- Filters Sales[Quantity] and Sales[Net Price]
--
KEEPFILTERS ( Sales[Quantity] * Sales[Net Price] >= 500 ),
--
-- Filters Receipts[Quantity] and Receipts[Net Price]
--
KEEPFILTERS ( Receipts[Quantity] * Receipts[Net Price] >= 500 )
)
Because the two filters do not share any columns, they do not interact. They can be applied independently to the two tables Sales and Receipts, producing the correct result.
The same reasoning also explains why there is a huge performance difference between the two measures. The results are impressive if we execute a test query to evaluate both measures. This is the test query:
EVALUATE
SUMMARIZECOLUMNS (
'Product'[Brand],
"Large Revenues", [Large Revenues Wrong]
)
When executed with the Large Revenues Wrong measure, it runs in more than six seconds.
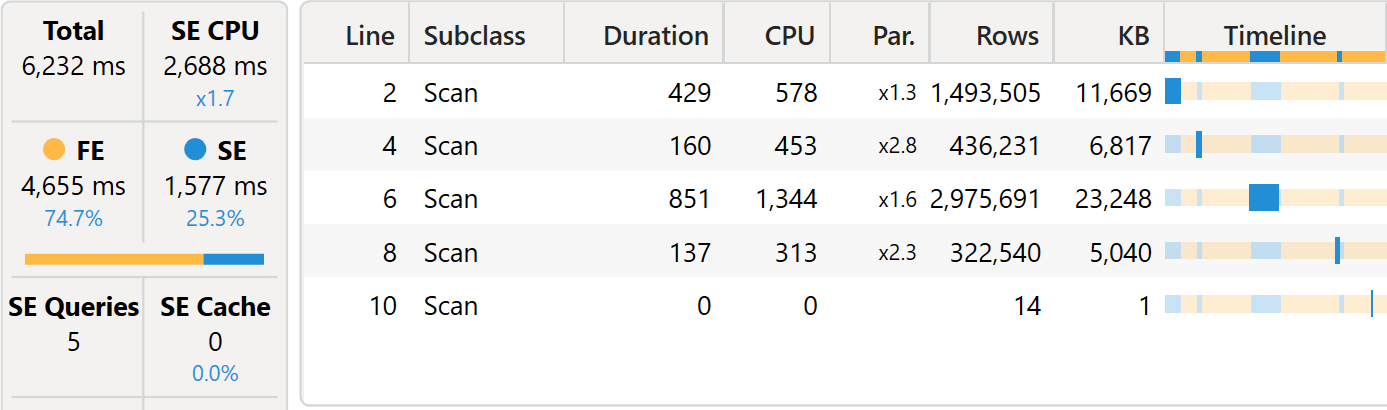
There is a huge amount of time spent on the formula engine. There are also five different storage engine queries: the most expensive ones are rows number 2 and number 6, which have a very similar structure. The following is the storage engine query scanning Receipts. The one scanning Sales is very close, even though it references a different table:
SELECT
'Date'[Date],
'Product'[ProductKey],
'Product'[Brand],
'Store'[StoreKey],
'Receipts'[Quantity],
'Receipts'[Net Price]
FROM 'Receipts'
LEFT OUTER JOIN 'Date'
ON 'Receipts'[Sale Date]='Date'[Date]
LEFT OUTER JOIN 'Product'
ON 'Receipts'[ProductKey]='Product'[ProductKey]
LEFT OUTER JOIN 'Store'
ON 'Receipts'[StoreKey]='Store'[StoreKey]
WHERE
( COALESCE ( ( PFCAST ( 'Receipts'[Quantity] AS INT ) * PFCAST ( 'Receipts'[Net Price] AS INT ) ) ) >= COALESCE ( 5000000 ) ) ;
The storage engine query retrieves columns like Product[ProductKey], Store[StoreKey], and Date[Date], which are not even mentioned in the DAX query. This behavior is due to the fact that DAX scans all the combinations of the keys found in Receipts to later intersect them with the same combinations retrieved from Sales. The resulting datacache is large and slow to process.
If we execute the same test query with the Large Revenues Correct measure, the result is very different.
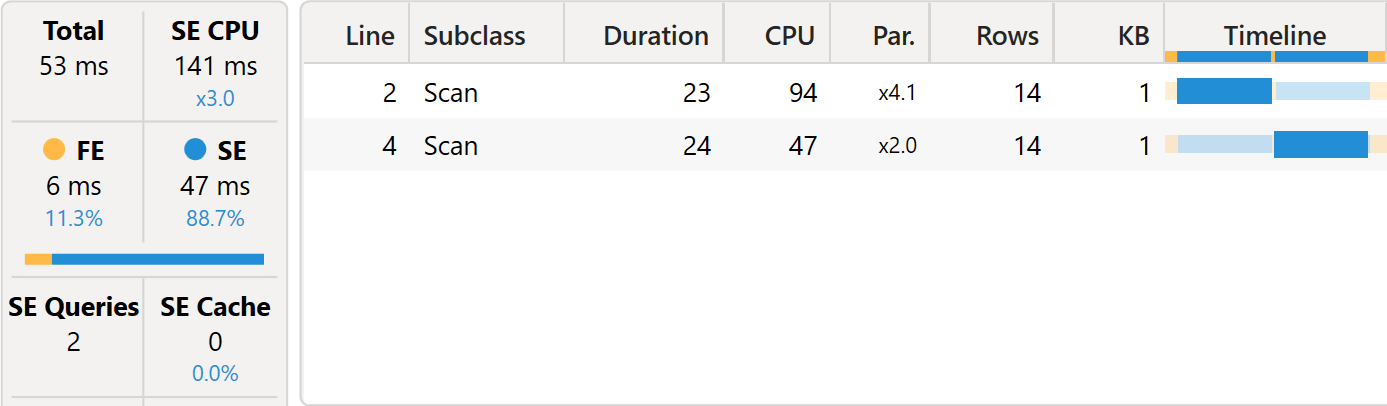
The query runs in 53 milliseconds. Compared with 6,232 milliseconds of the wrong version, this means it is 117 times faster. Moreover, the entire query is composed of two much simpler storage engine queries, again with a very similar structure:
WITH
$Expr0 := (PFCAST('Receipts'[Quantity] AS INT) * PFCAST ('Receipts'[Net Price] AS INT))
SELECT
'Product'[Brand],
SUM ( @$Expr0 )
FROM 'Receipts'
LEFT OUTER JOIN 'Product'
ON 'Receipts'[ProductKey]='Product'[ProductKey]
WHERE
( COALESCE ( ( PFCAST ( 'Receipts'[Quantity] AS INT )
* PFCAST ( 'Receipts'[Net Price] AS INT ) ) ) >= COALESCE ( 5000000 ) ) ;
This time, the storage engine query only materializes 14 rows. The result is grouped by Product[Brand], and the entire calculation takes place in the VertiPaq engine.
Conclusions
The rule is simple: use columns instead of tables as CALCULATE or CALCULATETABLE filters. The rationale behind the rule requires a bit more understanding of the internals of DAX, including expanded tables and the way queries are executed by the DAX engine.
On a small database, the performance impact is much less relevant, even though it is still present. However, the semantic issue is always present in small and large models. Debugging code that includes table filters in CALCULATE and CALCULATETABLE is extremely hard and time-consuming. Hence, just follow the rule: your DAX code will be faster and better.
Evaluates an expression in a context modified by filters.
CALCULATE ( <Expression> [, <Filter> [, <Filter> [, … ] ] ] )
Evaluates a table expression in a context modified by filters.
CALCULATETABLE ( <Table> [, <Filter> [, <Filter> [, … ] ] ] )
Changes the CALCULATE and CALCULATETABLE function filtering semantics.
KEEPFILTERS ( <Expression> )