In Power BI Desktop and SQL Server Analysis Services 2016 you can rely on bidirectional filtering to implement many-to-many relationships. Nevertheless, as powerful as bidirectional filtering is, it cannot handle scenarios where it would generate ambiguous paths among your tables. In this scenario, you face such a data model, where bidirectional filtering is not an option, and you have to solve this complex many-to-many pattern by leveraging some DAX coding.
Scenario
You have products, sales, date that form a standard star schema. BridgePromotionProduct indicates which products where in promotion in a given period of time, and it links date, product and promotion to state that that product was in promotion at that specific date. The granularity of the bridge table is the day.
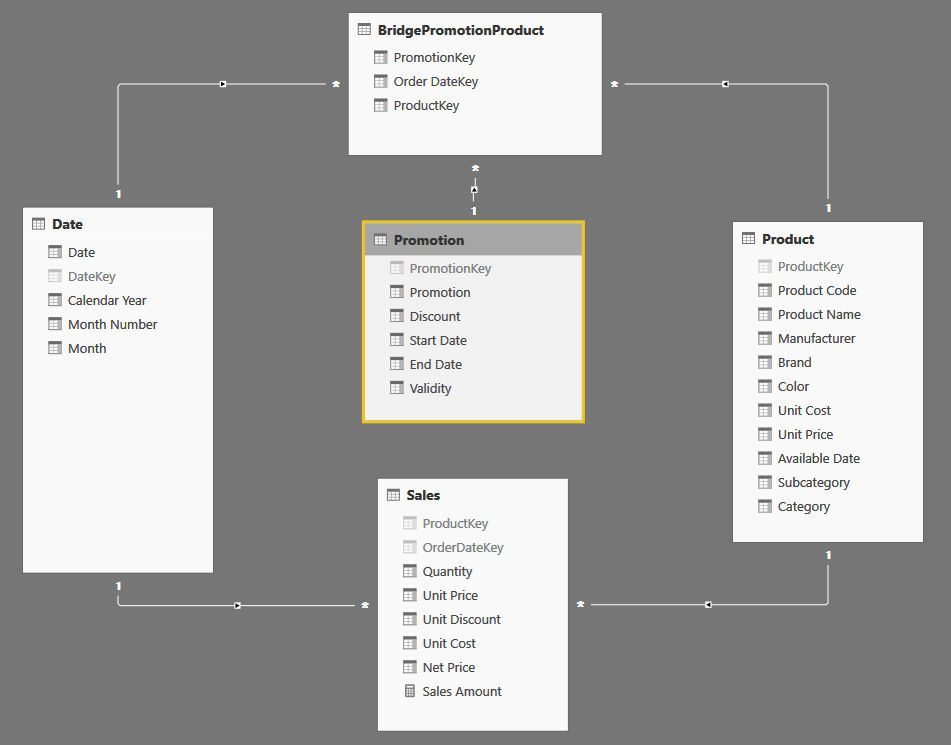
If you enable bidirectional filtering on the relationships starting from BridgePromotionProduct, you create an ambiguous path from Promotion to Sales (should it traverse Product or Date?). Thus, bidirectional filtering is not an available option here.
The Challenge
Create a measure that computes the sales of products that were included in a given promotion (or, in general, in any of the promotions selected in the filter context), only for the period when they were in that promotion. The measure should not report sales of the product when it was not on promotion and it needs to obey to other filters (e.g. a filter on Date), too.
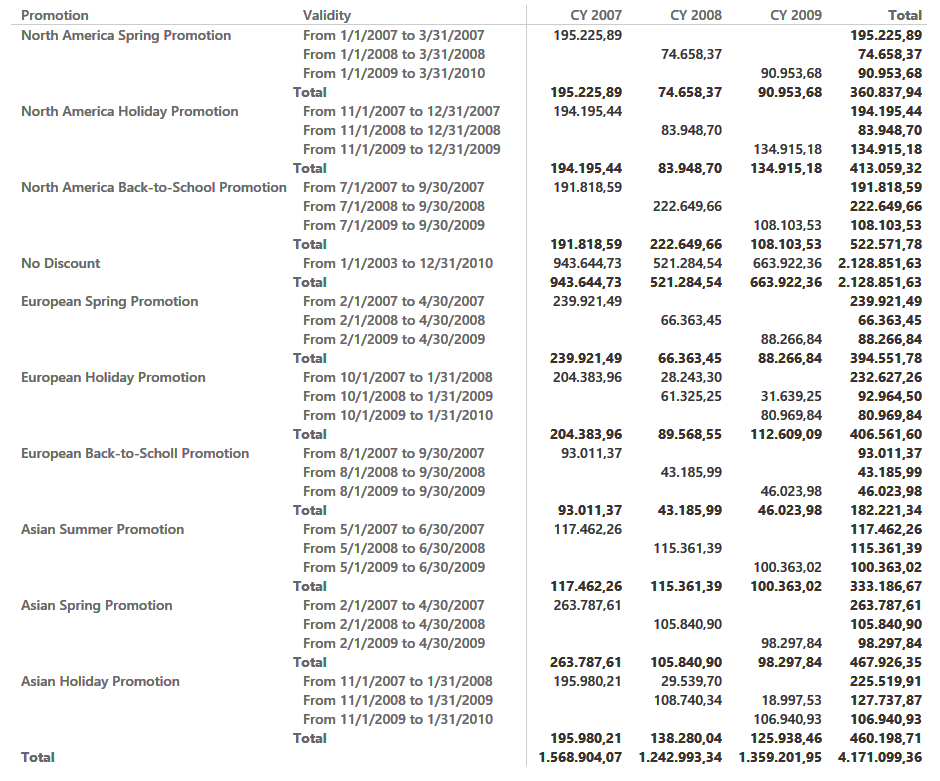
The report should show these values:
Hints
Since you cannot leverage bidirectional filtering, you have to rely on the standard many-to-many pattern to make the formula work. The problem is that this is an intricate example of many-to-many relationships, because the filter starts with a promotion and then it has to traverse two different and independent paths before reaching the fact table with sales.
There are two solutions to this model. One relies on pure DAX code, and it will be painfully slow. The other one requires you to slightly change the data model and runs much faster, even if performance depends on data distribution, and it comes with a strong limitation, since it does not work at the grand total level. You do not need any additional table from the data source, both solutions can be computed on top of this data model only.
Solution
To see the solution, just press the button below.