Topic: VertiPaq
-

The DIVIDE function in DAX is usually faster to avoid division-by-zero errors than the simple division operator. However, there are exceptions to this rule, described in this article through a simple performance analysis. Read more
-
A common best practice is to use CALCULATETABLE instead of FILTER for performance reasons. This article explores the reasons why and explains when FILTER might be better than CALCULATETABLE. Read more
-
VertiPaq is the internal column-based database engine used by PowerPivot and BISM Tabular models. High cardinality columns might be the more expensive parts of a table. If you cannot remove a high cardinality column from a table, by using the… Read more
-
In 2015 I released the first version of VertiPaq Analyzer, a tool to quickly analyze the structure and data distribution of a Tabular model that can be used with Analysis Services and Power BI. Read more
-

SQL 2012 gives you two different xVelocity engines, with different capabilities and different scenarios of implementation, the paper will help you choose the right one or, at least, raise your curiosity about performing more tests on your specific scenario. Read more
-
This article describes the pros and cons of using SQL Server Analysis Services Tabular as the analytical engine in a service or application, based on the experience of companies who have adopted it. Read more
-
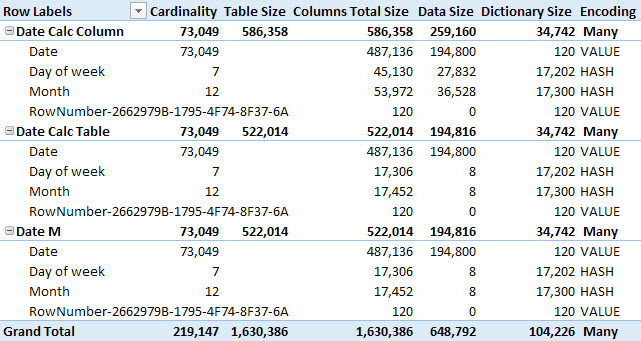
This article compares the differences between calculated columns and calculated tables from a processing and storage point of view. Read more
-
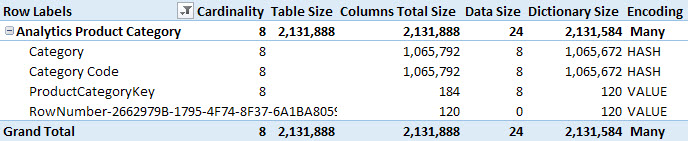
This article explains how to correctly measure the dictionary size of a column in a model created in Power BI, Power Pivot, or Analysis Services Tabular. Read more
-
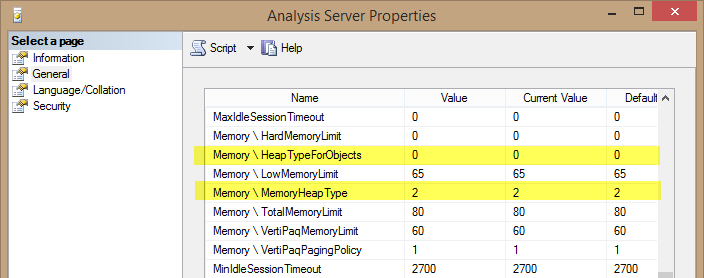
The default memory settings for Analysis Services Tabular might be less than optimal. This article describes why this might happen, and guides you choosing the right configuration. Read more
-
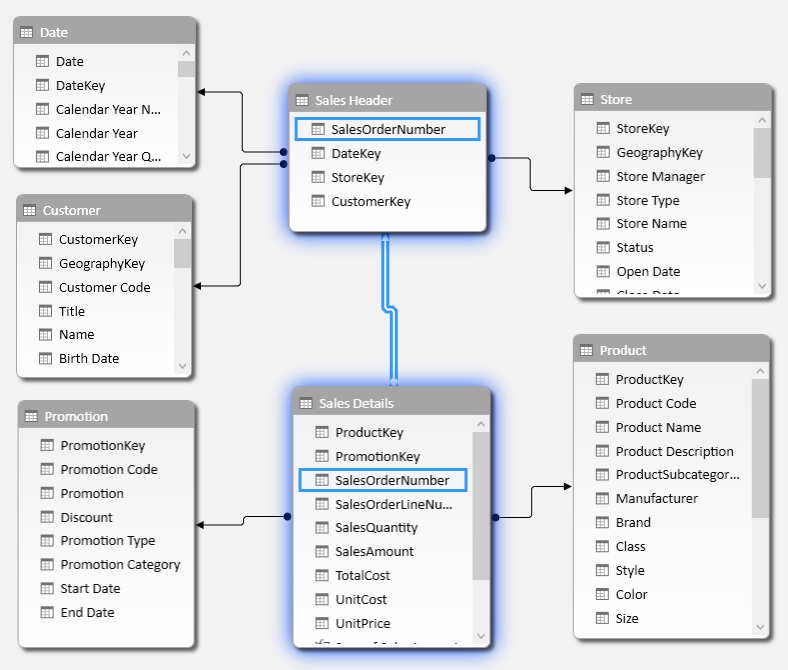
The relationships in a data model queried by DAX are a fundamental part of the engine and simplify the query itself. This article examines the cost of relationships in a data model, providing hints to optimize them. Read more