-
 article
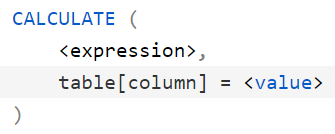
articleFilter Arguments in CALCULATE
A filter argument in CALCULATE is always an iterator. Finding the right granularity for it is important to control the result and the performance. This article describes the options available to create complex filters in DAX. Read more
-
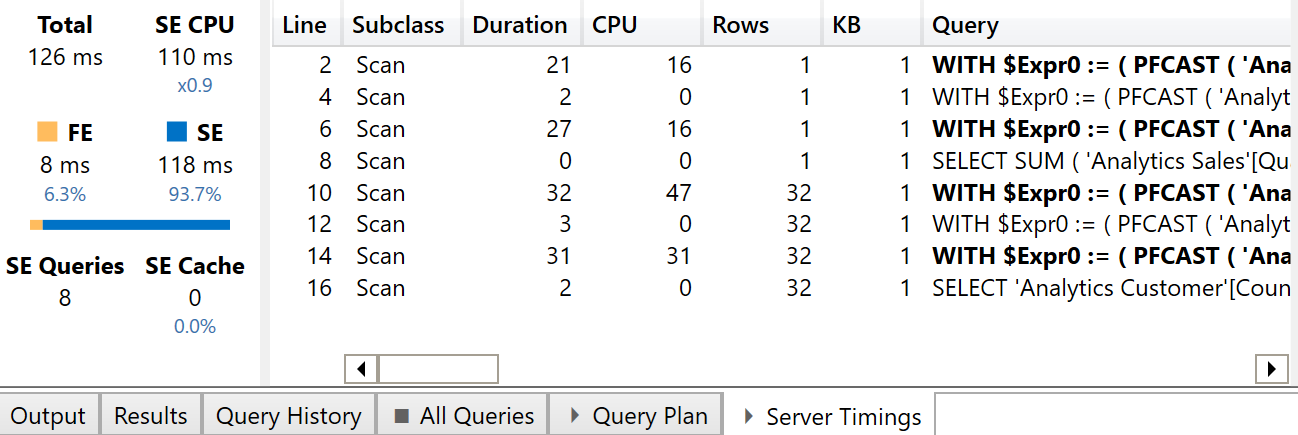
This article describes the reasons why an Excel pivot table may be slow when using the Analyze in Excel feature of Power BI. Read more
-
 article
articleQuerying raw data to Tabular
This article describes how to extract raw data stored in the Tabular engine, used by Analysis Service Tabular, Power BI, and Power Pivot. Read more
-
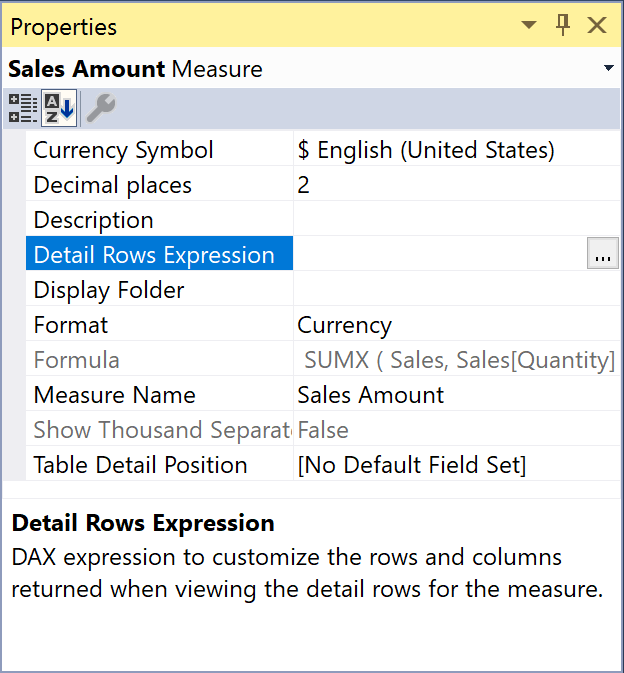
The Detail Rows Expression in a Tabular model provides the user with control over the drillthrough results obtained by showing details of a measure. This article describes typical DAX expressions you can use in this property. Read more
-
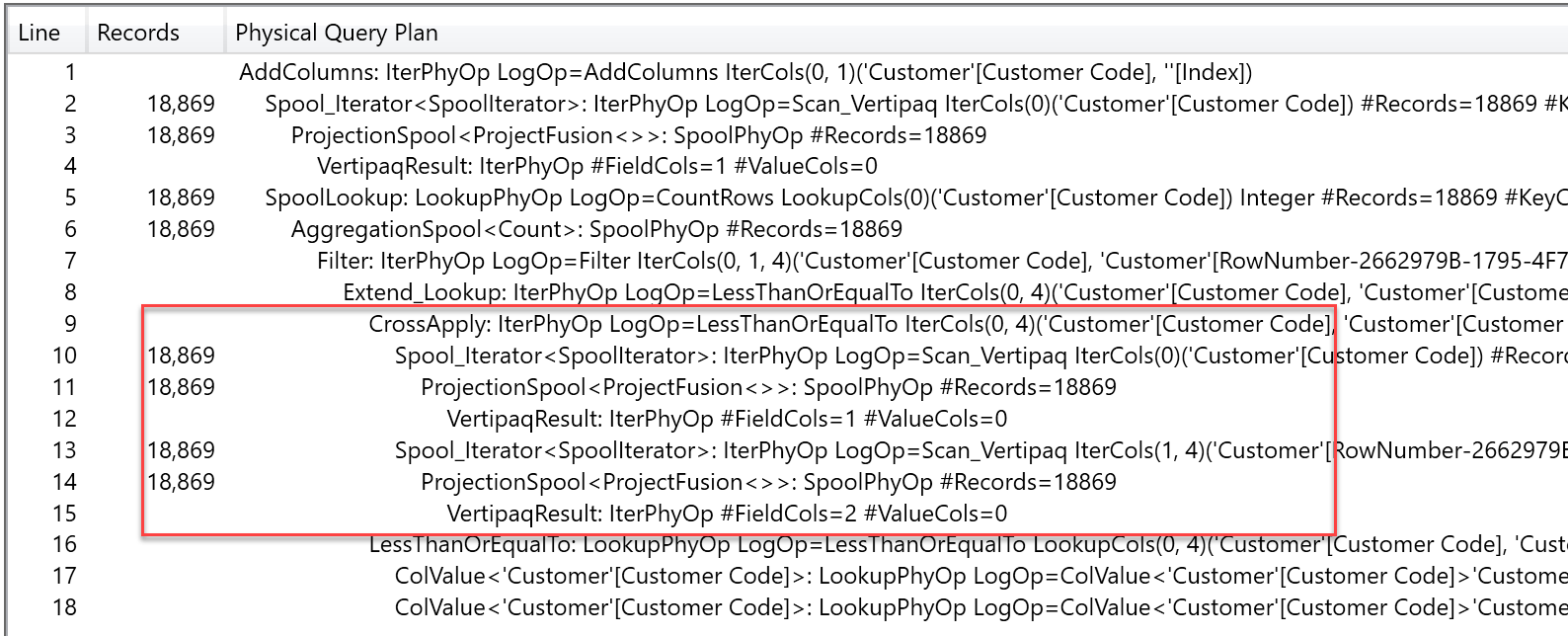
This article presents different techniques to compute a rownumber column in DAX based on a specific ranking, comparing slow and optimized approaches. Read more
-
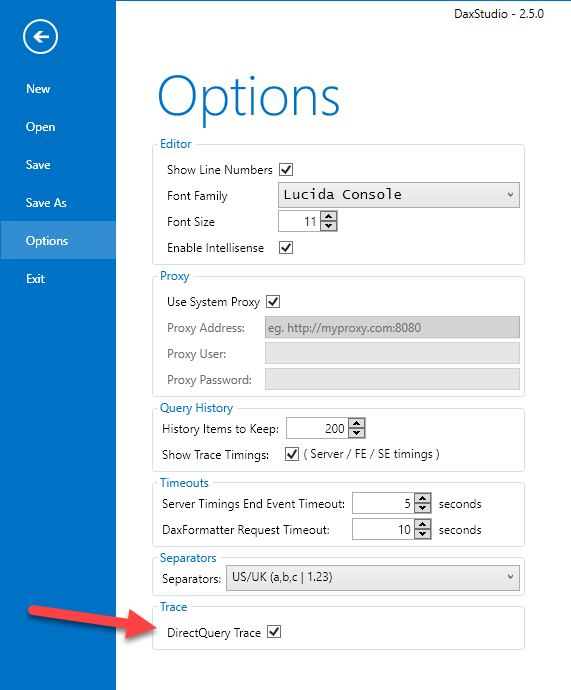
This article describes how DAX Studio can analyze the SQL queries sent to a relational database by Power BI or Analysis Services Tabular in DirectQuery mode. Read more
-
A data model for DAX has three numeric data types: integer, floating point, and fixed decimal number. This article describes them and explains why the fixed decimal number should be used instead of the floating point in most scenarios. Read more
-
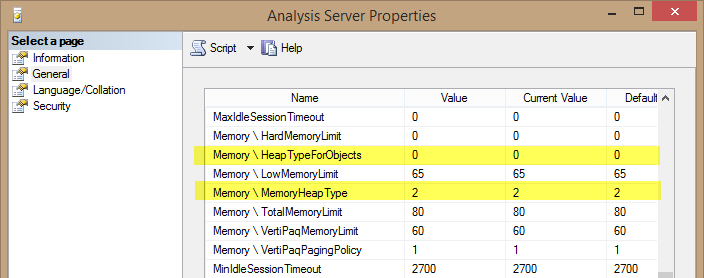
The default memory settings for Analysis Services Tabular might be less than optimal. This article describes why this might happen, and guides you choosing the right configuration. Read more
-
 article
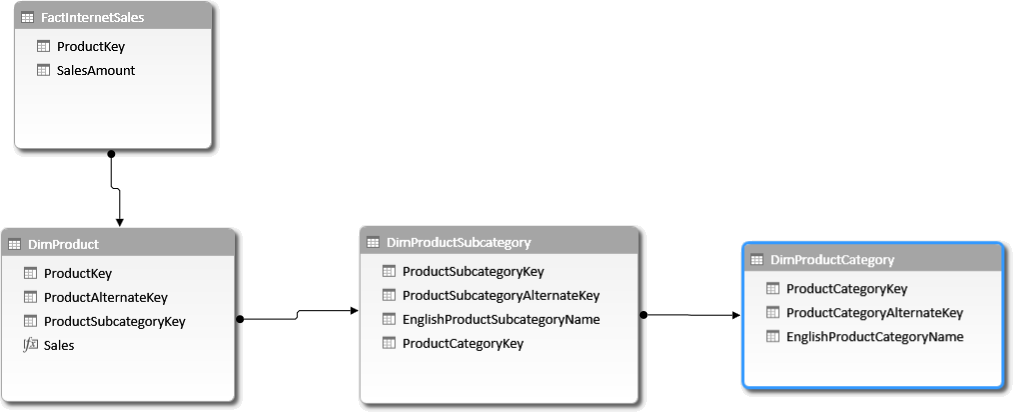
articleAutoExist and Normalization
The autoexist feature used by MDX queries sent to an Analysis Services or Power Pivot data models can have different behaviors depending on the normalization level. This article describes these differences and provides best practices to avoid unwanted results. Read more
-
 article
articleDIVIDE Performance
The DIVIDE function in DAX is usually faster to avoid division-by-zero errors than the simple division operator. However, there are exceptions to this rule, described in this article through a simple performance analysis. Read more