 Marco Russo & Alberto Ferrari
Marco Russo & Alberto FerrariMost newbies start writing DAX code by creating simple calculated columns. There, the formula authoring experience is very close to Excel’s: you can reference columns, add functions and some math, and start enjoying the power of DAX. As soon as the newbies enter the fascinating world of measures, things suddenly change. The same code that was easy to understand in a calculated column stops working in a measure. Columns are no longer there; functions behave in a strange way and the love-hate relationship with DAX quickly shifts towards hate. There is a good reason for this: you are not familiar with the concepts of row context and filter context yet. A calculated column is computed within an existing row context, automatically created by DAX. The presence of a row context makes it easier to author DAX code. Measures do not have a row context, and this is the reason they are harder to author for newbies.
In order to write DAX and to avoid the frustration of dealing with inaccurate numbers or strange errors, it is important to obtain a clear understanding of the row context, the filter context, and how they are used in a DAX formula. In this article, we focus on the row context.
Among the evaluation contexts, the row context is the simplest. The row context tells DAX which row to use when it needs to obtain the value of a column. You can think of the row context as the “current row” in a table. Before elaborating further on the row context, it is important to understand why the row context is so relevant.
DAX expressions operate on columns. For example, a simple calculated column computes the amount of a line in the Sales table:
Amount = Sales[Quantity] * Sales[Net Price]
The result of this calculated column is – as expected – the multiplication of the two columns.
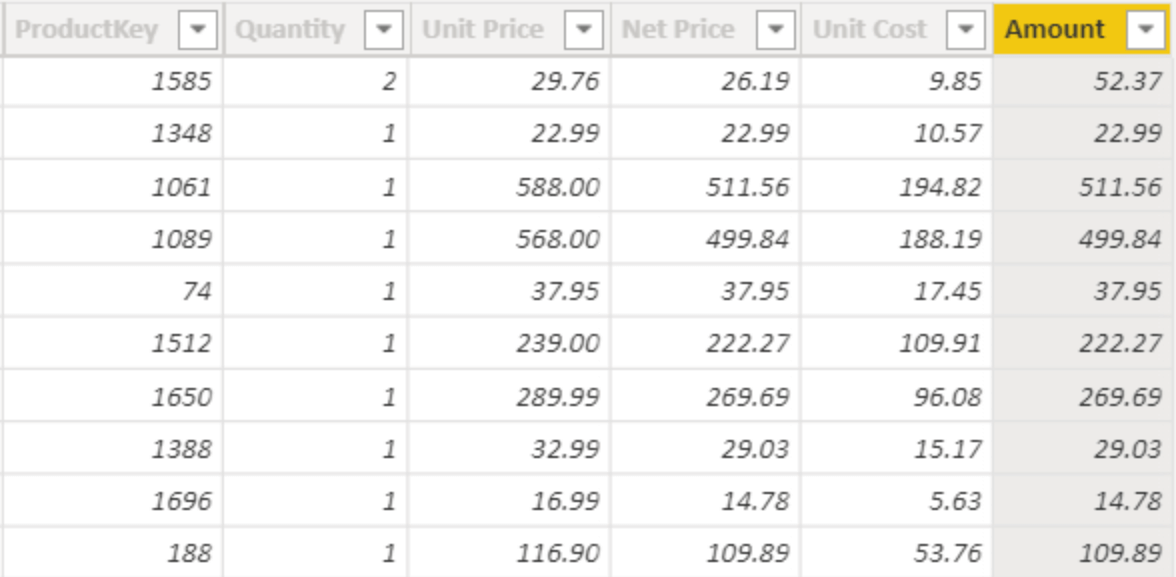
DAX multiplied the value of Sales[Quantity] by the value of Sales[Net Price] row by row, and then stored the result in the same row in the Sales[Amount] column. The key to understanding the row context is in that “row by row”. Indeed, if we remove that part from the previous sentence, it becomes: DAX multiplied the value of Sales[Quantity] by the value of Sales[Net Price]. Without the specification that the calculation occurs row by row, the previous sentence becomes ambiguous. What is the value of Sales[Quantity] in the previous figure, if we did not tell you which row we want the value for? It could be 1, 2, 5, 4 or any other number present in the list. If, on the other hand, we ask you to tell us the value of Sales[Quantity] in the first row with data, then the answer is clear: two. Same for Sales[Net Price]: values are present in specific rows, there is not one unique value unless we specify the row.
When you author a calculated column, DAX implicitly knows that you want to perform a calculation row by row. Therefore, the expression Sales[Quantity] actually means: “looking inside the row where we are computing the value for the calculated column, I want the value for Sales[Quantity]”.
When DAX knows which row to work on in a table, we say that there is a row context open on that table. Specifically, in the example we are looking at, we say that there is a row context in Sales, because the calculated column is in the Sales table. Saying that we have a row context on a table is a nerdy way to say that we know which row we are talking about when performing calculations with the columns of a table.
In the computation of a calculated column, the row context is there by default. Its use is so intuitive that you do not really need to think about it: it is there for you, courtesy of DAX. It provides a simple way to author math over columns into calculated columns. Therefore, why make such a big deal of it? Because the row context might be there, as is the case for a calculated column, but it might also not be there, as it is the case for measures. Indeed, the only scenario where a row context is automatically created, is during the computation of a calculated column. All other scenarios would require you to create the row context yourself if you were to perform calculations over columns. If you need a row context, and you do not even know what it is, then clearly you are in trouble.
As an example, let us say that you do not want a calculated column. You want to compute the Amount expression, this time through a measure. We delete the column, create a new measure and type in the same code:
Amount := Sales[Quantity] * Sales[Net Price]
This time, the code returns an error:
A single value for column ‘Quantity’ in table ‘Sales’ cannot be determined. This can happen when a measure formula refers to a column that contains many values without specifying an aggregation such as min, max, count, or sum to get a single result.
The error message is long and detailed. It also states very clearly where the problem is. Unfortunately, despite being very precise it is not really helping a newbie. A better error message would have been:
Cannot determine the value of Sales[Quantity] because there is no current row; maybe you need a row context on Sales?
We are not claiming that our error message would be clearer. Yet, it introduces the concept of row context and nudges the user to want to understand what that is; it indicates that a row context is needed to provide a value for Sales[Quantity].
With that said, let us elaborate on the error and why it appears. The DAX expression needs to return a value, obtained by a multiplication of two columns. DAX needs to retrieve the value of Sales[Quantity] and Sales[Net Price] to perform the multiplication. Unfortunately, the code being a measure, there is no such thing as a “current row” where to gather the values of the columns. Remember: a calculated column is computed row-by-row, a measure is not. A measure is computed at the aggregate level of the report, potentially scanning millions of rows. Given a choice among millions of rows, which one is the DAX engine supposed to choose?
To make a long story short: without a row context, you cannot access the values of a column. This is the reason why, in measures, you need to use aggregator functions. Indeed, you cannot obtain the value of Sales[Quantity], but you can obtain the value of SUM ( Sales[Quantity] ). Understanding the difference is of paramount importance.
- Sales[Quantity] is the value of the Quantity column, in the Sales table, for the current row. Without a current row, the expression does not make any sense.
- SUM ( Sales[Quantity] ) is the sum of the Sales[Quantity] column for all the rows. It is a number. It does not require a current row, because all the rows are aggregated together. There is a billion rows? We calculate the total over a billion rows; no current row required.
Unfortunately, in our example, replacing columns with SUM does not help. The measure would become the following:
Amount := SUM ( Sales[Quantity] ) * SUM ( Sales[Net Price] )
Despite it working, this formula is wrong. It is no longer the aggregation of a multiplication. Instead, it became the multiplication of two aggregations. It does produce a number, but it produces an inaccurate number. What we would like to obtain is the following:
Amount := SUM ( Sales[Quantity] * Sales[Net Price] )
The previous code is not even syntactically correct. SUM works with columns, but it cannot aggregate expressions. You can obtain the sum of a column, but not the sum of a multiplication.
We have now reached a point where we cannot compute the multiplication without a row context, and we cannot aggregate a single column, because we want to aggregate the multiplication. It is time to learn how to create a row context in a measure.
A row context is created by any iterator. An iterator does what its name implies: it iterates. It scans a table row by row and it computes an expression during the iteration. Row by row. During the iteration, there is a current row: the row that is currently being iterated over by the iterator. Therefore, during the iteration, the expression can use individual column values.
An iterator requires a table to iterate over, and that table needs to contain all the columns required for the expression. We have a table like that: Sales. Therefore, the correct way of authoring the Sales[Amount] measure is to use the SUMX iterator, which iterates over a table, computes an expression row by row, and aggregates its result with a sum:
Amount := SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )
In its simplicity, this expression already contains several important details:
- Outside of SUMX, there is no row context. It is a measure!
- SUMX iterates over Sales, creating a row context over Sales. Because it iterates!
- The row context is scanning Sales, therefore you can reference any column in Sales.
- Inside SUMX, in its second argument a row context is created by SUMX while it scans Sales.
Let us see these details by adding comments to the measure:
Amount :=
--
-- Outside of SUMX, there is no row context
--
SUMX (
Sales, -- Sales is evaluated in the outer context
Sales[Quantity] * Sales[Net Price] -- The multiplication is evaluated in the row context
)
--
-- Outside of SUMX, the row context is no longer there
--
Another important detail about the row context is that it provides a value only for the columns of the table being iterated over. If you create a row context on Sales, you cannot access columns in Product for example. Likewise, if you create a row context on Product, then you cannot access columns in Sales. If you need to access columns in another table linked through a relationship, then you can rely on the RELATED and RELATEDTABLE functions, which we cover in other articles. Right now, the important takeaway is that a row context iterates over a table, provides access to any column within the table being iterated through, and nothing else.
A very important aspect of the row context is that the row context iterates through a table row by row. It does not filter the table. Most newbies make the mistake of thinking that a row context is filtering tables. This is not the case. The only evaluation context that filters tables is the filter context. The row context does not filter the table it is iterating over.
We can check this behavior by rewriting the calculated column, this time using the code of the measure. Because we do not want to delete the measure, we create a calculated column named Amount Col:
Amount Col =
SUMX (
Sales, -- Sales is evaluated in the outer context
Sales[Quantity] * Sales[Net Price] -- Evaluated in the row context introduced by SUMX
)
The result will look quite surprising in the beginning of your DAX journey: the column shows the same value for all the rows.
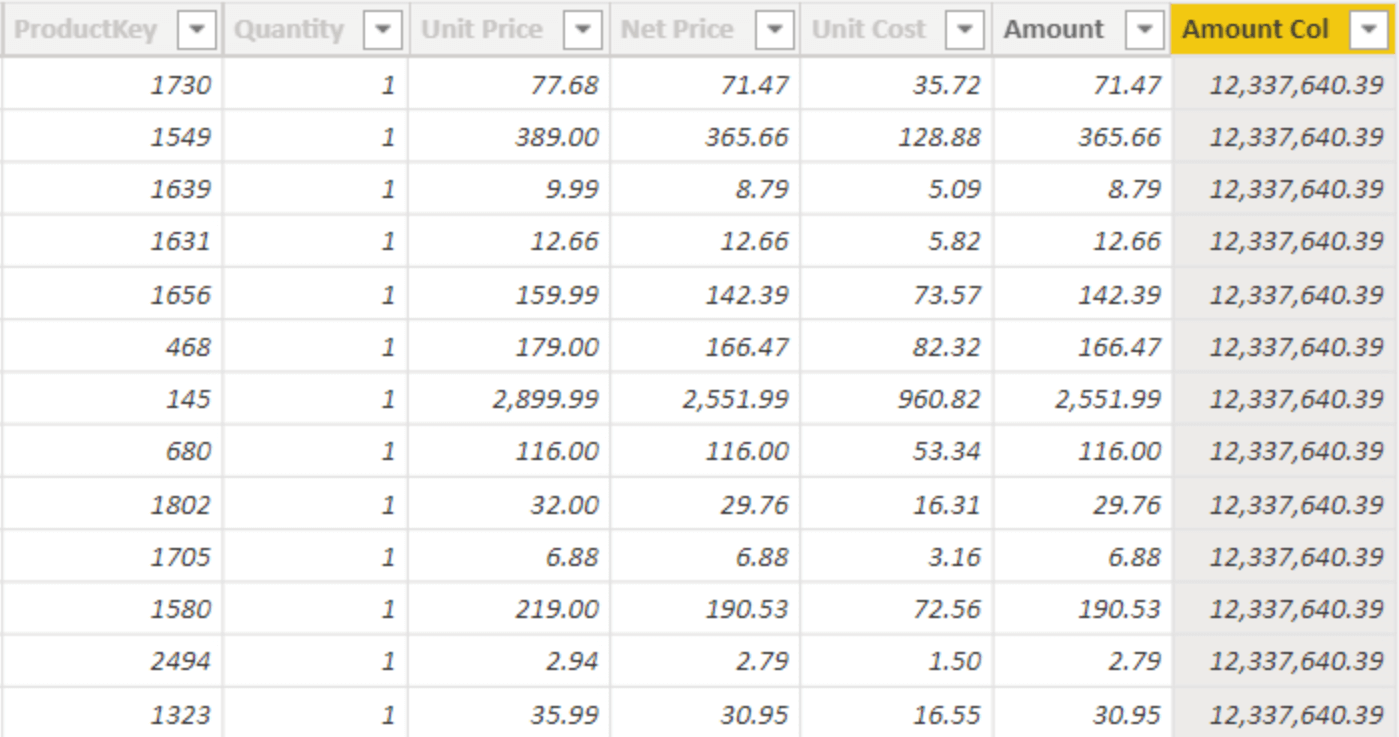
Understanding the reason why this column does not compute the same value as Amount is of paramount importance.
Intuitively, we tend to think that because a calculated column is computed in a row context that contains only the current row, the Sales table is also filtered and showing only the current row. This is not the case. The row context is iterating over Sales and it is positioned on the current row. But there is another iterator: SUMX. SUMX introduces a new row context that iterates – again – over Sales. Sales is not being filtered because as we already said, the row context does not filter. Therefore, SUMX iterates over the entire Sales table and the multiplication takes place in the row context introduced by SUMX. Because SUMX is scanning the entire Sales table, as a consequence the result is the grand total of Amount, for each and every row. In other words, the previous code could be written as follows:
Amount Col =
SUMX (
Sales, -- Sales is evaluated in the outer context
Sales[Amount] -- Evaluated in the row context introduced by SUMX
)
For a complete explanation, it is useful to add that standard aggregators behave the same way. Another common mistake of DAX newbies is thinking that SUM and SUMX are two different functions. This is not the case. SUM is nothing but a simplified version of SUMX: we call it syntax sugar. SUM ( Sales[Quantity] ) is internally translated into SUMX ( Sales, Sales[Quantity] ). Therefore, a regular aggregator like SUM, AVERAGE, MIN or MAX behaves the same way an iterator does.
This is the reason why a calculated column computing SUM ( Sales[Quantity] ) produces the grand total of Sales[Quantity] on each row. Here is the code of the column:
SumOfQuantity = SUM ( Sales[Quantity] )
The result, as you see, is the same number on every row.
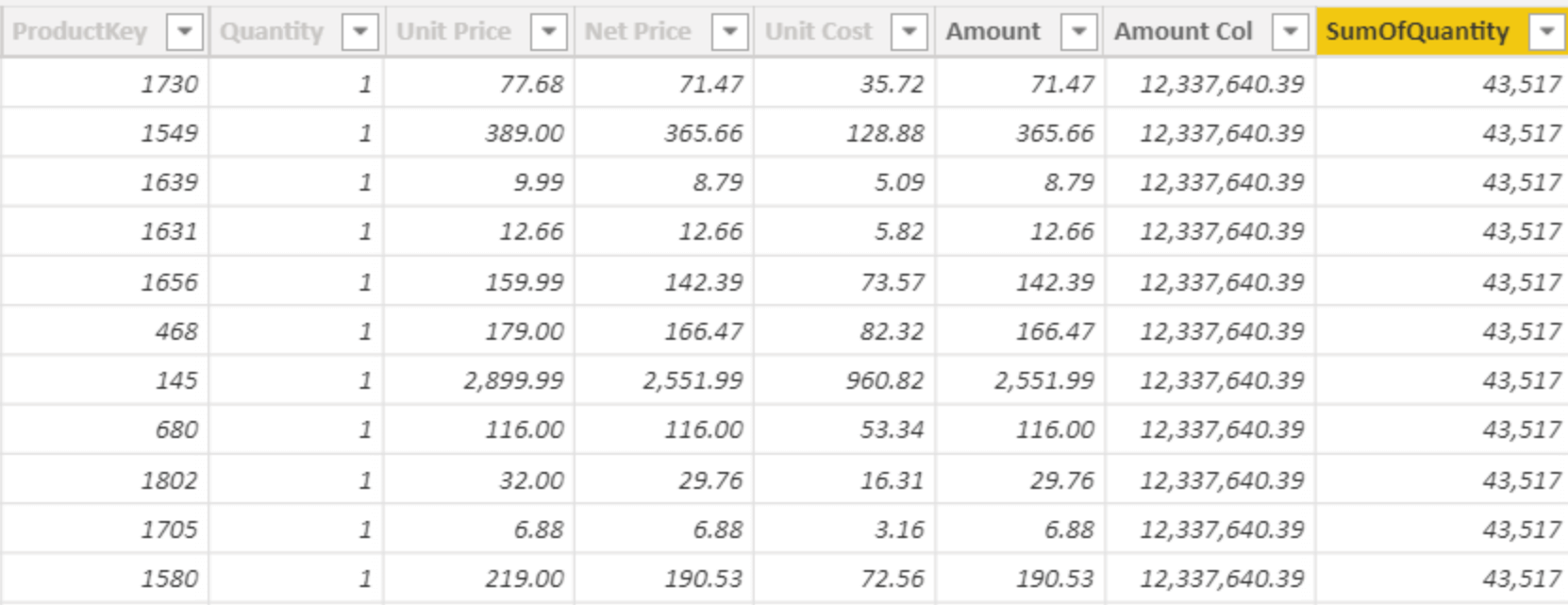
Though you might find this behavior surprising…. It is what it is. DAX is a very logical language, with well-defined semantics based on evaluation contexts. The row context does not filter, it iterates.
Before leaving the topic, we analyze with you a simple piece of code in order to evaluate your understanding of the row context. The following code serves no other purpose than to understand the row context the right way:
Test :=
SUMX (
FILTER (
Customer,
Customer[Country] = "United States"
),
SUMX (
FILTER (
Sales,
Sales[CustomerKey] = Customer[CustomerKey] &&
Customer[Age] >= 20
),
IF (
Customer[Age] <= 45,
Sales[Quantity] * Sales[Net Price],
Sales[Quantity] * Sales[Unit Price]
)
)
)
Do not type the code in Power BI, just read it carefully and answer a few simple questions:
- Is there a row context at line 8? If yes, what is it iterating over?
- Is there a row context at line 10? If yes, what is it iterating over?
- Does the check Customer[Age] >= 20 work at line 11? Whether you answer yes or no, what is the reason for your answer?
- Does the check Customer[Age] <= 45 work at line 14? Whether you answer yes or no, what is the reason for your answer?
Take some time to answer the questions before moving further, then check your answers with the ones provided in the next paragraph:
- Yes, there is a row context introduced by FILTER, iterating over Customer.
- Yes, there is another row context, introduced by SUMX, iterating through the result of FILTER.
- Yes, it works. There are actually two row contexts at line 11: one introduced by the outer SUMX which is iterating over Customer, one introduced by the inner SUMX iterating the result of FILTER that iterated over Sales. Therefore, we can access any column in either Sales or Customer.
- Again yes: this time the inner row context is on the result of the inner FILTER, iterating over a subset of Sales. Still, a row context is active in both Sales and Customer.
Mastering the row context is only a tiny part of what is needed to actually master the DAX language. Tiny, yet extremely important. The row context is one of the two evaluation contexts in DAX; the other evaluation context is the filter context. We cover the filter context in another article.
Evaluation contexts are the foundation of the entire DAX language. This is the reason we created a suite of books, courses, and videos about these important concepts. In this article, we merely scratched the surface. If you want to learn more, then start by watching the free Introducing DAX video course. Once you have digested that content, proceed with one of our in-person classroom courses and/or with watching the Mastering DAX online video course.
Adds all the numbers in a column.
SUM ( <ColumnName> )
Returns the sum of an expression evaluated for each row in a table.
SUMX ( <Table>, <Expression> )
Returns a related value from another table.
RELATED ( <ColumnName> )
Returns the related tables filtered so that it only includes the related rows.
RELATEDTABLE ( <Table> )
Returns the average (arithmetic mean) of all the numbers in a column.
AVERAGE ( <ColumnName> )
Returns the smallest value in a column, or the smaller value between two scalar expressions. Ignores logical values. Strings are compared according to alphabetical order.
MIN ( <ColumnNameOrScalar1> [, <Scalar2>] )
Returns the largest value in a column, or the larger value between two scalar expressions. Ignores logical values. Strings are compared according to alphabetical order.
MAX ( <ColumnNameOrScalar1> [, <Scalar2>] )
Returns a table that has been filtered.
FILTER ( <Table>, <FilterExpression> )
Articles in the DAX 101 series
- Computing running totals in DAX
- Counting working days in DAX
- Summing values for the total
- Year-to-date filtering weekdays in DAX
- Creating a simple date table in DAX
- Automatic time intelligence in Power BI
- Using CONCATENATEX in measures
- Previous year up to a certain date
- Sorting months in fiscal calendars
- Using USERELATIONSHIP in DAX
- Mark as Date table
- Row context in DAX
- Filter context in DAX
- Introducing CALCULATE in DAX
- Understanding context transition in DAX
- Using KEEPFILTERS in DAX
- Variables in DAX
- Using RELATED and RELATEDTABLE in DAX
- Introducing ALLSELECTED in DAX
- Introducing RANKX in DAX