 Marco Russo
Marco RussoUPDATE 2020-11-11: The DAX Studio option described in this article is not required when you connect to Power BI, Azure Analysis Services, or SQL Server Analysis Services 2019. If you use previous versions of SQL Server Analysis Services up to version 2017, you have to enable the setting described in this article to analyze DirectQuery requests.
The recent release of DAX Studio 2.5 introduced a new feature to analyze MDX and DAX queries running in DirectQuery mode on a Power BI or an Analysis Services (SSAS) Tabular model. From an architectural point of view, you can imagine DirectQuery as an alternative storage engine to VertiPaq (which uses an in-memory compressed columnar store). When you use a model in DirectQuery mode, the formula engine sends requests to the storage engine in forms of SQL queries. You can capture them using SQL Profiler, but in order to analyze a specific MDX or DAX query, having the query captured in DAX Studio makes your life easier.
If you want to capture DirectQuery trace events, you have to enable a particular setting in the Options of DAX Studio, as you see in the following screenshot.
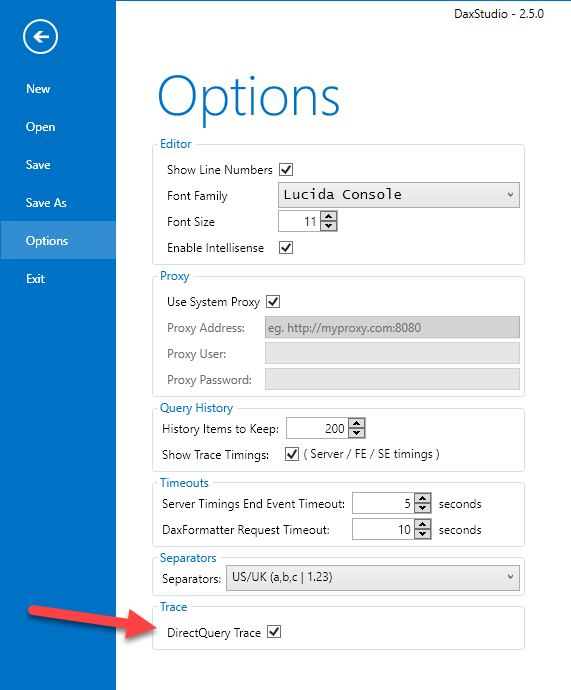
The reason why we created a specific setting to explicitly enable DirectQuery Trace is because the current implementation of the trace events in Analysis Services and Power BI does not work well with the filter we use in DAX Studio. We used a particular workaround to capture the events that were interesting, which has the side effect of making more expensive the trace capture of any session, even of those that are not using DirectQuery. In practice, DAX Studio receives more events than necessary and has to apply a filter client-side, instead of applying the filter server-side.
Microsoft already fixed the issue, but we’ll wait a wide distribution of the fix in Analysis Services and Power BI before restoring the original server-side filter, which will make this setting obsolete.
Until then, we suggest to enable the DirectQuery Trace setting only when you run DAX Studio over models in DirectQuery mode, and possibly when the server does not have a large workload produced by other users.
Once you activate DirectQuery Trace, when you enable the Server Timings trace connecting to a model in DirectQuery mode, you will see that the storage engine queries contain SQL queries instead of the xmSQL code sent to VertiPaq. In the following example, you see the two SQL queries sent for a DAX query using ADDCOLUMNS and SUMMARIZE.
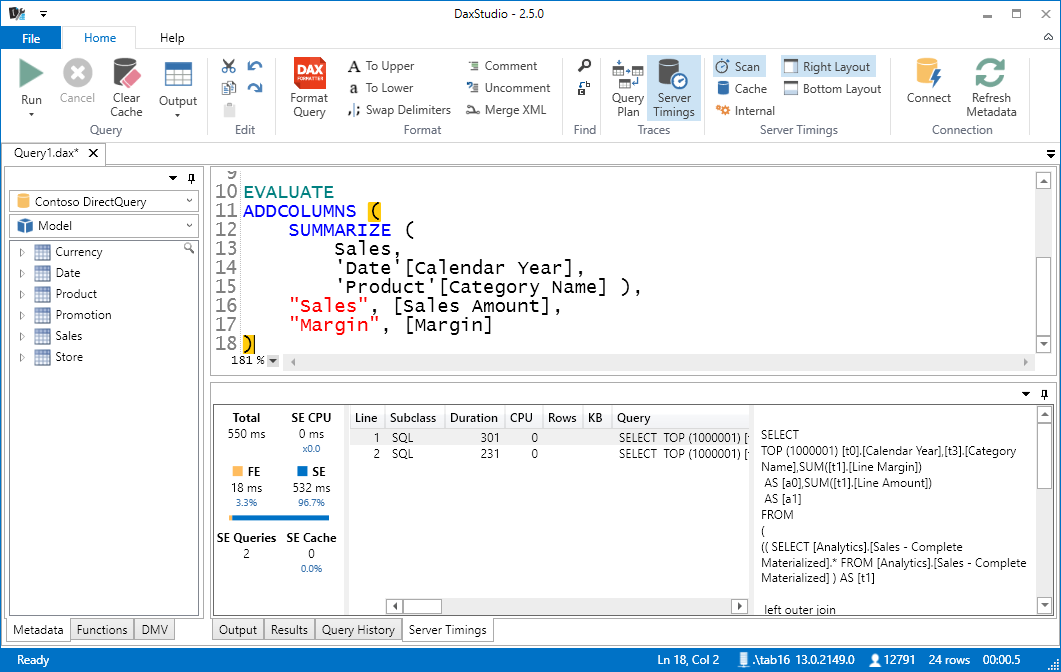
The CPU count will be always 0, because the entire time spent in SQL Server is considered as waiting time by the Tabular engine. However, you still can see the difference between Formula Engine (FE) and Storage Engine (SE) in duration. For example, you can immediately measure the improvements obtained by changing the DAX code, as in the following example that returns the same result of the previous query by using the SUMMARIZECOLUMNS function instead of ADDCOLUMNS/SUMMARIZE.
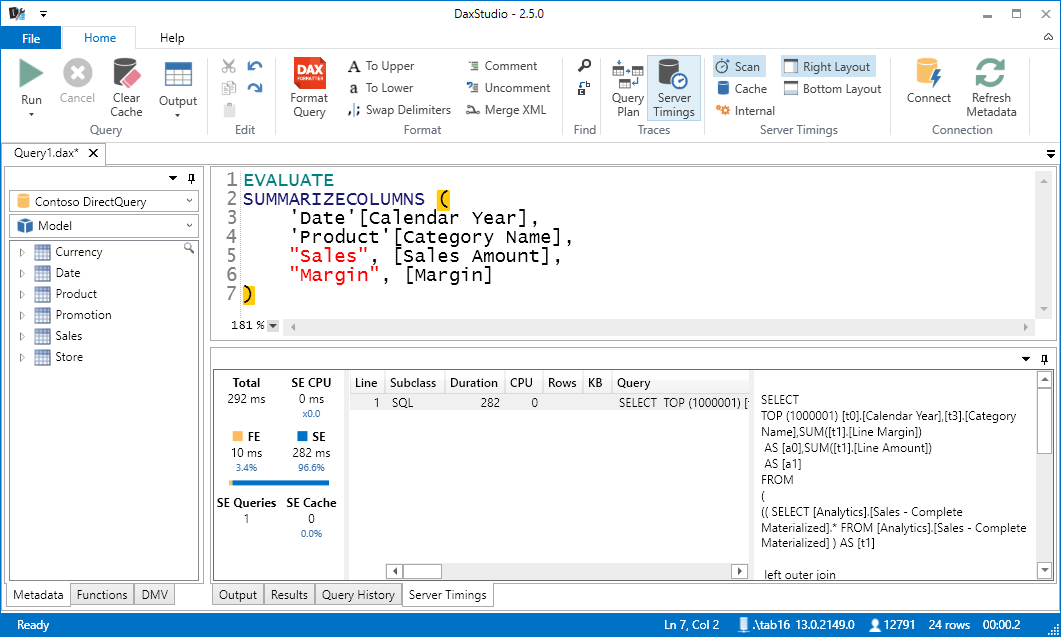
You can continue to optimize your DAX measures by using the same principles described in The Definitive Guide to Dax, you just have a different storage engine and you do not have the equivalent of the storage engine cache available in VertiPaq.
If you find a bottleneck in SQL Server, it is very quick to identify the slowest SQL query, which you can copy and execute straight on your relational database (for example using SQL Server Management Studio for SQL Server), looking for possible optimizations on that side.
Returns a table with new columns specified by the DAX expressions.
ADDCOLUMNS ( <Table>, <Name>, <Expression> [, <Name>, <Expression> [, … ] ] )
Creates a summary of the input table grouped by the specified columns.
SUMMARIZE ( <Table> [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] )
Create a summary table for the requested totals over set of groups.
SUMMARIZECOLUMNS ( [<GroupBy_ColumnName> [, [<FilterTable>] [, [<Name>] [, [<Expression>] [, <GroupBy_ColumnName> [, [<FilterTable>] [, [<Name>] [, [<Expression>] [, … ] ] ] ] ] ] ] ] ] )